 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualGR: Generative Retrieval with Long and Short-Term Interests Modeling
Nov 16, 2025In large-scale industrial recommendation systems, retrieval must produce high-quality candidates from massive corpora under strict latency. Recently, Generative Retrieval (GR) has emerged as a viable alternative to Embedding-Based Retrieval (EBR), which quantizes items into a finite token space and decodes candidates autoregressively, providing a scalable path that explicitly models target-history interactions via cross-attention. However, three challenges persist: 1) how to balance users' long-term and short-term interests , 2) noise interference when generating hierarchical semantic IDs (SIDs), 3) the absence of explicit modeling for negative feedback such as exposed items without clicks. To address these challenges, we propose DualGR, a generative retrieval framework that explicitly models dual horizons of user interests with selective activation. Specifically, DualGR utilizes Dual-Branch Long/Short-Term Router (DBR) to cover both stable preferences and transient intents by explicitly modeling users' long- and short-term behaviors. Meanwhile, Search-based SID Decoding (S2D) is presented to control context-induced noise and enhance computational efficiency by constraining candidate interactions to the current coarse (level-1) bucket during fine-grained (level-2/3) SID prediction. % also reinforcing intra-class consistency. Finally, we propose an Exposure-aware Next-Token Prediction Loss (ENTP-Loss) that treats "exposed-but-unclicked" items as hard negatives at level-1, enabling timely interest fade-out. On the large-scale Kuaishou short-video recommendation system, DualGR has achieved outstanding performance. Online A/B testing shows +0.527% video views and +0.432% watch time lifts, validating DualGR as a practical and effective paradigm for industrial generative retrieval.
SynEVO: A neuro-inspired spatiotemporal evolutional framework for cross-domain adaptation
May 21, 2025Discovering regularities from spatiotemporal systems can benefit various scientific and social planning. Current spatiotemporal learners usually train an independent model from a specific source data that leads to limited transferability among sources, where even correlated tasks requires new design and training. The key towards increasing cross-domain knowledge is to enable collective intelligence and model evolution. In this paper, inspired by neuroscience theories, we theoretically derive the increased information boundary via learning cross-domain collective intelligence and propose a Synaptic EVOlutional spatiotemporal network, SynEVO, where SynEVO breaks the model independence and enables cross-domain knowledge to be shared and aggregated. Specifically, we first re-order the sample groups to imitate the human curriculum learning, and devise two complementary learners, elastic common container and task-independent extractor to allow model growth and task-wise commonality and personality disentanglement. Then an adaptive dynamic coupler with a new difference metric determines whether the new sample group should be incorporated into common container to achieve model evolution under various domains. Experiments show that SynEVO improves the generalization capacity by at most 42% under cross-domain scenarios and SynEVO provides a paradigm of NeuroAI for knowledge transfer and adaptation.
Get Rid of Task Isolation: A Continuous Multi-task Spatio-Temporal Learning Framework
Oct 14, 2024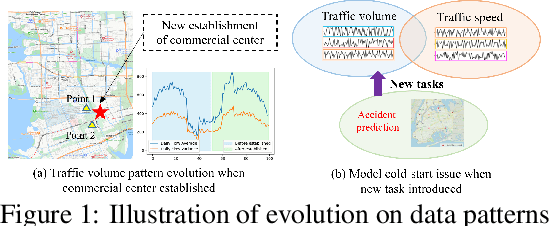
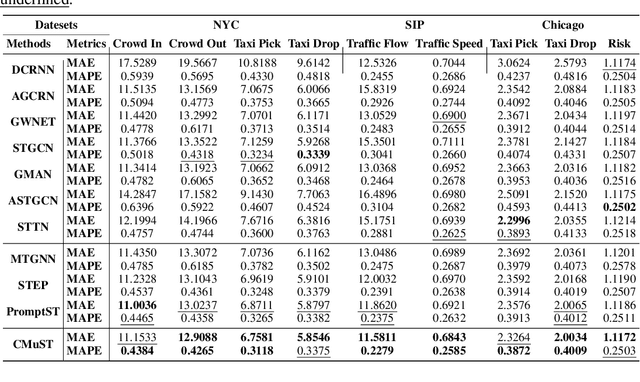


Spatiotemporal learning has become a pivotal technique to enable urban intelligence. Traditional spatiotemporal models mostly focus on a specific task by assuming a same distribution between training and testing sets. However, given that urban systems are usually dynamic, multi-sourced with imbalanced data distributions, current specific task-specific models fail to generalize to new urban conditions and adapt to new domains without explicitly modeling interdependencies across various dimensions and types of urban data. To this end, we argue that there is an essential to propose a Continuous Multi-task Spatio-Temporal learning framework (CMuST) to empower collective urban intelligence, which reforms the urban spatiotemporal learning from single-domain to cooperatively multi-dimensional and multi-task learning. Specifically, CMuST proposes a new multi-dimensional spatiotemporal interaction network (MSTI) to allow cross-interactions between context and main observations as well as self-interactions within spatial and temporal aspects to be exposed, which is also the core for capturing task-level commonality and personalization. To ensure continuous task learning, a novel Rolling Adaptation training scheme (RoAda) is devised, which not only preserves task uniqueness by constructing data summarization-driven task prompts, but also harnesses correlated patterns among tasks by iterative model behavior modeling. We further establish a benchmark of three cities for multi-task spatiotemporal learning, and empirically demonstrate the superiority of CMuST via extensive evaluations on these datasets. The impressive improvements on both few-shot streaming data and new domain tasks against existing SOAT methods are achieved. Code is available at https://github.com/DILab-USTCSZ/CMuST.
