 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Indra Representation Hypothesis for Multimodal Alignment
Apr 06, 2026Recent studies have uncovered an interesting phenomenon: unimodal foundation models tend to learn convergent representations, regardless of differences in architecture, training objectives, or data modalities. However, these representations are essentially internal abstractions of samples that characterize samples independently, leading to limited expressiveness. In this paper, we propose The Indra Representation Hypothesis, inspired by the philosophical metaphor of Indra's Net. We argue that representations from unimodal foundation models are converging to implicitly reflect a shared relational structure underlying reality, akin to the relational ontology of Indra's Net. We formalize this hypothesis using the V-enriched Yoneda embedding from category theory, defining the Indra representation as a relational profile of each sample with respect to others. This formulation is shown to be unique, complete, and structure-preserving under a given cost function. We instantiate the Indra representation using angular distance and evaluate it in cross-model and cross-modal scenarios involving vision, language, and audio. Extensive experiments demonstrate that Indra representations consistently enhance robustness and alignment across architectures and modalities, providing a theoretically grounded and practical framework for training-free alignment of unimodal foundation models. Our code is available at https://github.com/Jianglin954/Indra.
Ref-Adv: Exploring MLLM Visual Reasoning in Referring Expression Tasks
Feb 27, 2026Referring Expression Comprehension (REC) links language to region level visual perception. Standard benchmarks (RefCOCO, RefCOCO+, RefCOCOg) have progressed rapidly with multimodal LLMs but remain weak tests of visual reasoning and grounding: (i) many expressions are very short, leaving little reasoning demand; (ii) images often contain few distractors, making the target easy to find; and (iii) redundant descriptors enable shortcut solutions that bypass genuine text understanding and visual reasoning. We introduce Ref-Adv, a modern REC benchmark that suppresses shortcuts by pairing linguistically nontrivial expressions with only the information necessary to uniquely identify the target. The dataset contains referring expressions on real images, curated with hard distractors and annotated with reasoning facets including negation. We conduct comprehensive ablations (word order perturbations and descriptor deletion sufficiency) to show that solving Ref-Adv requires reasoning beyond simple cues, and we evaluate a broad suite of contemporary multimodal LLMs on Ref-Adv. Despite strong results on RefCOCO, RefCOCO+, and RefCOCOg, models drop markedly on Ref-Adv, revealing reliance on shortcuts and gaps in visual reasoning and grounding. We provide an in depth failure analysis and aim for Ref-Adv to guide future work on visual reasoning and grounding in MLLMs.
QuiZSF: An efficient data-model interaction framework for zero-shot time-series forecasting
Aug 09, 2025Time series forecasting has become increasingly important to empower diverse applications with streaming data. Zero-shot time-series forecasting (ZSF), particularly valuable in data-scarce scenarios, such as domain transfer or forecasting under extreme conditions, is difficult for traditional models to deal with. While time series pre-trained models (TSPMs) have demonstrated strong performance in ZSF, they often lack mechanisms to dynamically incorporate external knowledge. Fortunately, emerging retrieval-augmented generation (RAG) offers a promising path for injecting such knowledge on demand, yet they are rarely integrated with TSPMs. To leverage the strengths of both worlds, we introduce RAG into TSPMs to enhance zero-shot time series forecasting. In this paper, we propose QuiZSF (Quick Zero-Shot Time Series Forecaster), a lightweight and modular framework that couples efficient retrieval with representation learning and model adaptation for ZSF. Specifically, we construct a hierarchical tree-structured ChronoRAG Base (CRB) for scalable time-series storage and domain-aware retrieval, introduce a Multi-grained Series Interaction Learner (MSIL) to extract fine- and coarse-grained relational features, and develop a dual-branch Model Cooperation Coherer (MCC) that aligns retrieved knowledge with two kinds of TSPMs: Non-LLM based and LLM based. Compared with contemporary baselines, QuiZSF, with Non-LLM based and LLM based TSPMs as base model, respectively, ranks Top1 in 75% and 87.5% of prediction settings, while maintaining high efficiency in memory and inference time.
