 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBACE-RUL: A Bi-directional Adversarial Network with Covariate Encoding for Machine Remaining Useful Life Prediction
Mar 14, 2025Prognostic and Health Management (PHM) are crucial ways to avoid unnecessary maintenance for Cyber-Physical Systems (CPS) and improve system reliability. Predicting the Remaining Useful Life (RUL) is one of the most challenging tasks for PHM. Existing methods require prior knowledge about the system, contrived assumptions, or temporal mining to model the life cycles of machine equipment/devices, resulting in diminished accuracy and limited applicability in real-world scenarios. This paper proposes a Bi-directional Adversarial network with Covariate Encoding for machine Remaining Useful Life (BACE-RUL) prediction, which only adopts sensor measurements from the current life cycle to predict RUL rather than relying on previous consecutive cycle recordings. The current sensor measurements of mechanical devices are encoded to a conditional space to better understand the implicit inner mechanical status. The predictor is trained as a conditional generative network with the encoded sensor measurements as its conditions. Various experiments on several real-world datasets, including the turbofan aircraft engine dataset and the dataset collected from degradation experiments of Li-Ion battery cells, show that the proposed model is a general framework and outperforms state-of-the-art methods.
DUPRE: Data Utility Prediction for Efficient Data Valuation
Feb 22, 2025Data valuation is increasingly used in machine learning (ML) to decide the fair compensation for data owners and identify valuable or harmful data for improving ML models. Cooperative game theory-based data valuation, such as Data Shapley, requires evaluating the data utility (e.g., validation accuracy) and retraining the ML model for multiple data subsets. While most existing works on efficient estimation of the Shapley values have focused on reducing the number of subsets to evaluate, our framework, \texttt{DUPRE}, takes an alternative yet complementary approach that reduces the cost per subset evaluation by predicting data utilities instead of evaluating them by model retraining. Specifically, given the evaluated data utilities of some data subsets, \texttt{DUPRE} fits a \emph{Gaussian process} (GP) regression model to predict the utility of every other data subset. Our key contribution lies in the design of our GP kernel based on the sliced Wasserstein distance between empirical data distributions. In particular, we show that the kernel is valid and positive semi-definite, encodes prior knowledge of similarities between different data subsets, and can be efficiently computed. We empirically verify that \texttt{DUPRE} introduces low prediction error and speeds up data valuation for various ML models, datasets, and utility functions.
Spatio-Temporal Foundation Models: Vision, Challenges, and Opportunities
Jan 15, 2025Foundation models have revolutionized artificial intelligence, setting new benchmarks in performance and enabling transformative capabilities across a wide range of vision and language tasks. However, despite the prevalence of spatio-temporal data in critical domains such as transportation, public health, and environmental monitoring, spatio-temporal foundation models (STFMs) have not yet achieved comparable success. In this paper, we articulate a vision for the future of STFMs, outlining their essential characteristics and the generalization capabilities necessary for broad applicability. We critically assess the current state of research, identifying gaps relative to these ideal traits, and highlight key challenges that impede their progress. Finally, we explore potential opportunities and directions to advance research towards the aim of effective and broadly applicable STFMs.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


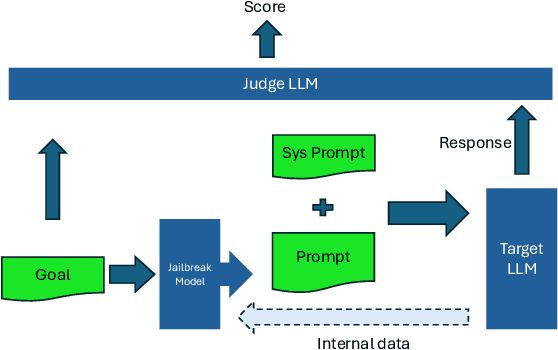
