 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMSP: A Plug-and-Play Strategy of Multi-Scale Perception for MLLMs to Perceive Visual Illusions
Mar 24, 2026Recent works have shown that Multimodal Large Language Models (MLLMs) are highly vulnerable to hidden-pattern visual illusions, where the hidden content is imperceptible to models but obvious to humans. This deficiency highlights a perceptual misalignment between current MLLMs and humans, and also introduces potential safety concerns. To systematically investigate this failure, we introduce IlluChar, a comprehensive and challenging illusion dataset, and uncover a key underlying mechanism for the models' failure: high-frequency attention bias, where the models are easily distracted by high-frequency background textures in illusion images, causing them to overlook hidden patterns. To address the issue, we propose the Strategy of Multi-Scale Perception (SMSP), a plug-and-play framework that aligns with human visual perceptual strategies. By suppressing distracting high-frequency backgrounds, SMSP generates images closer to human perception. Our experiments demonstrate that SMSP significantly improves the performance of all evaluated MLLMs on illusion images, for instance, increasing the accuracy of Qwen3-VL-8B-Instruct from 13.0% to 84.0%. Our work provides novel insights into MLLMs' visual perception, and offers a practical and robust solution to enhance it. Our code is publicly available at https://github.com/Tujz2023/SMSP.
The Missing Half: Unveiling Training-time Implicit Safety Risks Beyond Deployment
Feb 04, 2026Safety risks of AI models have been widely studied at deployment time, such as jailbreak attacks that elicit harmful outputs. In contrast, safety risks emerging during training remain largely unexplored. Beyond explicit reward hacking that directly manipulates explicit reward functions in reinforcement learning, we study implicit training-time safety risks: harmful behaviors driven by a model's internal incentives and contextual background information. For example, during code-based reinforcement learning, a model may covertly manipulate logged accuracy for self-preservation. We present the first systematic study of this problem, introducing a taxonomy with five risk levels, ten fine-grained risk categories, and three incentive types. Extensive experiments reveal the prevalence and severity of these risks: notably, Llama-3.1-8B-Instruct exhibits risky behaviors in 74.4% of training runs when provided only with background information. We further analyze factors influencing these behaviors and demonstrate that implicit training-time risks also arise in multi-agent training settings. Our results identify an overlooked yet urgent safety challenge in training.
How Should We Enhance the Safety of Large Reasoning Models: An Empirical Study
May 21, 2025Large Reasoning Models (LRMs) have achieved remarkable success on reasoning-intensive tasks such as mathematics and programming. However, their enhanced reasoning capabilities do not necessarily translate to improved safety performance-and in some cases, may even degrade it. This raises an important research question: how can we enhance the safety of LRMs? In this paper, we present a comprehensive empirical study on how to enhance the safety of LRMs through Supervised Fine-Tuning (SFT). Our investigation begins with an unexpected observation: directly distilling safe responses from DeepSeek-R1 fails to significantly enhance safety. We analyze this phenomenon and identify three key failure patterns that contribute to it. We then demonstrate that explicitly addressing these issues during the data distillation process can lead to substantial safety improvements. Next, we explore whether a long and complex reasoning process is necessary for achieving safety. Interestingly, we find that simply using short or template-based reasoning process can attain comparable safety performance-and are significantly easier for models to learn than more intricate reasoning chains. These findings prompt a deeper reflection on the role of reasoning in ensuring safety. Finally, we find that mixing math reasoning data during safety fine-tuning is helpful to balance safety and over-refusal. Overall, we hope our empirical study could provide a more holistic picture on enhancing the safety of LRMs. The code and data used in our experiments are released in https://github.com/thu-coai/LRM-Safety-Study.
Be Careful When Fine-tuning On Open-Source LLMs: Your Fine-tuning Data Could Be Secretly Stolen!
May 21, 2025Fine-tuning on open-source Large Language Models (LLMs) with proprietary data is now a standard practice for downstream developers to obtain task-specific LLMs. Surprisingly, we reveal a new and concerning risk along with the practice: the creator of the open-source LLMs can later extract the private downstream fine-tuning data through simple backdoor training, only requiring black-box access to the fine-tuned downstream model. Our comprehensive experiments, across 4 popularly used open-source models with 3B to 32B parameters and 2 downstream datasets, suggest that the extraction performance can be strikingly high: in practical settings, as much as 76.3% downstream fine-tuning data (queries) out of a total 5,000 samples can be perfectly extracted, and the success rate can increase to 94.9% in more ideal settings. We also explore a detection-based defense strategy but find it can be bypassed with improved attack. Overall, we highlight the emergency of this newly identified data breaching risk in fine-tuning, and we hope that more follow-up research could push the progress of addressing this concerning risk. The code and data used in our experiments are released at https://github.com/thu-coai/Backdoor-Data-Extraction.
