 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Elicitation: A New Attack Vector for Large Language Models
Feb 10, 2025



A fundamental issue in deep learning has been adversarial robustness. As these systems have scaled, such issues have persisted. Currently, large language models (LLMs) with billions of parameters suffer from adversarial attacks just like their earlier, smaller counterparts. However, the threat models have changed. Previously, having gray-box access, where input embeddings or output logits/probabilities were visible to the user, might have been reasonable. However, with the introduction of closed-source models, no information about the model is available apart from the generated output. This means that current black-box attacks can only utilize the final prediction to detect if an attack is successful. In this work, we investigate and demonstrate the potential of attack guidance, akin to using output probabilities, while having only black-box access in a classification setting. This is achieved through the ability to elicit confidence from the model. We empirically show that the elicited confidence is calibrated and not hallucinated for current LLMs. By minimizing the elicited confidence, we can therefore increase the likelihood of misclassification. Our new proposed paradigm demonstrates promising state-of-the-art results on three datasets across two models (LLaMA-3-8B-Instruct and Mistral-7B-Instruct-V0.3) when comparing our technique to existing hard-label black-box attack methods that introduce word-level substitutions.
SemRoDe: Macro Adversarial Training to Learn Representations That are Robust to Word-Level Attacks
Mar 27, 2024Language models (LMs) are indispensable tools for natural language processing tasks, but their vulnerability to adversarial attacks remains a concern. While current research has explored adversarial training techniques, their improvements to defend against word-level attacks have been limited. In this work, we propose a novel approach called Semantic Robust Defence (SemRoDe), a Macro Adversarial Training strategy to enhance the robustness of LMs. Drawing inspiration from recent studies in the image domain, we investigate and later confirm that in a discrete data setting such as language, adversarial samples generated via word substitutions do indeed belong to an adversarial domain exhibiting a high Wasserstein distance from the base domain. Our method learns a robust representation that bridges these two domains. We hypothesize that if samples were not projected into an adversarial domain, but instead to a domain with minimal shift, it would improve attack robustness. We align the domains by incorporating a new distance-based objective. With this, our model is able to learn more generalized representations by aligning the model's high-level output features and therefore better handling unseen adversarial samples. This method can be generalized across word embeddings, even when they share minimal overlap at both vocabulary and word-substitution levels. To evaluate the effectiveness of our approach, we conduct experiments on BERT and RoBERTa models on three datasets. The results demonstrate promising state-of-the-art robustness.
Fine Structure-Aware Sampling: A New Sampling Training Scheme for Pixel-Aligned Implicit Models in Single-View Human Reconstruction
Feb 29, 2024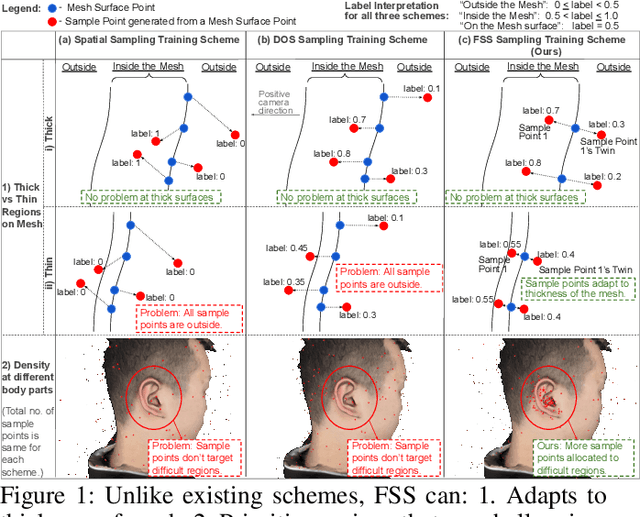
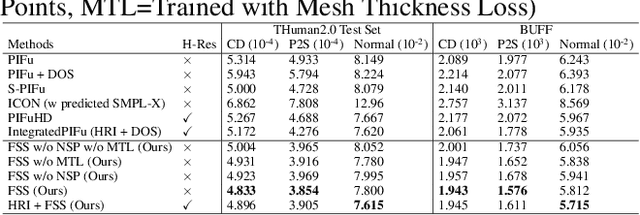
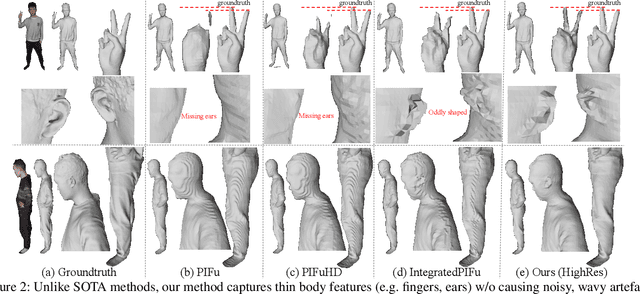
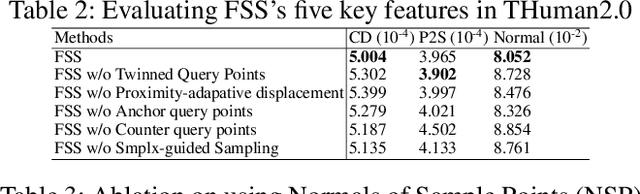
