 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Truthfulness and Collaborative Fairness in Bayesian Learning
May 12, 2026Collaborative machine learning involves training high-quality models using datasets from a number of sources. To incentivize sources to share data, existing data valuation methods fairly reward each source based on its data submitted as is. However, as these methods do not verify nor incentivize data truthfulness, the sources can manipulate their data (e.g., by submitting duplicated or noisy data) to artificially increase their valuations and rewards or prevent others from benefiting. This paper presents the first mechanism that provably ensures (F) collaborative fairness and incentivizes (T) truthfulness at equilibrium for Bayesian models. Our mechanism combines semivalues (e.g., Shapley value), which ensure fairness, and a truthful data valuation function (DVF) based on a validation set that is unknown to the sources. As semivalues are influenced by others' data, we introduce an additional condition to prove that a source can maximize its expected data values in coalitions and semivalues by submitting a dataset that captures its true knowledge. Additionally, we discuss the implications and suitable relaxations of (F) and (T) when the mediator has a limited budget for rewards or lacks a validation set. Our theoretical findings are validated on synthetic and real-world datasets.
MME-CoF-Pro: Evaluating Reasoning Coherence in Video Generative Models with Text and Visual Hints
Mar 20, 2026Video generative models show emerging reasoning behaviors. It is essential to ensure that generated events remain causally consistent across frames for reliable deployment, a property we define as reasoning coherence. To bridge the gap in literature for missing reasoning coherence evaluation, we propose MME-CoF-Pro, a comprehensive video reasoning benchmark to assess reasoning coherence in video models. Specifically, MME-CoF-Pro contains 303 samples across 16 categories, ranging from visual logical to scientific reasoning. It introduces Reasoning Score as evaluation metric for assessing process-level necessary intermediate reasoning steps, and includes three evaluation settings, (a) no hint (b) text hint and (c) visual hint, enabling a controlled investigation into the underlying mechanisms of reasoning hint guidance. Evaluation results in 7 open and closed-source video models reveals insights including: (1) Video generative models exhibit weak reasoning coherence, decoupled from generation quality. (2) Text hints boost apparent correctness but often cause inconsistency and hallucinated reasoning (3) Visual hints benefit structured perceptual tasks but struggle with fine-grained perception. Website: https://video-reasoning-coherence.github.io/
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
From Failure to Mastery: Generating Hard Samples for Tool-use Agents
Jan 04, 2026The advancement of LLM agents with tool-use capabilities requires diverse and complex training corpora. Existing data generation methods, which predominantly follow a paradigm of random sampling and shallow generation, often yield simple and homogeneous trajectories that fail to capture complex, implicit logical dependencies. To bridge this gap, we introduce HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning. Firstly, HardGen establishes a dynamic API Graph built upon agent failure cases, from which it samples to synthesize hard traces. Secondly, these traces serve as conditional priors to guide the instantiation of modular, abstract advanced tools, which are subsequently leveraged to formulate hard queries. Finally, the advanced tools and hard queries enable the generation of verifiable complex Chain-of-Thought (CoT), with a closed-loop evaluation feedback steering the continuous refinement of the process. Extensive evaluations demonstrate that a 4B parameter model trained with our curated dataset achieves superior performance compared to several leading open-source and closed-source competitors (e.g., GPT-5.2, Gemini-3-Pro and Claude-Opus-4.5). Our code, models, and dataset will be open-sourced to facilitate future research.
Uncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies
May 13, 2025
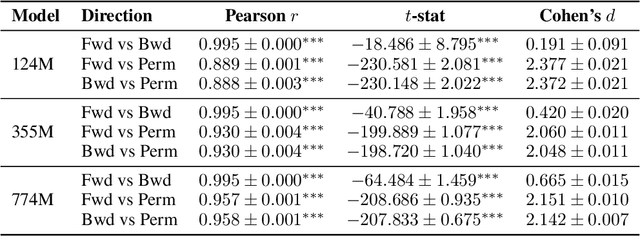


Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined probability distribution, sequence perplexity is invariant under any factorization, including forward, backward, or arbitrary permutations. This result establishes a rigorous theoretical foundation for studying how LLMs learn from data and defines principled protocols for empirical evaluation. Applying these protocols, we show that prior studies examining ordering effects suffer from critical methodological flaws. We retrain GPT-2 models across forward, backward, and arbitrary permuted orders on scientific text. We find systematic deviations from theoretical invariance across all orderings with arbitrary permutations strongly deviating from both forward and backward models, which largely (but not completely) agreed with one another. Deviations were traceable to differences in self-attention, reflecting positional and locality biases in processing. Our theoretical and empirical results provide novel avenues for understanding positional biases in LLMs and suggest methods for detecting when LLMs' probability distributions are inconsistent and therefore untrustworthy.
