 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Foundation Models: Vision, Challenges, and Opportunities
Jan 15, 2025Foundation models have revolutionized artificial intelligence, setting new benchmarks in performance and enabling transformative capabilities across a wide range of vision and language tasks. However, despite the prevalence of spatio-temporal data in critical domains such as transportation, public health, and environmental monitoring, spatio-temporal foundation models (STFMs) have not yet achieved comparable success. In this paper, we articulate a vision for the future of STFMs, outlining their essential characteristics and the generalization capabilities necessary for broad applicability. We critically assess the current state of research, identifying gaps relative to these ideal traits, and highlight key challenges that impede their progress. Finally, we explore potential opportunities and directions to advance research towards the aim of effective and broadly applicable STFMs.
Efficient and Context-Aware Label Propagation for Zero-/Few-Shot Training-Free Adaptation of Vision-Language Model
Dec 24, 2024Vision-language models (VLMs) have revolutionized machine learning by leveraging large pre-trained models to tackle various downstream tasks. Despite improvements in label, training, and data efficiency, many state-of-the-art VLMs still require task-specific hyperparameter tuning and fail to fully exploit test samples. To overcome these challenges, we propose a graph-based approach for label-efficient adaptation and inference. Our method dynamically constructs a graph over text prompts, few-shot examples, and test samples, using label propagation for inference without task-specific tuning. Unlike existing zero-shot label propagation techniques, our approach requires no additional unlabeled support set and effectively leverages the test sample manifold through dynamic graph expansion. We further introduce a context-aware feature re-weighting mechanism to improve task adaptation accuracy. Additionally, our method supports efficient graph expansion, enabling real-time inductive inference. Extensive evaluations on downstream tasks, such as fine-grained categorization and out-of-distribution generalization, demonstrate the effectiveness of our approach.
When Text and Images Don't Mix: Bias-Correcting Language-Image Similarity Scores for Anomaly Detection
Jul 24, 2024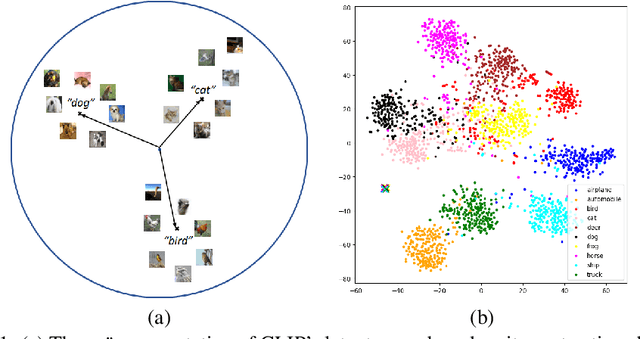
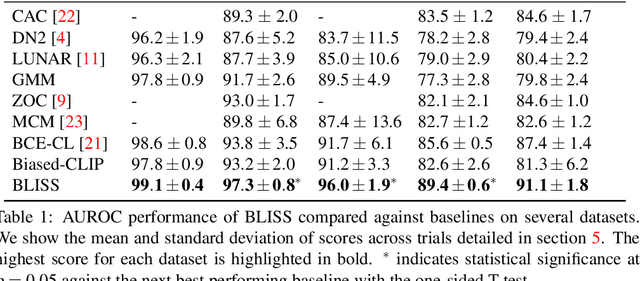
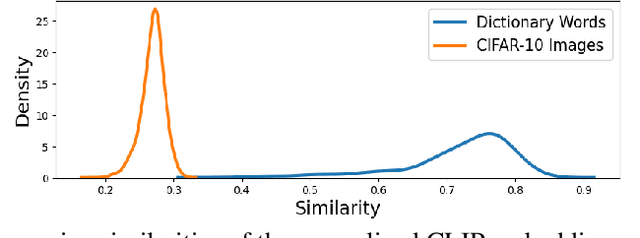
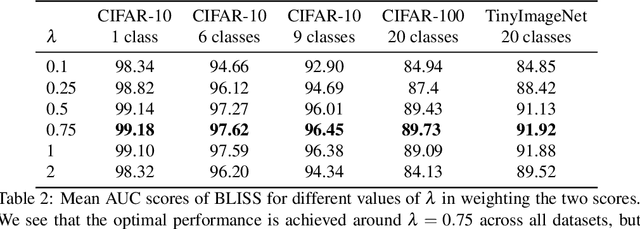
Contrastive Language-Image Pre-training (CLIP) achieves remarkable performance in various downstream tasks through the alignment of image and text input embeddings and holds great promise for anomaly detection. However, our empirical experiments show that the embeddings of text inputs unexpectedly tightly cluster together, far away from image embeddings, contrary to the model's contrastive training objective to align image-text input pairs. We show that this phenomenon induces a `similarity bias' - in which false negative and false positive errors occur due to bias in the similarities between images and the normal label text embeddings. To address this bias, we propose a novel methodology called BLISS which directly accounts for this similarity bias through the use of an auxiliary, external set of text inputs. BLISS is simple, it does not require strong inductive biases about anomalous behaviour nor an expensive training process, and it significantly outperforms baseline methods on benchmark image datasets, even when access to normal data is extremely limited.