Pixel-aligned implicit models, such as PIFu, PIFuHD, and ICON, are used for single-view clothed human reconstruction. These models need to be trained using a sampling training scheme. Existing sampling training schemes either fail to capture thin surfaces (e.g. ears, fingers) or cause noisy artefacts in reconstructed meshes. To address these problems, we introduce Fine Structured-Aware Sampling (FSS), a new sampling training scheme to train pixel-aligned implicit models for single-view human reconstruction. FSS resolves the aforementioned problems by proactively adapting to the thickness and complexity of surfaces. In addition, unlike existing sampling training schemes, FSS shows how normals of sample points can be capitalized in the training process to improve results. Lastly, to further improve the training process, FSS proposes a mesh thickness loss signal for pixel-aligned implicit models. It becomes computationally feasible to introduce this loss once a slight reworking of the pixel-aligned implicit function framework is carried out. Our results show that our methods significantly outperform SOTA methods qualitatively and quantitatively. Our code is publicly available at https://github.com/kcyt/FSS.
COFT-AD: COntrastive Fine-Tuning for Few-Shot Anomaly Detection
Feb 29, 2024Existing approaches towards anomaly detection~(AD) often rely on a substantial amount of anomaly-free data to train representation and density models. However, large anomaly-free datasets may not always be available before the inference stage; in which case an anomaly detection model must be trained with only a handful of normal samples, a.k.a. few-shot anomaly detection (FSAD). In this paper, we propose a novel methodology to address the challenge of FSAD which incorporates two important techniques. Firstly, we employ a model pre-trained on a large source dataset to initialize model weights. Secondly, to ameliorate the covariate shift between source and target domains, we adopt contrastive training to fine-tune on the few-shot target domain data. To learn suitable representations for the downstream AD task, we additionally incorporate cross-instance positive pairs to encourage a tight cluster of the normal samples, and negative pairs for better separation between normal and synthesized negative samples. We evaluate few-shot anomaly detection on on 3 controlled AD tasks and 4 real-world AD tasks to demonstrate the effectiveness of the proposed method.
MoDA: Modeling Deformable 3D Objects from Casual Videos
Apr 17, 2023In this paper, we focus on the challenges of modeling deformable 3D objects from casual videos. With the popularity of neural radiance fields (NeRF), many works extend it to dynamic scenes with a canonical NeRF and a deformation model that achieves 3D point transformation between the observation space and the canonical space. Recent works rely on linear blend skinning (LBS) to achieve the canonical-observation transformation. However, the linearly weighted combination of rigid transformation matrices is not guaranteed to be rigid. As a matter of fact, unexpected scale and shear factors often appear. In practice, using LBS as the deformation model can always lead to skin-collapsing artifacts for bending or twisting motions. To solve this problem, we propose neural dual quaternion blend skinning (NeuDBS) to achieve 3D point deformation, which can perform rigid transformation without skin-collapsing artifacts. Besides, we introduce a texture filtering approach for texture rendering that effectively minimizes the impact of noisy colors outside target deformable objects. Extensive experiments on real and synthetic datasets show that our approach can reconstruct 3D models for humans and animals with better qualitative and quantitative performance than state-of-the-art methods.
