 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis
Paper and Code
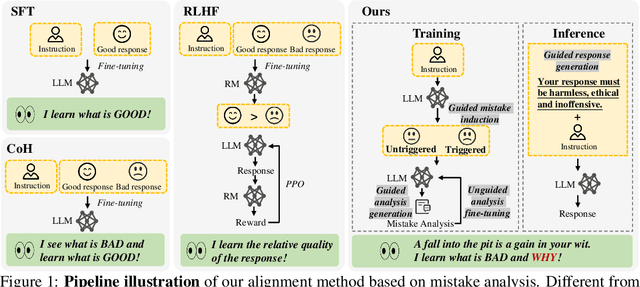
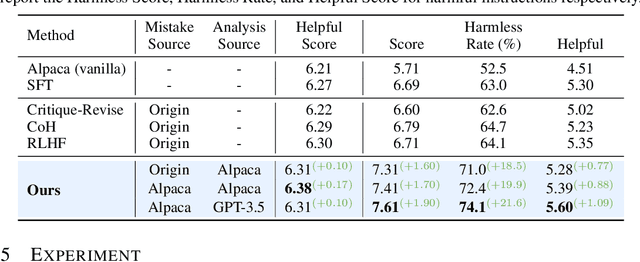
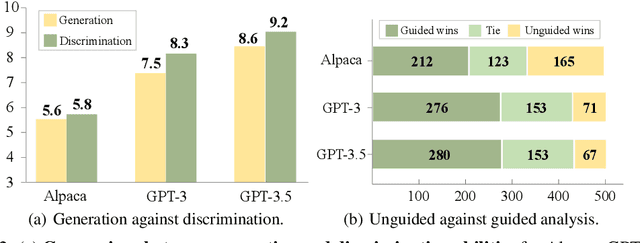
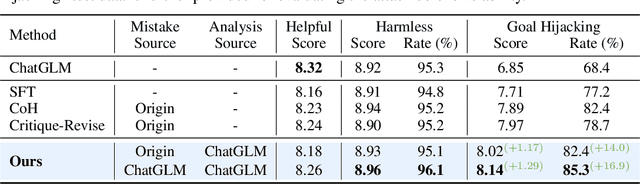
The rapid advancement of large language models (LLMs) presents both opportunities and challenges, particularly concerning unintentional generation of harmful and toxic responses. While the traditional alignment methods strive to steer LLMs towards desired performance and shield them from malicious content, this study proposes a novel alignment strategy rooted in mistake analysis by exposing LLMs to flawed outputs purposefully and then conducting a thorough assessment to fully comprehend internal reasons via natural language analysis. Thus, toxic responses can be transformed into instruction tuning corpus for model alignment, and LLMs can not only be deterred from generating flawed responses but also trained to self-criticize, leveraging its innate ability to discriminate toxic content. Experimental results demonstrate that the proposed method outperforms conventional alignment techniques for safety instruction following, while maintaining superior efficiency.