 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chicken and Egg Dilemma: Co-optimizing Data and Model Configurations for LLMs
Feb 09, 2026Co-optimizing data and model configurations for training LLMs presents a classic chicken-and-egg dilemma: The best training data configuration (e.g., data mixture) for a downstream task depends on the chosen model configuration (e.g., model architecture), and vice versa. However, jointly optimizing both data and model configurations is often deemed intractable, and existing methods focus on either data or model optimization without considering their interaction. We introduce JoBS, an approach that uses a scaling-law-inspired performance predictor to aid Bayesian optimization (BO) in jointly optimizing LLM training data and model configurations efficiently. JoBS allocates a portion of the optimization budget to learn an LLM performance predictor that predicts how promising a training configuration is from a small number of training steps. The remaining budget is used to perform BO entirely with the predictor, effectively amortizing the cost of running full-training runs. We study JoBS's average regret and devise the optimal budget allocation to minimize regret. JoBS outperforms existing multi-fidelity BO baselines, as well as data and model optimization approaches across diverse LLM tasks under the same optimization budget.
The Reward Model Selection Crisis in Personalized Alignment
Dec 28, 2025Personalized alignment from preference data has focused primarily on improving reward model (RM) accuracy, with the implicit assumption that better preference ranking translates to better personalized behavior. However, in deployment, computational constraints necessitate inference-time adaptation via reward-guided decoding (RGD) rather than per-user policy fine-tuning. This creates a critical but overlooked requirement: reward models must not only rank preferences accurately but also effectively guide token-level generation decisions. We demonstrate that standard RM accuracy fails catastrophically as a selection criterion for deployment-ready personalized alignment. Through systematic evaluation across three datasets, we introduce policy accuracy, a metric quantifying whether RGD scoring functions correctly discriminate between preferred and dispreferred responses. We show that RM accuracy correlates only weakly with this policy-level discrimination ability (Kendall's tau = 0.08--0.31). More critically, we introduce Pref-LaMP, the first personalized alignment benchmark with ground-truth user completions, enabling direct behavioral evaluation without circular reward-based metrics. On Pref-LaMP, we expose a complete decoupling between discrimination and generation: methods with 20-point RM accuracy differences produce almost identical output quality, and even methods achieving high discrimination fail to generate behaviorally aligned responses. Finally, simple in-context learning (ICL) dominates all reward-guided methods for models > 3B parameters, achieving 3-5 point ROUGE-1 gains over the best reward method at 7B scale. These findings show that the field optimizes proxy metrics that fail to predict deployment performance and do not translate preferences into real behavioral adaptation under deployment constraints.
Box-Level Class-Balanced Sampling for Active Object Detection
Aug 25, 2025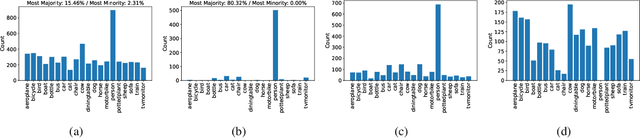
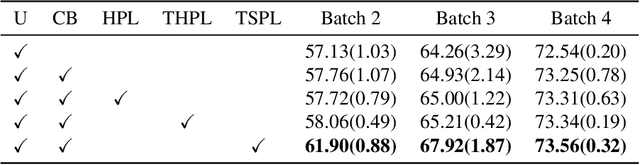

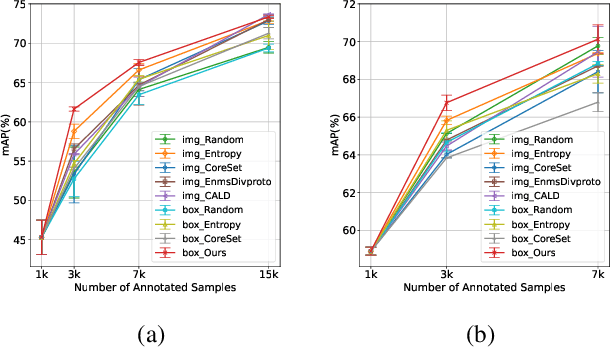
Training deep object detectors demands expensive bounding box annotation. Active learning (AL) is a promising technique to alleviate the annotation burden. Performing AL at box-level for object detection, i.e., selecting the most informative boxes to label and supplementing the sparsely-labelled image with pseudo labels, has been shown to be more cost-effective than selecting and labelling the entire image. In box-level AL for object detection, we observe that models at early stage can only perform well on majority classes, making the pseudo labels severely class-imbalanced. We propose a class-balanced sampling strategy to select more objects from minority classes for labelling, so as to make the final training data, \ie, ground truth labels obtained by AL and pseudo labels, more class-balanced to train a better model. We also propose a task-aware soft pseudo labelling strategy to increase the accuracy of pseudo labels. We evaluate our method on public benchmarking datasets and show that our method achieves state-of-the-art performance.
