 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chicken and Egg Dilemma: Co-optimizing Data and Model Configurations for LLMs
Feb 09, 2026Co-optimizing data and model configurations for training LLMs presents a classic chicken-and-egg dilemma: The best training data configuration (e.g., data mixture) for a downstream task depends on the chosen model configuration (e.g., model architecture), and vice versa. However, jointly optimizing both data and model configurations is often deemed intractable, and existing methods focus on either data or model optimization without considering their interaction. We introduce JoBS, an approach that uses a scaling-law-inspired performance predictor to aid Bayesian optimization (BO) in jointly optimizing LLM training data and model configurations efficiently. JoBS allocates a portion of the optimization budget to learn an LLM performance predictor that predicts how promising a training configuration is from a small number of training steps. The remaining budget is used to perform BO entirely with the predictor, effectively amortizing the cost of running full-training runs. We study JoBS's average regret and devise the optimal budget allocation to minimize regret. JoBS outperforms existing multi-fidelity BO baselines, as well as data and model optimization approaches across diverse LLM tasks under the same optimization budget.
Fast-SAM3D: 3Dfy Anything in Images but Faster
Feb 05, 2026SAM3D enables scalable, open-world 3D reconstruction from complex scenes, yet its deployment is hindered by prohibitive inference latency. In this work, we conduct the \textbf{first systematic investigation} into its inference dynamics, revealing that generic acceleration strategies are brittle in this context. We demonstrate that these failures stem from neglecting the pipeline's inherent multi-level \textbf{heterogeneity}: the kinematic distinctiveness between shape and layout, the intrinsic sparsity of texture refinement, and the spectral variance across geometries. To address this, we present \textbf{Fast-SAM3D}, a training-free framework that dynamically aligns computation with instantaneous generation complexity. Our approach integrates three heterogeneity-aware mechanisms: (1) \textit{Modality-Aware Step Caching} to decouple structural evolution from sensitive layout updates; (2) \textit{Joint Spatiotemporal Token Carving} to concentrate refinement on high-entropy regions; and (3) \textit{Spectral-Aware Token Aggregation} to adapt decoding resolution. Extensive experiments demonstrate that Fast-SAM3D delivers up to \textbf{2.67$\times$} end-to-end speedup with negligible fidelity loss, establishing a new Pareto frontier for efficient single-view 3D generation. Our code is released in https://github.com/wlfeng0509/Fast-SAM3D.
Uncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
Broaden your SCOPE! Efficient Multi-turn Conversation Planning for LLMs using Semantic Space
Mar 14, 2025Large language models (LLMs) are used in chatbots or AI assistants to hold conversations with a human user. In such applications, the quality (e.g., user engagement, safety) of a conversation is important and can only be exactly known at the end of the conversation. To maximize its expected quality, conversation planning reasons about the stochastic transitions within a conversation to select the optimal LLM response at each turn. Existing simulation-based conversation planning algorithms typically select the optimal response by simulating future conversations with a large number of LLM queries at every turn. However, this process is extremely time-consuming and hence impractical for real-time conversations. This paper presents a novel approach called Semantic space COnversation Planning with improved Efficiency (SCOPE) that exploits the dense semantic representation of conversations to perform conversation planning efficiently. In particular, SCOPE models the stochastic transitions in conversation semantics and their associated rewards to plan entirely within the semantic space. This allows us to select the optimal LLM response at every conversation turn without needing additional LLM queries for simulation. As a result, SCOPE can perform conversation planning 70 times faster than conventional simulation-based planning algorithms when applied to a wide variety of conversation starters and two reward functions seen in the real world, yet achieving a higher reward within a practical planning budget. Our code can be found at: https://github.com/chenzhiliang94/convo-plan-SCOPE.
The Reasonable Crowd: Towards evidence-based and interpretable models of driving behavior
Jul 28, 2021
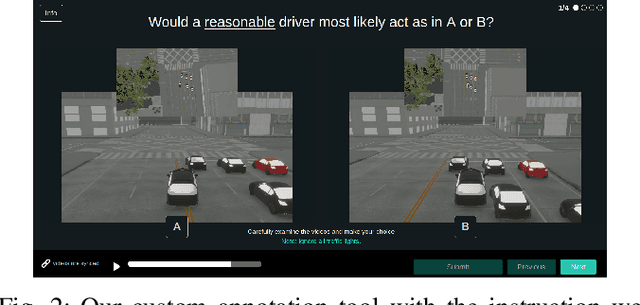

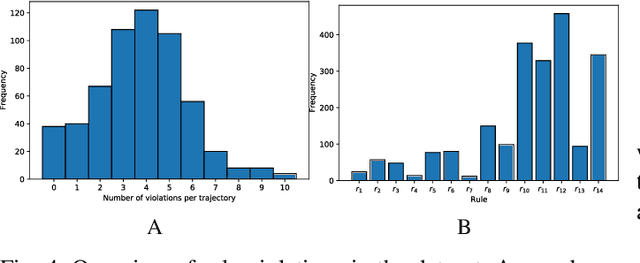
Autonomous vehicles must balance a complex set of objectives. There is no consensus on how they should do so, nor on a model for specifying a desired driving behavior. We created a dataset to help address some of these questions in a limited operating domain. The data consists of 92 traffic scenarios, with multiple ways of traversing each scenario. Multiple annotators expressed their preference between pairs of scenario traversals. We used the data to compare an instance of a rulebook, carefully hand-crafted independently of the dataset, with several interpretable machine learning models such as Bayesian networks, decision trees, and logistic regression trained on the dataset. To compare driving behavior, these models use scores indicating by how much different scenario traversals violate each of 14 driving rules. The rules are interpretable and designed by subject-matter experts. First, we found that these rules were enough for these models to achieve a high classification accuracy on the dataset. Second, we found that the rulebook provides high interpretability without excessively sacrificing performance. Third, the data pointed to possible improvements in the rulebook and the rules, and to potential new rules. Fourth, we explored the interpretability vs performance trade-off by also training non-interpretable models such as a random forest. Finally, we make the dataset publicly available to encourage a discussion from the wider community on behavior specification for AVs. Please find it at github.com/bassam-motional/Reasonable-Crowd.
Fair Multi-party Machine Learning -- a Game Theoretic approach
Nov 22, 2019



High performance machine learning models have become highly dependent on the availability of large quantity and quality of training data. To achieve this, various central agencies such as the government have suggested for different data providers to pool their data together to learn a unified predictive model, which performs better. However, these providers are usually profit-driven and would only agree to participate inthe data sharing process if the process is deemed both profitable and fair for themselves. Due to the lack of existing literature, it is unclear whether a fair and stable outcome is possible in such data sharing processes. Hence, we wish to investigate the outcomes surrounding these scenarios and study if data providers would even agree to collaborate in the first place. Tapping on cooperative game concepts in Game Theory, we introduce the data sharing process between a group of agents as a new class of cooperative games with modified definition of stability and fairness. Using these new definitions, we then theoretically study the optimal and suboptimal outcomes of such data sharing processes and their sensitivity to perturbation.Through experiments, we present intuitive insights regarding theoretical results analysed in this paper and discuss various ways in which data can be valued reasonably.