 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfMem: Learning System-2 Memory Control for Long-Context Agent
Feb 02, 2026Reasoning over ultra-long documents requires synthesizing sparse evidence scattered across distant segments under strict memory constraints. While streaming agents enable scalable processing, their passive memory update strategy often fails to preserve low-salience bridging evidence required for multi-hop reasoning. We propose InfMem, a control-centric agent that instantiates System-2-style control via a PreThink-Retrieve-Write protocol. InfMem actively monitors evidence sufficiency, performs targeted in-document retrieval, and applies evidence-aware joint compression to update a bounded memory. To ensure reliable control, we introduce a practical SFT-to-RL training recipe that aligns retrieval, writing, and stopping decisions with end-task correctness. On ultra-long QA benchmarks from 32k to 1M tokens, InfMem consistently outperforms MemAgent across backbones. Specifically, InfMem improves average absolute accuracy by +10.17, +11.84, and +8.23 points on Qwen3-1.7B, Qwen3-4B, and Qwen2.5-7B, respectively, while reducing inference time by $3.9\times$ on average (up to $5.1\times$) via adaptive early stopping.
Teaching Large Reasoning Models Effective Reflection
Jan 19, 2026Large Reasoning Models (LRMs) have recently shown impressive performance on complex reasoning tasks, often by engaging in self-reflective behaviors such as self-critique and backtracking. However, not all reflections are beneficial-many are superficial, offering little to no improvement over the original answer and incurring computation overhead. In this paper, we identify and address the problem of superficial reflection in LRMs. We first propose Self-Critique Fine-Tuning (SCFT), a training framework that enhances the model's reflective reasoning ability using only self-generated critiques. SCFT prompts models to critique their own outputs, filters high-quality critiques through rejection sampling, and fine-tunes the model using a critique-based objective. Building on this strong foundation, we further introduce Reinforcement Learning with Effective Reflection Rewards (RLERR). RLERR leverages the high-quality reflections initialized by SCFT to construct reward signals, guiding the model to internalize the self-correction process via reinforcement learning. Experiments on two challenging benchmarks, AIME2024 and AIME2025, show that SCFT and RLERR significantly improve both reasoning accuracy and reflection quality, outperforming state-of-the-art baselines. All data and codes are available at https://github.com/wanghanbinpanda/SCFT.
Group Pattern Selection Optimization: Let LRMs Pick the Right Pattern for Reasoning
Jan 12, 2026Large reasoning models (LRMs) exhibit diverse high-level reasoning patterns (e.g., direct solution, reflection-and-verification, and exploring multiple solutions), yet prevailing training recipes implicitly bias models toward a limited set of dominant patterns. Through a systematic analysis, we identify substantial accuracy variance across these patterns on mathematics and science benchmarks, revealing that a model's default reasoning pattern is often sub-optimal for a given problem. To address this, we introduce Group Pattern Selection Optimization (GPSO), a reinforcement learning framework that extends GRPO by incorporating multi-pattern rollouts, verifier-guided optimal pattern selection per problem, and attention masking during optimization to prevent the leakage of explicit pattern suffixes into the learned policy. By exploring a portfolio of diverse reasoning strategies and optimizing the policy on the most effective ones, GPSO enables the model to internalize the mapping from problem characteristics to optimal reasoning patterns. Extensive experiments demonstrate that GPSO delivers consistent and substantial performance gains across various model backbones and benchmarks, effectively mitigating pattern sub-optimality and fostering more robust, adaptable reasoning. All data and codes are available at https://github.com/wanghanbinpanda/GPSO.
Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents
Dec 23, 2025Temporal reasoning over long, multi-session dialogues is a critical capability for conversational agents. However, existing works and our pilot study have shown that as dialogue histories grow in length and accumulate noise, current long-context models struggle to accurately identify temporally pertinent information, significantly impairing reasoning performance. To address this, we introduce Memory-T1, a framework that learns a time-aware memory selection policy using reinforcement learning (RL). It employs a coarse-to-fine strategy, first pruning the dialogue history into a candidate set using temporal and relevance filters, followed by an RL agent that selects the precise evidence sessions. The RL training is guided by a multi-level reward function optimizing (i) answer accuracy, (ii) evidence grounding, and (iii) temporal consistency. In particular, the temporal consistency reward provides a dense signal by evaluating alignment with the query time scope at both the session-level (chronological proximity) and the utterance-level (chronological fidelity), enabling the agent to resolve subtle chronological ambiguities. On the Time-Dialog benchmark, Memory-T1 boosts a 7B model to an overall score of 67.0\%, establishing a new state-of-the-art performance for open-source models and outperforming a 14B baseline by 10.2\%. Ablation studies show temporal consistency and evidence grounding rewards jointly contribute to a 15.0\% performance gain. Moreover, Memory-T1 maintains robustness up to 128k tokens, where baseline models collapse, proving effectiveness against noise in extensive dialogue histories. The code and datasets are publicly available at https://github.com/Elvin-Yiming-Du/Memory-T1/
Rethinking Expert Trajectory Utilization in LLM Post-training
Dec 12, 2025While effective post-training integrates Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), the optimal mechanism for utilizing expert trajectories remains unresolved. We propose the Plasticity-Ceiling Framework to theoretically ground this landscape, decomposing performance into foundational SFT performance and the subsequent RL plasticity. Through extensive benchmarking, we establish the Sequential SFT-then-RL pipeline as the superior standard, overcoming the stability deficits of synchronized approaches. Furthermore, we derive precise scaling guidelines: (1) Transitioning to RL at the SFT Stable or Mild Overfitting Sub-phase maximizes the final ceiling by securing foundational SFT performance without compromising RL plasticity; (2) Refuting ``Less is More'' in the context of SFT-then-RL scaling, we demonstrate that Data Scale determines the primary post-training potential, while Trajectory Difficulty acts as a performance multiplier; and (3) Identifying that the Minimum SFT Validation Loss serves as a robust indicator for selecting the expert trajectories that maximize the final performance ceiling. Our findings provide actionable guidelines for maximizing the value extracted from expert trajectories.
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025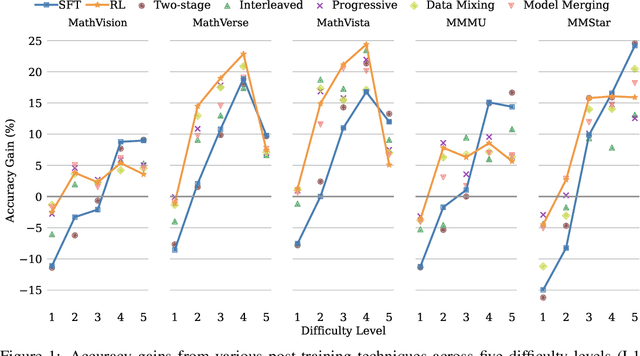
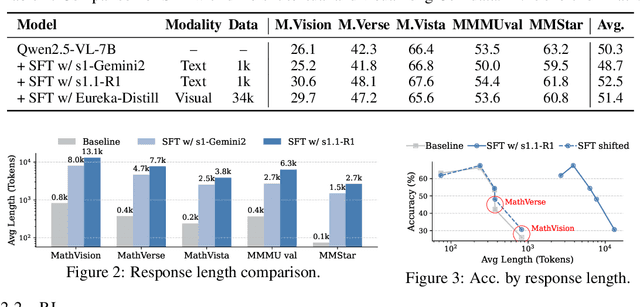
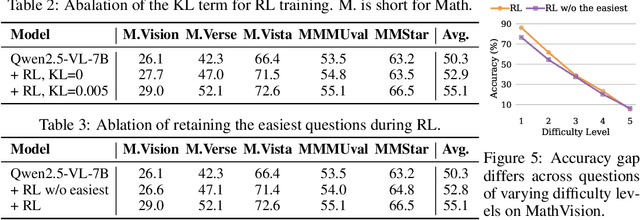
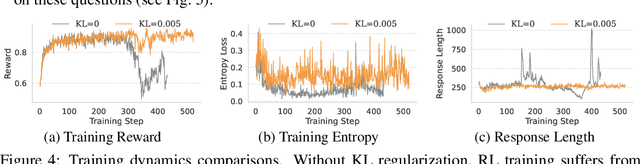
Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
ClusterUCB: Efficient Gradient-Based Data Selection for Targeted Fine-Tuning of LLMs
Jun 12, 2025Gradient-based data influence approximation has been leveraged to select useful data samples in the supervised fine-tuning of large language models. However, the computation of gradients throughout the fine-tuning process requires too many resources to be feasible in practice. In this paper, we propose an efficient gradient-based data selection framework with clustering and a modified Upper Confidence Bound (UCB) algorithm. Based on the intuition that data samples with similar gradient features will have similar influences, we first perform clustering on the training data pool. Then, we frame the inter-cluster data selection as a constrained computing budget allocation problem and consider it a multi-armed bandit problem. A modified UCB algorithm is leveraged to solve this problem. Specifically, during the iterative sampling process, historical data influence information is recorded to directly estimate the distributions of each cluster, and a cold start is adopted to balance exploration and exploitation. Experimental results on various benchmarks show that our proposed framework, ClusterUCB, can achieve comparable results to the original gradient-based data selection methods while greatly reducing computing consumption.