Data value estimation on private gradients
Dec 22, 2024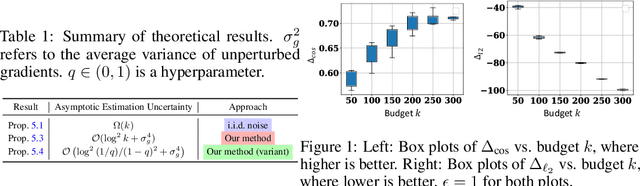
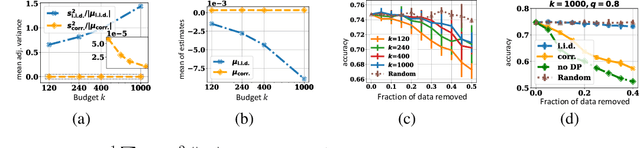
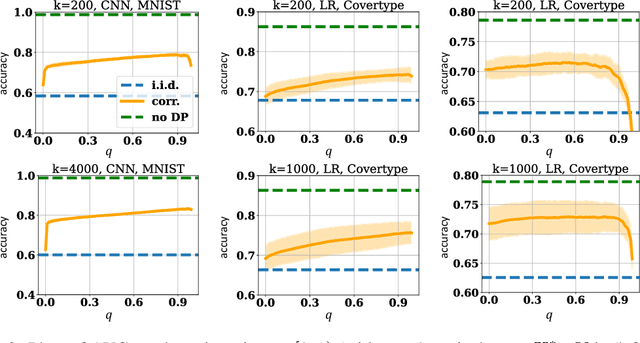

For gradient-based machine learning (ML) methods commonly adopted in practice such as stochastic gradient descent, the de facto differential privacy (DP) technique is perturbing the gradients with random Gaussian noise. Data valuation attributes the ML performance to the training data and is widely used in privacy-aware applications that require enforcing DP such as data pricing, collaborative ML, and federated learning (FL). Can existing data valuation methods still be used when DP is enforced via gradient perturbations? We show that the answer is no with the default approach of injecting i.i.d.~random noise to the gradients because the estimation uncertainty of the data value estimation paradoxically linearly scales with more estimation budget, producing estimates almost like random guesses. To address this issue, we propose to instead inject carefully correlated noise to provably remove the linear scaling of estimation uncertainty w.r.t.~the budget. We also empirically demonstrate that our method gives better data value estimates on various ML tasks and is applicable to use cases including dataset valuation and~FL.
AtlasSeg: Atlas Prior Guided Dual-U-Net for Cortical Segmentation in Fetal Brain MRI
Nov 05, 2024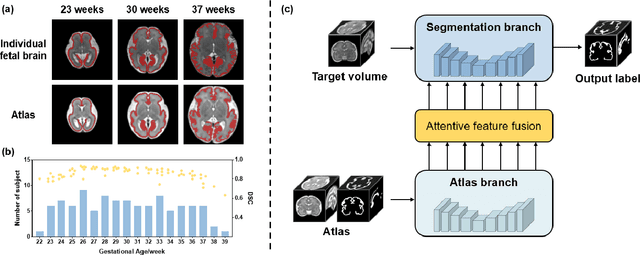
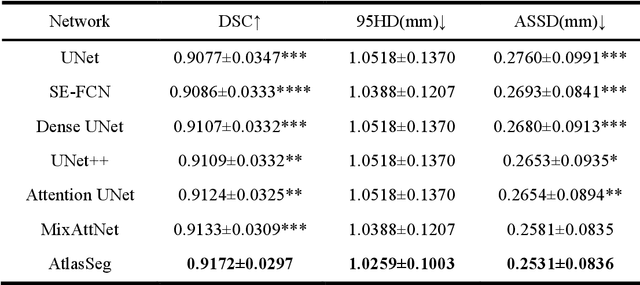
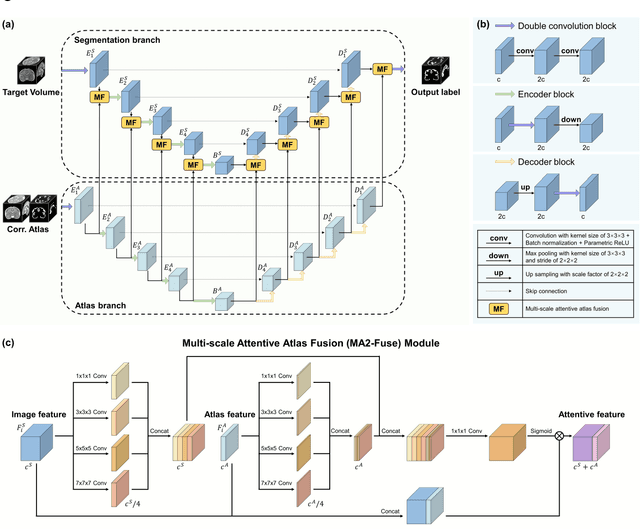

Accurate tissue segmentation in fetal brain MRI remains challenging due to the dynamically changing anatomical anatomy and contrast during fetal development. To enhance segmentation accuracy throughout gestation, we introduced AtlasSeg, a dual-U-shape convolution network incorporating gestational age (GA) specific information as guidance. By providing a publicly available fetal brain atlas with segmentation label at the corresponding GA, AtlasSeg effectively extracted the contextual features of age-specific patterns in atlas branch and generated tissue segmentation in segmentation branch. Multi-scale attentive atlas feature fusions