Probably Approximate Shapley Fairness with Applications in Machine Learning
Dec 01, 2022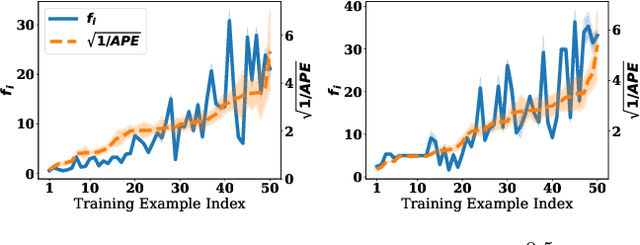
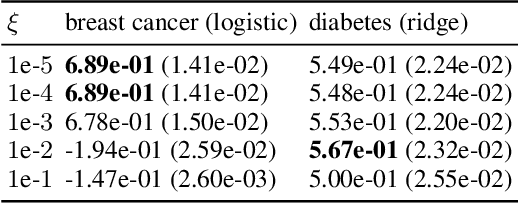
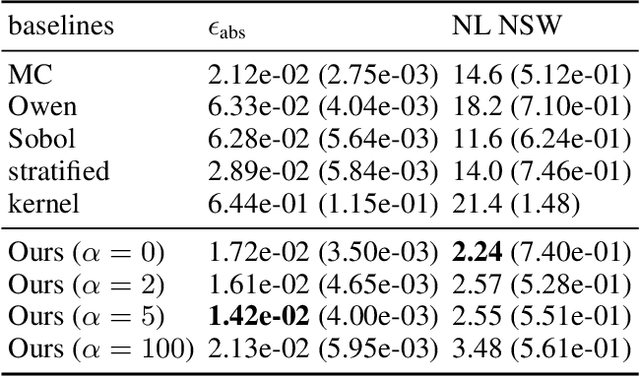
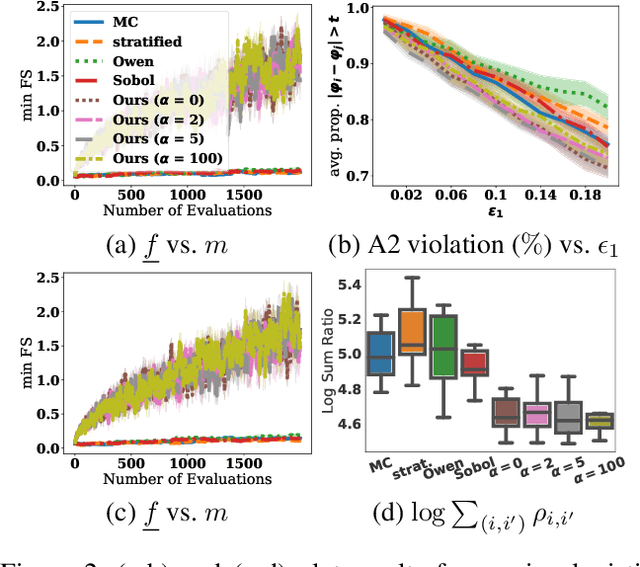
The Shapley value (SV) is adopted in various scenarios in machine learning (ML), including data valuation, agent valuation, and feature attribution, as it satisfies their fairness requirements. However, as exact SVs are infeasible to compute in practice, SV estimates are approximated instead. This approximation step raises an important question: do the SV estimates preserve the fairness guarantees of exact SVs? We observe that the fairness guarantees of exact SVs are too restrictive for SV estimates. Thus, we generalise Shapley fairness to probably approximate Shapley fairness and propose fidelity score, a metric to measure the variation of SV estimates, that determines how probable the fairness guarantees hold. Our last theoretical contribution is a novel greedy active estimation (GAE) algorithm that will maximise the lowest fidelity score and achieve a better fairness guarantee than the de facto Monte-Carlo estimation. We empirically verify GAE outperforms several existing methods in guaranteeing fairness while remaining competitive in estimation accuracy in various ML scenarios using real-world datasets.