COFT-AD: COntrastive Fine-Tuning for Few-Shot Anomaly Detection
Feb 29, 2024Existing approaches towards anomaly detection~(AD) often rely on a substantial amount of anomaly-free data to train representation and density models. However, large anomaly-free datasets may not always be available before the inference stage; in which case an anomaly detection model must be trained with only a handful of normal samples, a.k.a. few-shot anomaly detection (FSAD). In this paper, we propose a novel methodology to address the challenge of FSAD which incorporates two important techniques. Firstly, we employ a model pre-trained on a large source dataset to initialize model weights. Secondly, to ameliorate the covariate shift between source and target domains, we adopt contrastive training to fine-tune on the few-shot target domain data. To learn suitable representations for the downstream AD task, we additionally incorporate cross-instance positive pairs to encourage a tight cluster of the normal samples, and negative pairs for better separation between normal and synthesized negative samples. We evaluate few-shot anomaly detection on on 3 controlled AD tasks and 4 real-world AD tasks to demonstrate the effectiveness of the proposed method.
ARES: Locally Adaptive Reconstruction-based Anomaly Scoring
Jun 15, 2022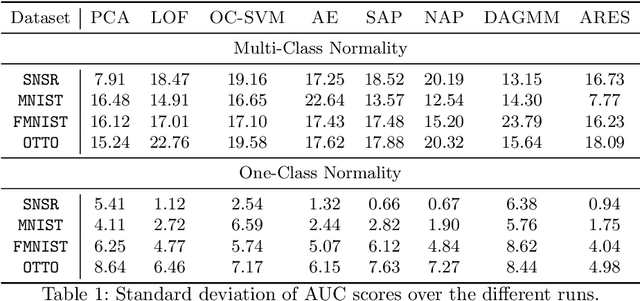
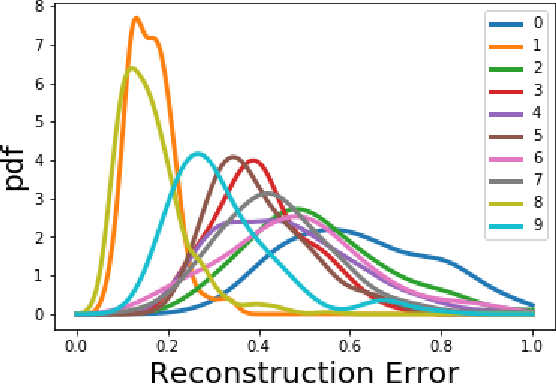
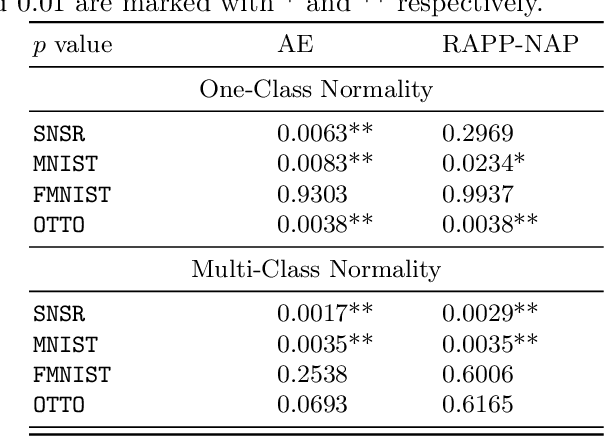
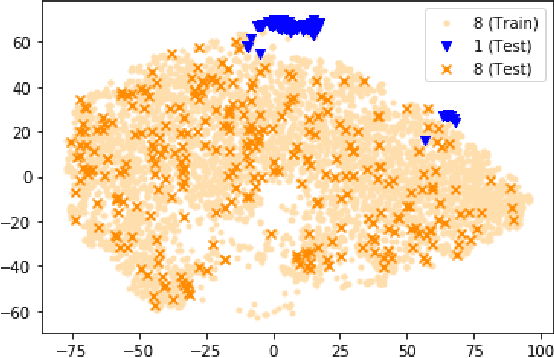
How can we detect anomalies: that is, samples that significantly differ from a given set of high-dimensional data, such as images or sensor data? This is a practical problem with numerous applications and is also relevant to the goal of making learning algorithms more robust to unexpected inputs. Autoencoders are a popular approach, partly due to their simplicity and their ability to perform dimension reduction. However, the anomaly scoring function is not adaptive to the natural variation in reconstruction error across the range of normal samples, which hinders their ability to detect real anomalies. In this paper, we empirically demonstrate the importance of local adaptivity for anomaly scoring in experiments with real data. We then propose our novel Adaptive Reconstruction Error-based Scoring approach, which adapts its scoring based on the local behaviour of reconstruction error over the latent space. We show that this improves anomaly detection performance over relevant baselines in a wide variety of benchmark datasets.