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Apr 29, 2024Vision-language pre-training has significantly elevated performance across a wide range of image-language applications. Yet, the pre-training process for video-related tasks demands exceptionally large computational and data resources, which hinders the progress of video-language models. This paper investigates a straight-forward, highly efficient, and resource-light approach to adapting an existing image-language pre-trained model for dense video understanding. Our preliminary experiments reveal that directly fine-tuning pre-trained image-language models with multiple frames as inputs on video datasets leads to performance saturation or even a drop. Our further investigation reveals that it is largely attributed to the bias of learned high-norm visual features. Motivated by this finding, we propose a simple but effective pooling strategy to smooth the feature distribution along the temporal dimension and thus reduce the dominant impacts from the extreme features. The new model is termed Pooling LLaVA, or PLLaVA in short. PLLaVA achieves new state-of-the-art performance on modern benchmark datasets for both video question-answer and captioning tasks. Notably, on the recent popular VideoChatGPT benchmark, PLLaVA achieves a score of 3.48 out of 5 on average of five evaluated dimensions, exceeding the previous SOTA results from GPT4V (IG-VLM) by 9%. On the latest multi-choice benchmark MVBench, PLLaVA achieves 58.1% accuracy on average across 20 sub-tasks, 14.5% higher than GPT4V (IG-VLM). Code is available at https://pllava.github.io/
MAgIC: Investigation of Large Language Model Powered Multi-Agent in Cognition, Adaptability, Rationality and Collaboration
Nov 16, 2023



Large Language Models (LLMs) have marked a significant advancement in the field of natural language processing, demonstrating exceptional capabilities in reasoning, tool usage, and memory. As their applications extend into multi-agent environments, a need has arisen for a comprehensive evaluation framework that captures their abilities in reasoning, planning, collaboration, and more. This work introduces a novel benchmarking framework specifically tailored to assess LLMs within multi-agent settings, providing quantitative metrics to evaluate their judgment, reasoning, deception, self-awareness, cooperation, coordination, and rationality. We utilize games such as Chameleon and Undercover, alongside game theory scenarios like Cost Sharing, Multi-player Prisoner's Dilemma, and Public Good, to create diverse testing environments. Our framework is fortified with the Probabilistic Graphical Modeling (PGM) method, enhancing the LLMs' capabilities in navigating complex social and cognitive dimensions. The benchmark evaluates seven multi-agent systems powered by different LLMs, quantitatively highlighting a significant capability gap over threefold between the strongest, GPT-4, and the weakest, Llama-2-70B. It also confirms that our PGM enhancement boosts the inherent abilities of all selected models by 50% on average. Our codes are released here https://github.com/cathyxl/MAgIC.
ARES: Locally Adaptive Reconstruction-based Anomaly Scoring
Jun 15, 2022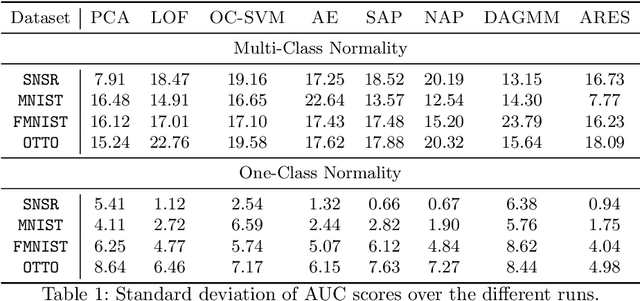
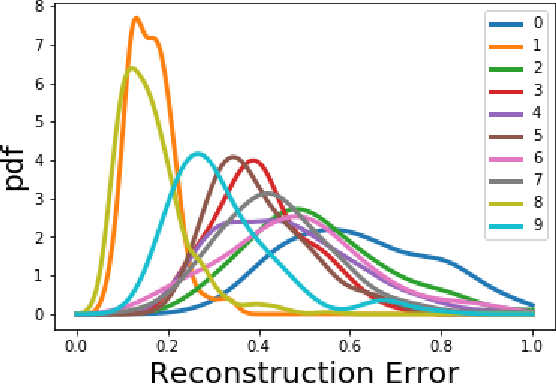
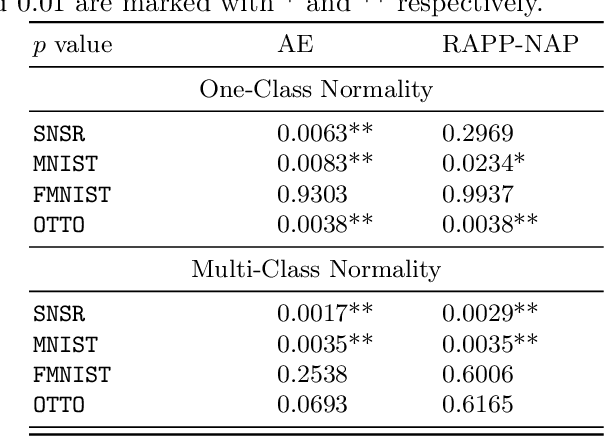
How can we detect anomalies: that is, samples that significantly differ from a given set of high-dimensional data, such as images or sensor data? This is a practical problem with numerous applications and is also relevant to the goal of making learning algorithms more robust to unexpected inputs. Autoencoders are a popular approach, partly due to their simplicity and their ability to perform dimension reduction. However, the anomaly scoring function is not adaptive to the natural variation in reconstruction error across the range of normal samples, which hinders their ability to detect real anomalies. In this paper, we empirically demonstrate the importance of local adaptivity for anomaly scoring in experiments with real data. We then propose our novel Adaptive Reconstruction Error-based Scoring approach, which adapts its scoring based on the local behaviour of reconstruction error over the latent space. We show that this improves anomaly detection performance over relevant baselines in a wide variety of benchmark datasets.