Revisiting Pretraining for Semi-Supervised Learning in the Low-Label Regime
May 06, 2022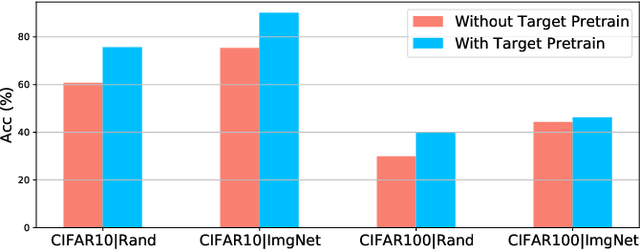
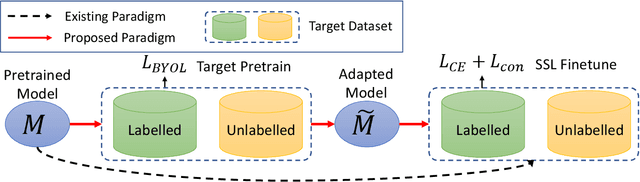
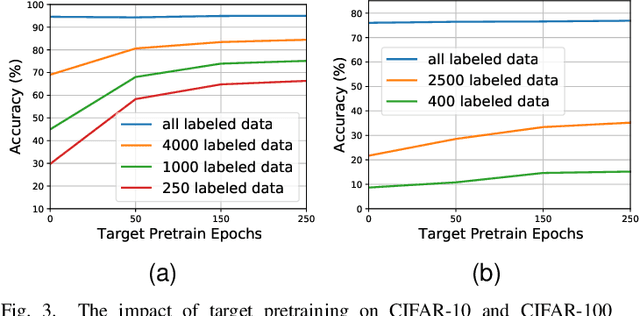
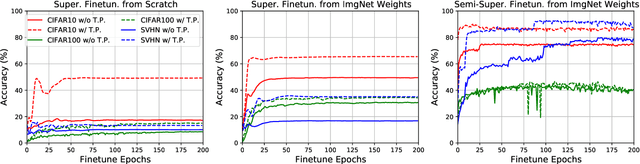
Semi-supervised learning (SSL) addresses the lack of labeled data by exploiting large unlabeled data through pseudolabeling. However, in the extremely low-label regime, pseudo labels could be incorrect, a.k.a. the confirmation bias, and the pseudo labels will in turn harm the network training. Recent studies combined finetuning (FT) from pretrained weights with SSL to mitigate the challenges and claimed superior results in the low-label regime. In this work, we first show that the better pretrained weights brought in by FT account for the state-of-the-art performance, and importantly that they are universally helpful to off-the-shelf semi-supervised learners. We further argue that direct finetuning from pretrained weights is suboptimal due to covariate shift and propose a contrastive target pretraining step to adapt model weights towards target dataset. We carried out extensive experiments on both classification and segmentation tasks by doing target pretraining then followed by semi-supervised finetuning. The promising results validate the efficacy of target pretraining for SSL, in particular in the low-label regime.