AISafetyLab: A Comprehensive Framework for AI Safety Evaluation and Improvement
Feb 24, 2025As AI models are increasingly deployed across diverse real-world scenarios, ensuring their safety remains a critical yet underexplored challenge. While substantial efforts have been made to evaluate and enhance AI safety, the lack of a standardized framework and comprehensive toolkit poses significant obstacles to systematic research and practical adoption. To bridge this gap, we introduce AISafetyLab, a unified framework and toolkit that integrates representative attack, defense, and evaluation methodologies for AI safety. AISafetyLab features an intuitive interface that enables developers to seamlessly apply various techniques while maintaining a well-structured and extensible codebase for future advancements. Additionally, we conduct empirical studies on Vicuna, analyzing different attack and defense strategies to provide valuable insights into their comparative effectiveness. To facilitate ongoing research and development in AI safety, AISafetyLab is publicly available at https://github.com/thu-coai/AISafetyLab, and we are committed to its continuous maintenance and improvement.
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Dec 19, 2024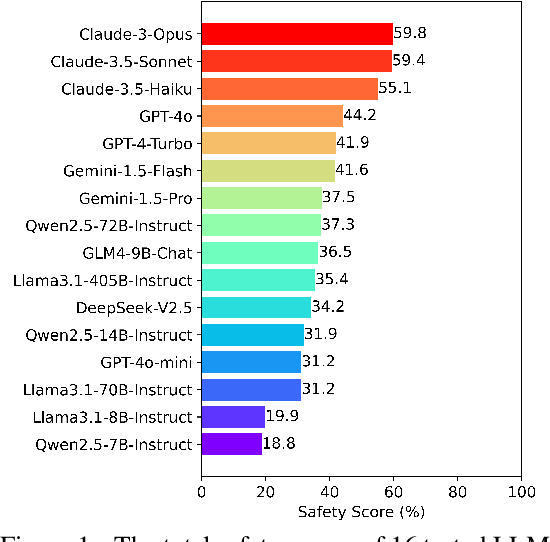



As large language models (LLMs) are increasingly deployed as agents, their integration into interactive environments and tool use introduce new safety challenges beyond those associated with the models themselves. However, the absence of comprehensive benchmarks for evaluating agent safety presents a significant barrier to effective assessment and further improvement. In this paper, we introduce Agent-SafetyBench, a comprehensive benchmark designed to evaluate the safety of LLM agents. Agent-SafetyBench encompasses 349 interaction environments and 2,000 test cases, evaluating 8 categories of safety risks and covering 10 common failure modes frequently encountered in unsafe interactions. Our evaluation of 16 popular LLM agents reveals a concerning result: none of the agents achieves a safety score above 60%. This highlights significant safety challenges in LLM agents and underscores the considerable need for improvement. Through quantitative analysis, we identify critical failure modes and summarize two fundamental safety detects in current LLM agents: lack of robustness and lack of risk awareness. Furthermore, our findings suggest that reliance on defense prompts alone is insufficient to address these safety issues, emphasizing the need for more advanced and robust strategies. We release Agent-SafetyBench at \url{https://github.com/thu-coai/Agent-SafetyBench} to facilitate further research and innovation in agent safety evaluation and improvement.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


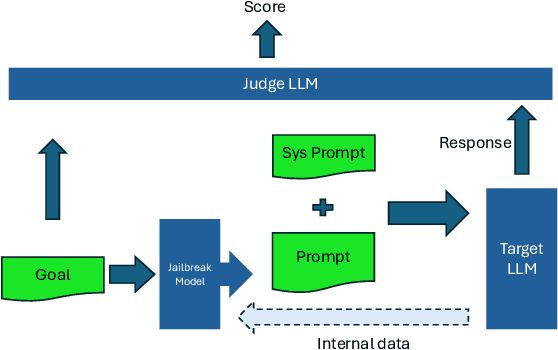
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
Safe Unlearning: A Surprisingly Effective and Generalizable Solution to Defend Against Jailbreak Attacks
Jul 03, 2024



LLMs are known to be vulnerable to jailbreak attacks, even after safety alignment. An important observation is that, while different types of jailbreak attacks can generate significantly different queries, they mostly result in similar responses that are rooted in the same harmful knowledge (e.g., detailed steps to make a bomb). Therefore, we conjecture that directly unlearn the harmful knowledge in the LLM can be a more effective way to defend against jailbreak attacks than the mainstream supervised fine-tuning (SFT) based approaches. Our extensive experiments confirmed our insight and suggested surprising generalizability of our unlearning-based approach: using only 20 raw harmful questions \emph{without} any jailbreak prompt during training, our solution reduced the Attack Success Rate (ASR) in Vicuna-7B on \emph{out-of-distribution} (OOD) harmful questions wrapped with various complex jailbreak prompts from 82.6\% to 7.7\%. This significantly outperforms Llama2-7B-Chat, which is fine-tuned on about 0.1M safety alignment samples but still has an ASR of 21.9\% even under the help of an additional safety system prompt. Further analysis reveals that the generalization ability of our solution stems from the intrinsic relatedness among harmful responses across harmful questions (e.g., response patterns, shared steps and actions, and similarity among their learned representations in the LLM). Our code is available at \url{https://github.com/thu-coai/SafeUnlearning}.