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025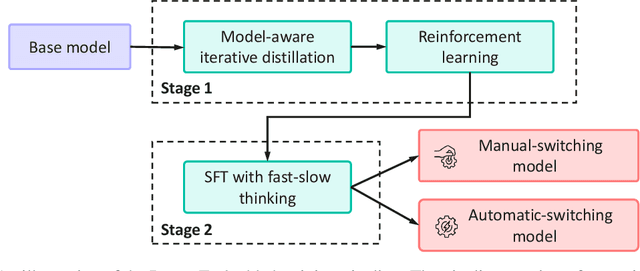

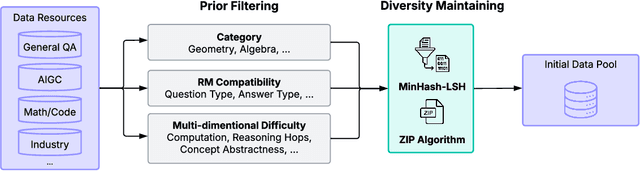
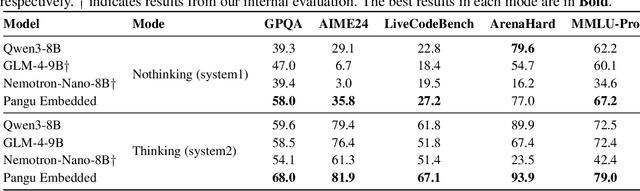
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
Self-Error-Instruct: Generalizing from Errors for LLMs Mathematical Reasoning
May 28, 2025
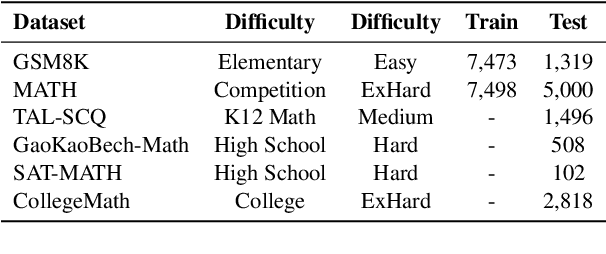

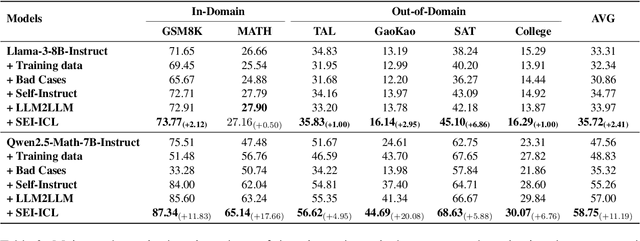
Although large language models demonstrate strong performance across various domains, they still struggle with numerous bad cases in mathematical reasoning. Previous approaches to learning from errors synthesize training data by solely extrapolating from isolated bad cases, thereby failing to generalize the extensive patterns inherent within these cases. This paper presents Self-Error-Instruct (SEI), a framework that addresses these model weaknesses and synthesizes more generalized targeted training data. Specifically, we explore a target model on two mathematical datasets, GSM8K and MATH, to pinpoint bad cases. Then, we generate error keyphrases for these cases based on the instructor model's (GPT-4o) analysis and identify error types by clustering these keyphrases. Next, we sample a few bad cases during each generation for each identified error type and input them into the instructor model, which synthesizes additional training data using a self-instruct approach. This new data is refined through a one-shot learning process to ensure that only the most effective examples are kept. Finally, we use these curated data to fine-tune the target model, iteratively repeating the process to enhance performance. We apply our framework to various models and observe improvements in their reasoning abilities across both in-domain and out-of-domain mathematics datasets. These results demonstrate the effectiveness of self-error instruction in improving LLMs' mathematical reasoning through error generalization.