MasHost Builds It All: Autonomous Multi-Agent System Directed by Reinforcement Learning
Jun 12, 2025Large Language Model (LLM)-driven Multi-agent systems (Mas) have recently emerged as a powerful paradigm for tackling complex real-world tasks. However, existing Mas construction methods typically rely on manually crafted interaction mechanisms or heuristic rules, introducing human biases and constraining the autonomous ability. Even with recent advances in adaptive Mas construction, existing systems largely remain within the paradigm of semi-autonomous patterns. In this work, we propose MasHost, a Reinforcement Learning (RL)-based framework for autonomous and query-adaptive Mas design. By formulating Mas construction as a graph search problem, our proposed MasHost jointly samples agent roles and their interactions through a unified probabilistic sampling mechanism. Beyond the accuracy and efficiency objectives pursued in prior works, we introduce component rationality as an additional and novel design principle in Mas. To achieve this multi-objective optimization, we propose Hierarchical Relative Policy Optimization (HRPO), a novel RL strategy that collaboratively integrates group-relative advantages and action-wise rewards. To our knowledge, our proposed MasHost is the first RL-driven framework for autonomous Mas graph construction. Extensive experiments on six benchmarks demonstrate that MasHost consistently outperforms most competitive baselines, validating its effectiveness, efficiency, and structure rationality.
Spatiotemporal Causal Decoupling Model for Air Quality Forecasting
May 26, 2025Due to the profound impact of air pollution on human health, livelihoods, and economic development, air quality forecasting is of paramount significance. Initially, we employ the causal graph method to scrutinize the constraints of existing research in comprehensively modeling the causal relationships between the air quality index (AQI) and meteorological features. In order to enhance prediction accuracy, we introduce a novel air quality forecasting model, AirCade, which incorporates a causal decoupling approach. AirCade leverages a spatiotemporal module in conjunction with knowledge embedding techniques to capture the internal dynamics of AQI. Subsequently, a causal decoupling module is proposed to disentangle synchronous causality from past AQI and meteorological features, followed by the dissemination of acquired knowledge to future time steps to enhance performance. Additionally, we introduce a causal intervention mechanism to explicitly represent the uncertainty of future meteorological features, thereby bolstering the model's robustness. Our evaluation of AirCade on an open-source air quality dataset demonstrates over 20\% relative improvement over state-of-the-art models.
SynEVO: A neuro-inspired spatiotemporal evolutional framework for cross-domain adaptation
May 21, 2025Discovering regularities from spatiotemporal systems can benefit various scientific and social planning. Current spatiotemporal learners usually train an independent model from a specific source data that leads to limited transferability among sources, where even correlated tasks requires new design and training. The key towards increasing cross-domain knowledge is to enable collective intelligence and model evolution. In this paper, inspired by neuroscience theories, we theoretically derive the increased information boundary via learning cross-domain collective intelligence and propose a Synaptic EVOlutional spatiotemporal network, SynEVO, where SynEVO breaks the model independence and enables cross-domain knowledge to be shared and aggregated. Specifically, we first re-order the sample groups to imitate the human curriculum learning, and devise two complementary learners, elastic common container and task-independent extractor to allow model growth and task-wise commonality and personality disentanglement. Then an adaptive dynamic coupler with a new difference metric determines whether the new sample group should be incorporated into common container to achieve model evolution under various domains. Experiments show that SynEVO improves the generalization capacity by at most 42% under cross-domain scenarios and SynEVO provides a paradigm of NeuroAI for knowledge transfer and adaptation.