Open-Set Semi-Supervised Learning for 3D Point Cloud Understanding
May 02, 2022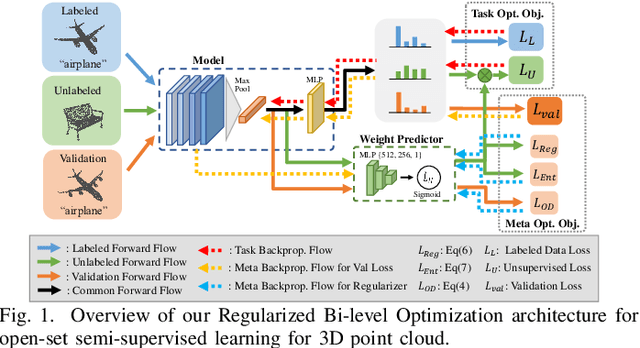
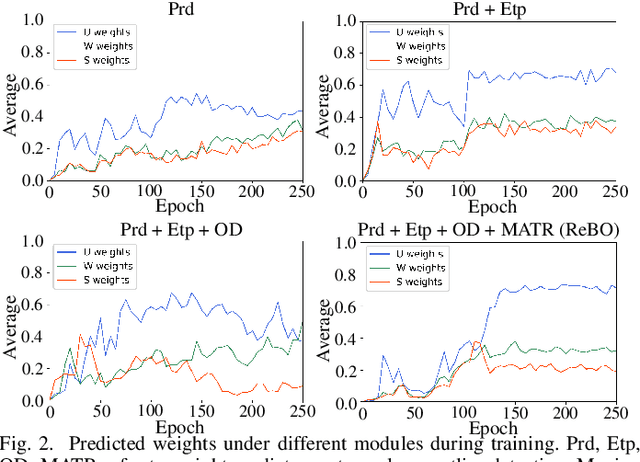
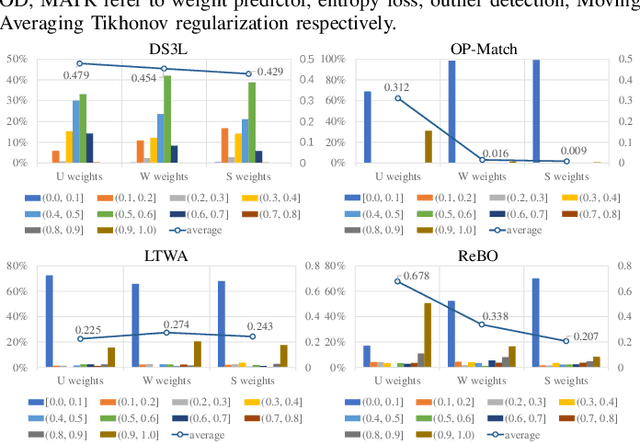
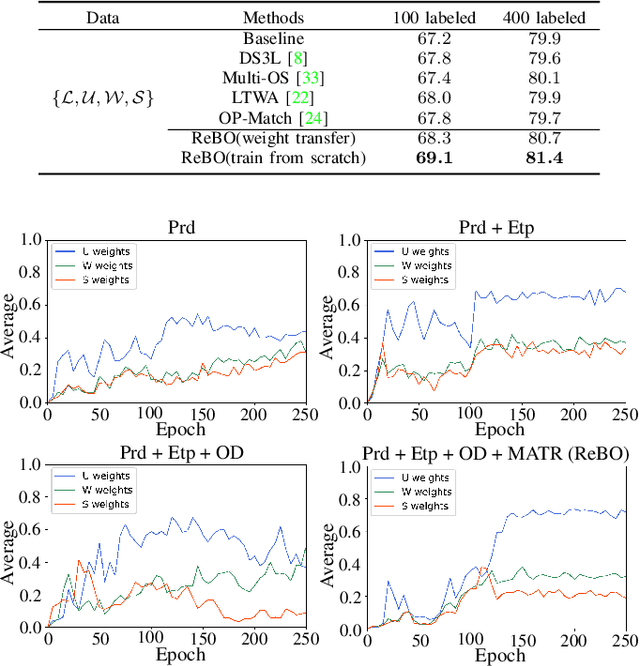
Semantic understanding of 3D point cloud relies on learning models with massively annotated data, which, in many cases, are expensive or difficult to collect. This has led to an emerging research interest in semi-supervised learning (SSL) for 3D point cloud. It is commonly assumed in SSL that the unlabeled data are drawn from the same distribution as that of the labeled ones; This assumption, however, rarely holds true in realistic environments. Blindly using out-of-distribution (OOD) unlabeled data could harm SSL performance. In this work, we propose to selectively utilize unlabeled data through sample weighting, so that only conducive unlabeled data would be prioritized. To estimate the weights, we adopt a bi-level optimization framework which iteratively optimizes a metaobjective on a held-out validation set and a task-objective on a training set. Faced with the instability of efficient bi-level optimizers, we further propose three regularization techniques to enhance the training stability. Extensive experiments on 3D point cloud classification and segmentation tasks verify the effectiveness of our proposed method. We also demonstrate the feasibility of a more efficient training strategy.