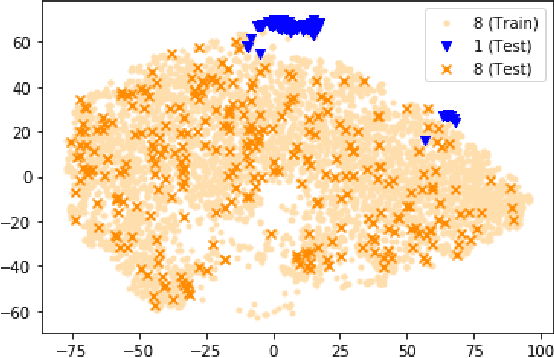
SparGE: Sparse Coding-based Patient Similarity Learning via Low-rank Constraints and Graph Embedding
Feb 03, 2022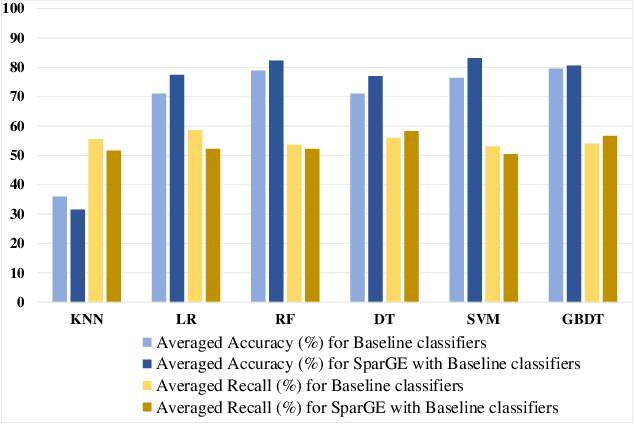

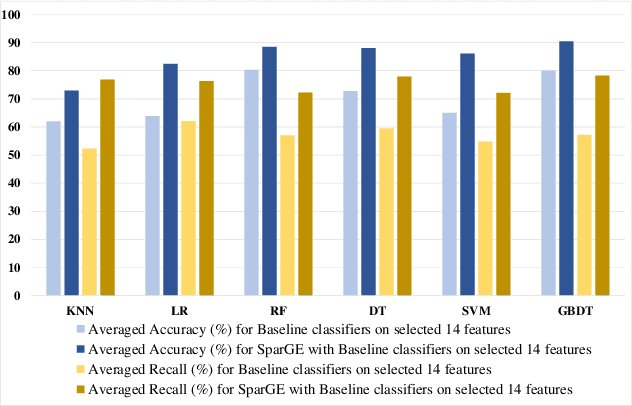

Patient similarity assessment (PSA) is pivotal to evidence-based and personalized medicine, enabled by analyzing the increasingly available electronic health records (EHRs). However, machine learning approaches for PSA has to deal with inherent data deficiencies of EHRs, namely missing values, noise, and small sample sizes. In this work, an end-to-end discriminative learning framework, called SparGE, is proposed to address these data challenges of EHR for PSA. SparGE measures similarity by jointly sparse coding and graph embedding. First, we use low-rank constrained sparse coding to identify and calculate weight for similar patients, while denoising against missing values. Then, graph embedding on sparse representations is adopted to measure the similarity between patient pairs via preserving local relationships defined by distances. Finally, a global cost function is constructed to optimize related parameters. Experimental results on two private and public real-world healthcare datasets, namely SingHEART and MIMIC-III, show that the proposed SparGE significantly outperforms other machine learning patient similarity methods.