LUNAR: Unifying Local Outlier Detection Methods via Graph Neural Networks
Dec 10, 2021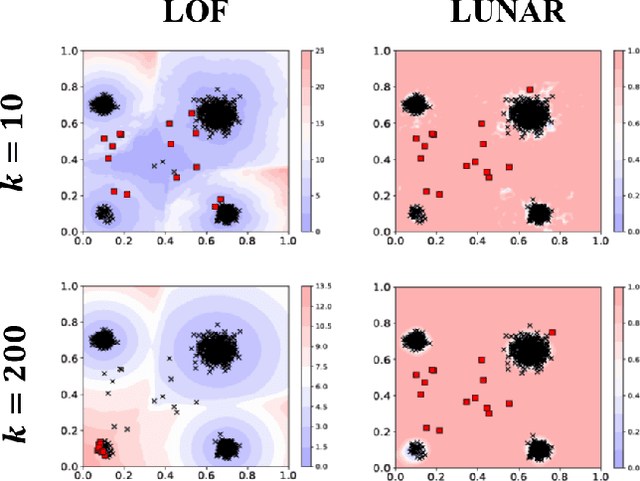
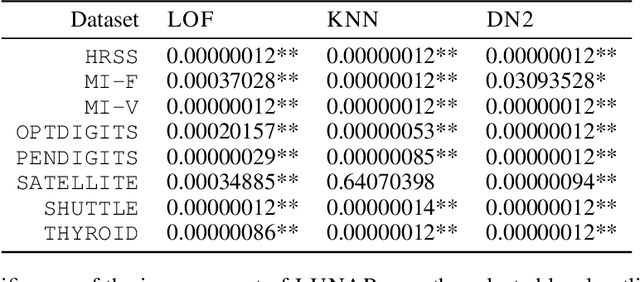
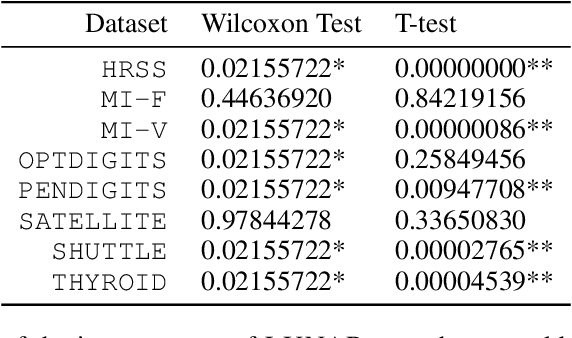
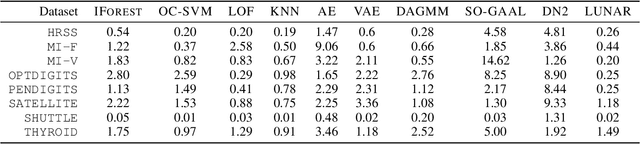
Many well-established anomaly detection methods use the distance of a sample to those in its local neighbourhood: so-called `local outlier methods', such as LOF and DBSCAN. They are popular for their simple principles and strong performance on unstructured, feature-based data that is commonplace in many practical applications. However, they cannot learn to adapt for a particular set of data due to their lack of trainable parameters. In this paper, we begin by unifying local outlier methods by showing that they are particular cases of the more general message passing framework used in graph neural networks. This allows us to introduce learnability into local outlier methods, in the form of a neural network, for greater flexibility and expressivity: specifically, we propose LUNAR, a novel, graph neural network-based anomaly detection method. LUNAR learns to use information from the nearest neighbours of each node in a trainable way to find anomalies. We show that our method performs significantly better than existing local outlier methods, as well as state-of-the-art deep baselines. We also show that the performance of our method is much more robust to different settings of the local neighbourhood size.