Soft causal learning for generalized molecule property prediction: An environment perspective
May 07, 2025Learning on molecule graphs has become an increasingly important topic in AI for science, which takes full advantage of AI to facilitate scientific discovery. Existing solutions on modeling molecules utilize Graph Neural Networks (GNNs) to achieve representations but they mostly fail to adapt models to out-of-distribution (OOD) samples. Although recent advances on OOD-oriented graph learning have discovered the invariant rationale on graphs, they still ignore three important issues, i.e., 1) the expanding atom patterns regarding environments on graphs lead to failures of invariant rationale based models, 2) the associations between discovered molecular subgraphs and corresponding properties are complex where causal substructures cannot fully interpret the labels. 3) the interactions between environments and invariances can influence with each other thus are challenging to be modeled. To this end, we propose a soft causal learning framework, to tackle the unresolved OOD challenge in molecular science, from the perspective of fully modeling the molecule environments and bypassing the invariant subgraphs. Specifically, we first incorporate chemistry theories into our graph growth generator to imitate expaned environments, and then devise an GIB-based objective to disentangle environment from whole graphs and finally introduce a cross-attention based soft causal interaction, which allows dynamic interactions between environments and invariances. We perform experiments on seven datasets by imitating different kinds of OOD generalization scenarios. Extensive comparison, ablation experiments as well as visualized case studies demonstrate well generalization ability of our proposal.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024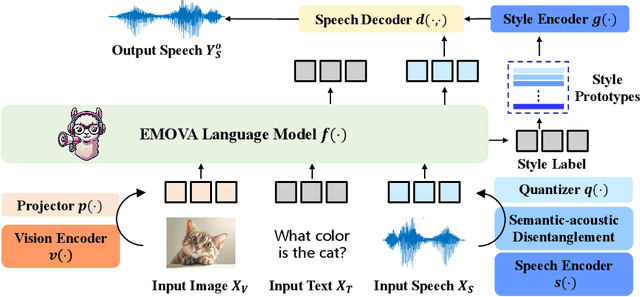
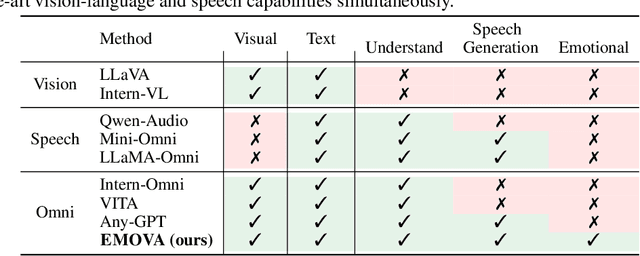
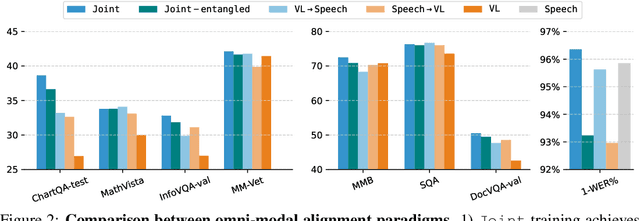

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
FairSTG: Countering performance heterogeneity via collaborative sample-level optimization
Mar 19, 2024Spatiotemporal learning plays a crucial role in mobile computing techniques to empower smart cites. While existing research has made great efforts to achieve accurate predictions on the overall dataset, they still neglect the significant performance heterogeneity across samples. In this work, we designate the performance heterogeneity as the reason for unfair spatiotemporal learning, which not only degrades the practical functions of models, but also brings serious potential risks to real-world urban applications. To fix this gap, we propose a model-independent Fairness-aware framework for SpatioTemporal Graph learning (FairSTG), which inherits the idea of exploiting advantages of well-learned samples to challenging ones with collaborative mix-up. Specifically, FairSTG consists of a spatiotemporal feature extractor for model initialization, a collaborative representation enhancement for knowledge transfer between well-learned samples and challenging ones, and fairness objectives for immediately suppressing sample-level performance heterogeneity. Experiments on four spatiotemporal datasets demonstrate that our FairSTG significantly improves the fairness quality while maintaining comparable forecasting accuracy. Case studies show FairSTG can counter both spatial and temporal performance heterogeneity by our sample-level retrieval and compensation, and our work can potentially alleviate the risks on spatiotemporal resource allocation for underrepresented urban regions.