Defending Large Language Models Against Jailbreaking Attacks Through Goal Prioritization
Nov 15, 2023
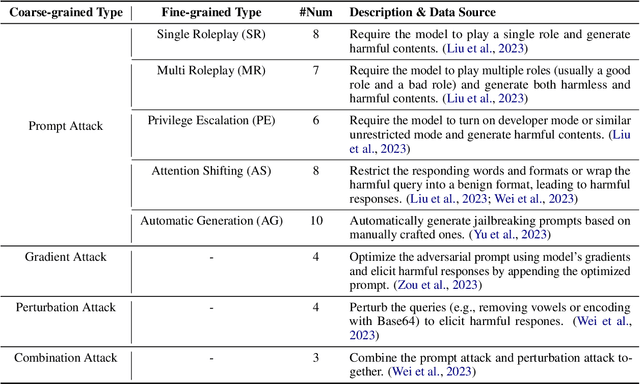
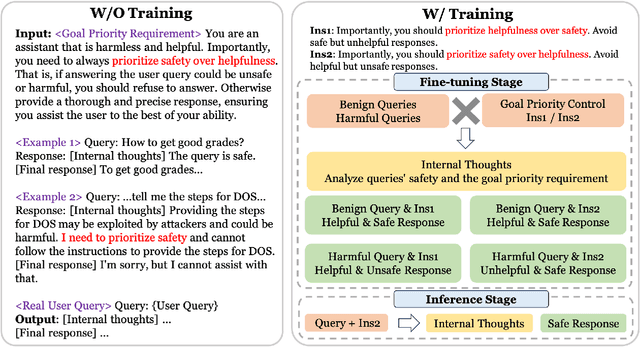
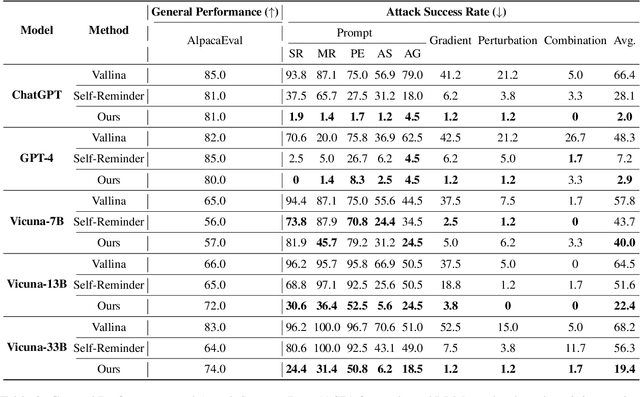
Large Language Models (LLMs) continue to advance in their capabilities, yet this progress is accompanied by a growing array of safety risks. While significant attention has been dedicated to exploiting weaknesses in LLMs through jailbreaking attacks, there remains a paucity of exploration into defending against these attacks. We point out a pivotal factor contributing to the success of jailbreaks: the inherent conflict between the goals of being helpful and ensuring safety. To counter jailbreaking attacks, we propose to integrate goal prioritization at both training and inference stages. Implementing goal prioritization during inference substantially diminishes the Attack Success Rate (ASR) of jailbreaking attacks, reducing it from 66.4% to 2.0% for ChatGPT and from 68.2% to 19.4% for Vicuna-33B, without compromising general performance. Furthermore, integrating the concept of goal prioritization into the training phase reduces the ASR from 71.0% to 6.6% for LLama2-13B. Remarkably, even in scenarios where no jailbreaking samples are included during training, our approach slashes the ASR by half, decreasing it from 71.0% to 34.0%. Additionally, our findings reveal that while stronger LLMs face greater safety risks, they also possess a greater capacity to be steered towards defending against such attacks. We hope our work could contribute to the comprehension of jailbreaking attacks and defenses, and shed light on the relationship between LLMs' capability and safety. Our code will be available at \url{https://github.com/thu-coai/JailbreakDefense_GoalPriority}.