Incentivizing Collaboration in Machine Learning via Synthetic Data Rewards
Dec 17, 2021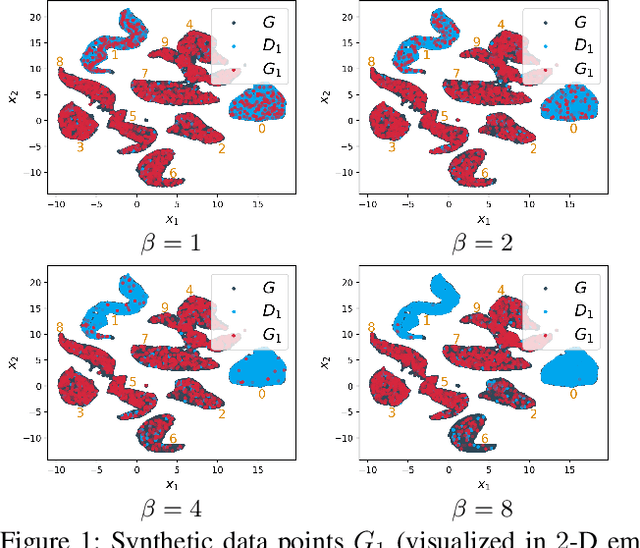
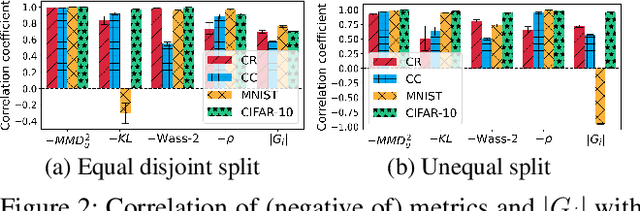
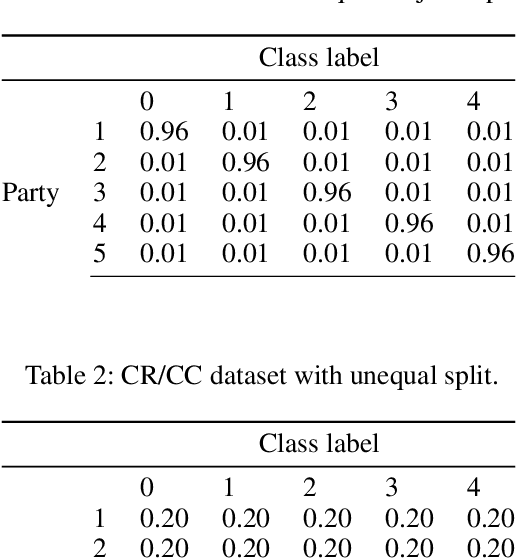
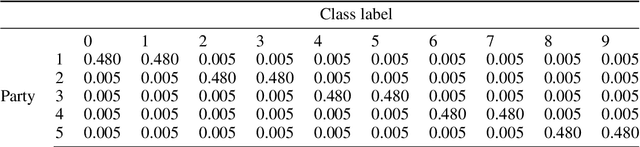
This paper presents a novel collaborative generative modeling (CGM) framework that incentivizes collaboration among self-interested parties to contribute data to a pool for training a generative model (e.g., GAN), from which synthetic data are drawn and distributed to the parties as rewards commensurate to their contributions. Distributing synthetic data as rewards (instead of trained models or money) offers task- and model-agnostic benefits for downstream learning tasks and is less likely to violate data privacy regulation. To realize the framework, we firstly propose a data valuation function using maximum mean discrepancy (MMD) that values data based on its quantity and quality in terms of its closeness to the true data distribution and provide theoretical results guiding the kernel choice in our MMD-based data valuation function. Then, we formulate the reward scheme as a linear optimization problem that when solved, guarantees certain incentives such as fairness in the CGM framework. We devise a weighted sampling algorithm for generating synthetic data to be distributed to each party as reward such that the value of its data and the synthetic data combined matches its assigned reward value by the reward scheme. We empirically show using simulated and real-world datasets that the parties' synthetic data rewards are commensurate to their contributions.