PriorNet: A Novel Lightweight Network with Multidimensional Interactive Attention for Efficient Image Dehazing
Apr 24, 2024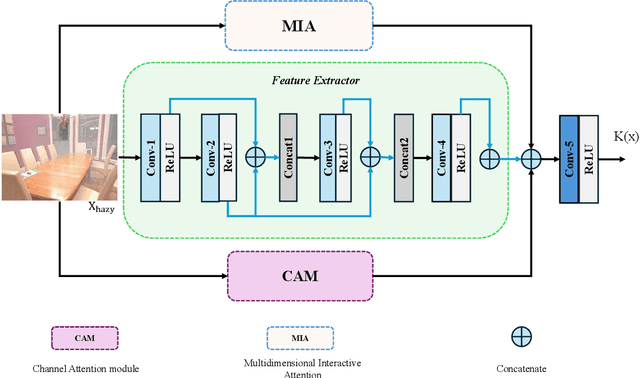
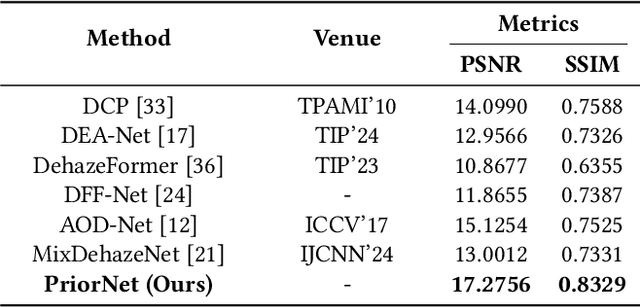
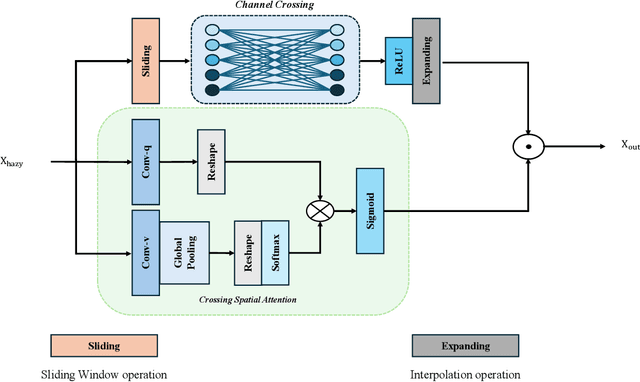

Hazy images degrade visual quality, and dehazing is a crucial prerequisite for subsequent processing tasks. Most current dehazing methods rely on neural networks and face challenges such as high computational parameter pressure and weak generalization capabilities. This paper introduces PriorNet--a novel, lightweight, and highly applicable dehazing network designed to significantly improve the clarity and visual quality of hazy images while avoiding excessive detail extraction issues. The core of PriorNet is the original Multi-Dimensional Interactive Attention (MIA) mechanism, which effectively captures a wide range of haze characteristics, substantially reducing the computational load and generalization difficulties associated with complex systems. By utilizing a uniform convolutional kernel size and incorporating skip connections, we have streamlined the feature extraction process. Simplifying the number of layers and architecture not only enhances dehazing efficiency but also facilitates easier deployment on edge devices. Extensive testing across multiple datasets has demonstrated PriorNet's exceptional performance in dehazing and clarity restoration, maintaining image detail and color fidelity in single-image dehazing tasks. Notably, with a model size of just 18Kb, PriorNet showcases superior dehazing generalization capabilities compared to other methods. Our research makes a significant contribution to advancing image dehazing technology, providing new perspectives and tools for the field and related domains, particularly emphasizing the importance of improving universality and deployability.