LUNAR: Unifying Local Outlier Detection Methods via Graph Neural Networks
Dec 10, 2021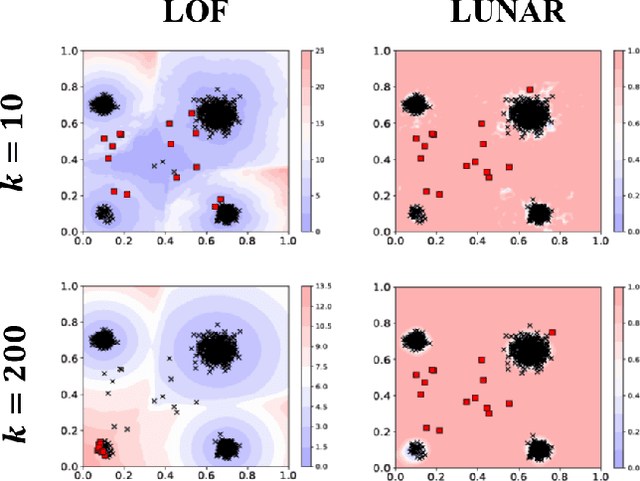
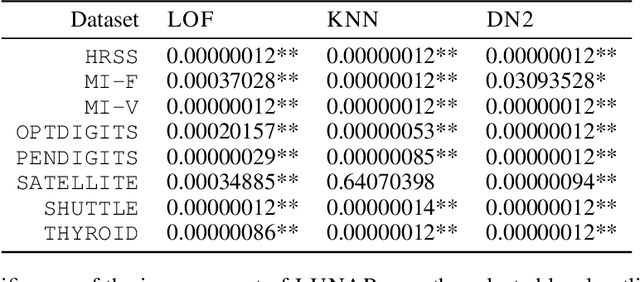
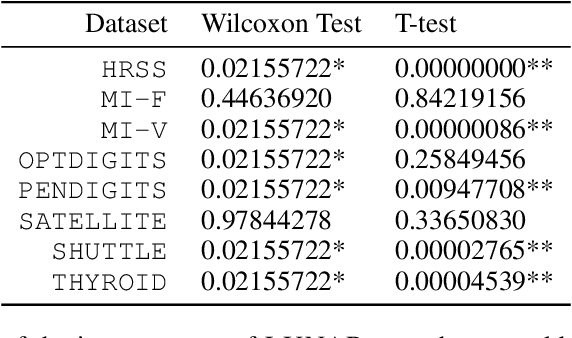
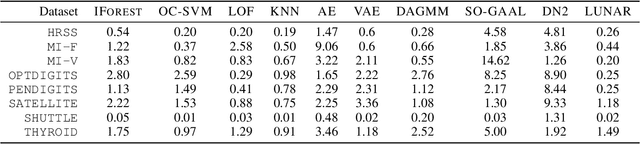
Many well-established anomaly detection methods use the distance of a sample to those in its local neighbourhood: so-called `local outlier methods', such as LOF and DBSCAN. They are popular for their simple principles and strong performance on unstructured, feature-based data that is commonplace in many practical applications. However, they cannot learn to adapt for a particular set of data due to their lack of trainable parameters. In this paper, we begin by unifying local outlier methods by showing that they are particular cases of the more general message passing framework used in graph neural networks. This allows us to introduce learnability into local outlier methods, in the form of a neural network, for greater flexibility and expressivity: specifically, we propose LUNAR, a novel, graph neural network-based anomaly detection method. LUNAR learns to use information from the nearest neighbours of each node in a trainable way to find anomalies. We show that our method performs significantly better than existing local outlier methods, as well as state-of-the-art deep baselines. We also show that the performance of our method is much more robust to different settings of the local neighbourhood size.