Semi-supervised classification of radiology images with NoTeacher: A Teacher that is not Mean
Aug 10, 2021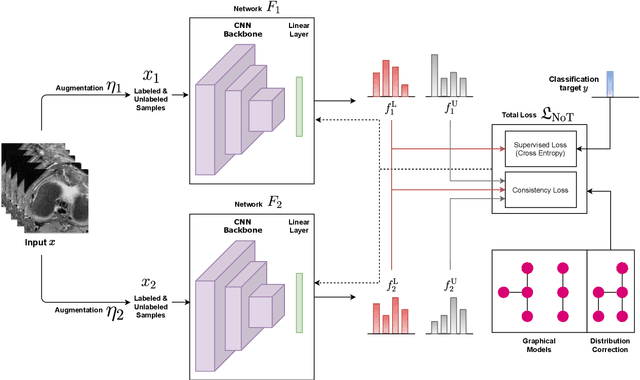
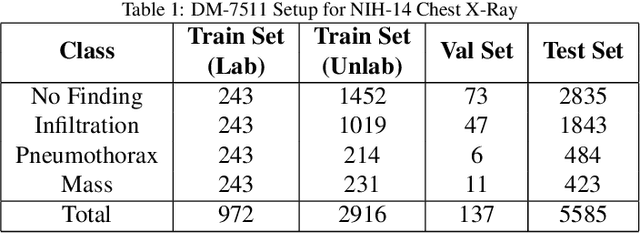
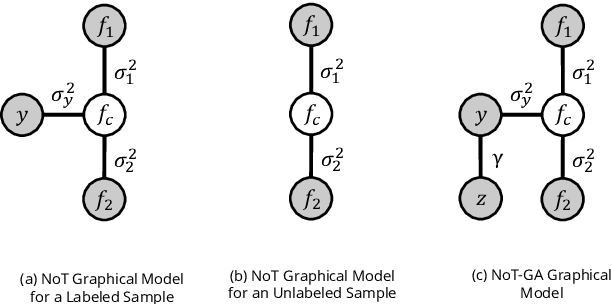
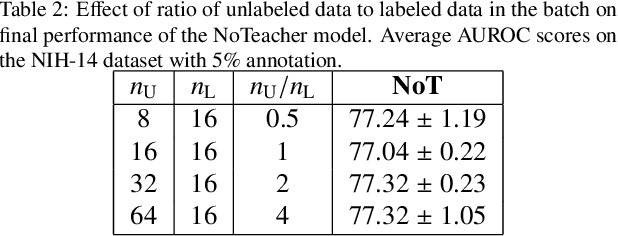
Deep learning models achieve strong performance for radiology image classification, but their practical application is bottlenecked by the need for large labeled training datasets. Semi-supervised learning (SSL) approaches leverage small labeled datasets alongside larger unlabeled datasets and offer potential for reducing labeling cost. In this work, we introduce NoTeacher, a novel consistency-based SSL framework which incorporates probabilistic graphical models. Unlike Mean Teacher which maintains a teacher network updated via a temporal ensemble, NoTeacher employs two independent networks, thereby eliminating the need for a teacher network. We demonstrate how NoTeacher can be customized to handle a range of challenges in radiology image classification. Specifically, we describe adaptations for scenarios with 2D and 3D inputs, uni and multi-label classification, and class distribution mismatch between labeled and unlabeled portions of the training data. In realistic empirical evaluations on three public benchmark datasets spanning the workhorse modalities of radiology (X-Ray, CT, MRI), we show that NoTeacher achieves over 90-95% of the fully supervised AUROC with less than 5-15% labeling budget. Further, NoTeacher outperforms established SSL methods with minimal hyperparameter tuning, and has implications as a principled and practical option for semisupervised learning in radiology applications.