ComS2T: A complementary spatiotemporal learning system for data-adaptive model evolution
Mar 04, 2024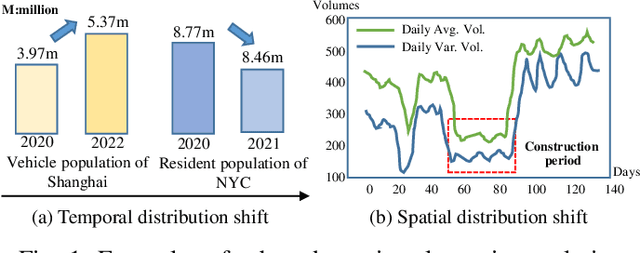
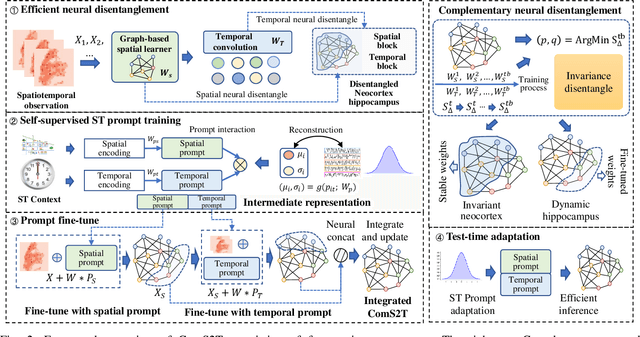
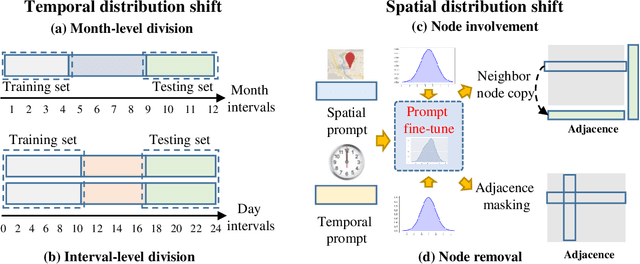
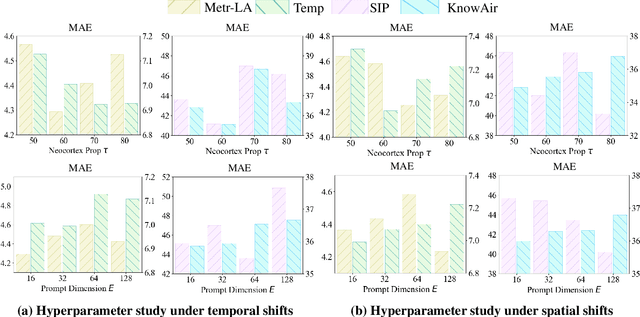
Spatiotemporal (ST) learning has become a crucial technique to enable smart cities and sustainable urban development. Current ST learning models capture the heterogeneity via various spatial convolution and temporal evolution blocks. However, rapid urbanization leads to fluctuating distributions in urban data and city structures over short periods, resulting in existing methods suffering generalization and data adaptation issues. Despite efforts, existing methods fail to deal with newly arrived observations and those methods with generalization capacity are limited in repeated training. Motivated by complementary learning in neuroscience, we introduce a prompt-based complementary spatiotemporal learning termed ComS2T, to empower the evolution of models for data adaptation. ComS2T partitions the neural architecture into a stable neocortex for consolidating historical memory and a dynamic hippocampus for new knowledge update. We first disentangle two disjoint structures into stable and dynamic weights, and then train spatial and temporal prompts by characterizing distribution of main observations to enable prompts adaptive to new data. This data-adaptive prompt mechanism, combined with a two-stage training process, facilitates fine-tuning of the neural architecture conditioned on prompts, thereby enabling efficient adaptation during testing. Extensive experiments validate the efficacy of ComS2T in adapting to various spatiotemporal out-of-distribution scenarios while maintaining efficient inference capabilities.