were constructed in all stages during encoding and decoding, giving rise to a dual-U-shape network to assist feature flow and information interactions between two branches. AtlasSeg outperformed six well-known segmentation networks in both our internal fetal brain MRI dataset and the external FeTA dataset. Ablation experiments demonstrate the efficiency of atlas guidance and the attention mechanism. The proposed AtlasSeg demonstrated superior segmentation performance against other convolution networks with higher segmentation accuracy, and may facilitate fetal brain MRI analysis in large-scale fetal brain studies.
Data Distribution Valuation
Oct 06, 2024
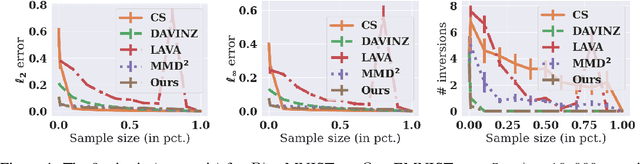

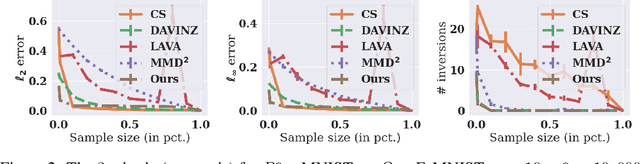
Data valuation is a class of techniques for quantitatively assessing the value of data for applications like pricing in data marketplaces. Existing data valuation methods define a value for a discrete dataset. However, in many use cases, users are interested in not only the value of the dataset, but that of the distribution from which the dataset was sampled. For example, consider a buyer trying to evaluate whether to purchase data from different vendors. The buyer may observe (and compare) only a small preview sample from each vendor, to decide which vendor's data distribution is most useful to the buyer and purchase. The core question is how should we compare the values of data distributions from their samples? Under a Huber characterization of the data heterogeneity across vendors, we propose a maximum mean discrepancy (MMD)-based valuation method which enables theoretically principled and actionable policies for comparing data distributions from samples. We empirically demonstrate that our method is sample-efficient and effective in identifying valuable data distributions against several existing baselines, on multiple real-world datasets (e.g., network intrusion detection, credit card fraud detection) and downstream applications (classification, regression).
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024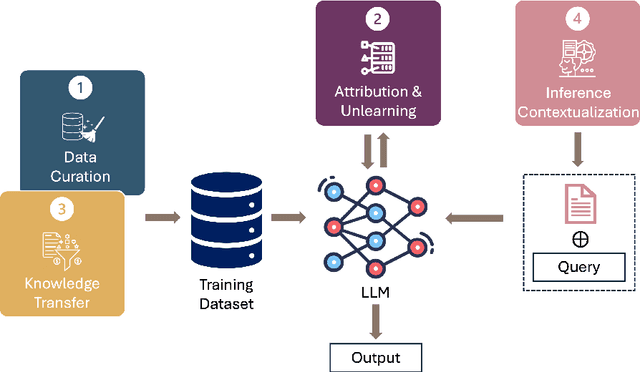
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.