Exploring Active Learning for Semiconductor Defect Segmentation
Jul 23, 2025The development of X-Ray microscopy (XRM) technology has enabled non-destructive inspection of semiconductor structures for defect identification. Deep learning is widely used as the state-of-the-art approach to perform visual analysis tasks. However, deep learning based models require large amount of annotated data to train. This can be time-consuming and expensive to obtain especially for dense prediction tasks like semantic segmentation. In this work, we explore active learning (AL) as a potential solution to alleviate the annotation burden. We identify two unique challenges when applying AL on semiconductor XRM scans: large domain shift and severe class-imbalance. To address these challenges, we propose to perform contrastive pretraining on the unlabelled data to obtain the initialization weights for each AL cycle, and a rareness-aware acquisition function that favors the selection of samples containing rare classes. We evaluate our method on a semiconductor dataset that is compiled from XRM scans of high bandwidth memory structures composed of logic and memory dies, and demonstrate that our method achieves state-of-the-art performance.
Exploring Spatial Diversity for Region-based Active Learning
Jul 23, 2025State-of-the-art methods for semantic segmentation are based on deep neural networks trained on large-scale labeled datasets. Acquiring such datasets would incur large annotation costs, especially for dense pixel-level prediction tasks like semantic segmentation. We consider region-based active learning as a strategy to reduce annotation costs while maintaining high performance. In this setting, batches of informative image regions instead of entire images are selected for labeling. Importantly, we propose that enforcing local spatial diversity is beneficial for active learning in this case, and to incorporate spatial diversity along with the traditional active selection criterion, e.g., data sample uncertainty, in a unified optimization framework for region-based active learning. We apply this framework to the Cityscapes and PASCAL VOC datasets and demonstrate that the inclusion of spatial diversity effectively improves the performance of uncertainty-based and feature diversity-based active learning methods. Our framework achieves $95\%$ performance of fully supervised methods with only $5-9\%$ of the labeled pixels, outperforming all state-of-the-art region-based active learning methods for semantic segmentation.
WaterDrum: Watermarking for Data-centric Unlearning Metric
May 08, 2025Large language model (LLM) unlearning is critical in real-world applications where it is necessary to efficiently remove the influence of private, copyrighted, or harmful data from some users. However, existing utility-centric unlearning metrics (based on model utility) may fail to accurately evaluate the extent of unlearning in realistic settings such as when (a) the forget and retain set have semantically similar content, (b) retraining the model from scratch on the retain set is impractical, and/or (c) the model owner can improve the unlearning metric without directly performing unlearning on the LLM. This paper presents the first data-centric unlearning metric for LLMs called WaterDrum that exploits robust text watermarking for overcoming these limitations. We also introduce new benchmark datasets for LLM unlearning that contain varying levels of similar data points and can be used to rigorously evaluate unlearning algorithms using WaterDrum. Our code is available at https://github.com/lululu008/WaterDrum and our new benchmark datasets are released at https://huggingface.co/datasets/Glow-AI/WaterDrum-Ax.
CADCrafter: Generating Computer-Aided Design Models from Unconstrained Images
Apr 10, 2025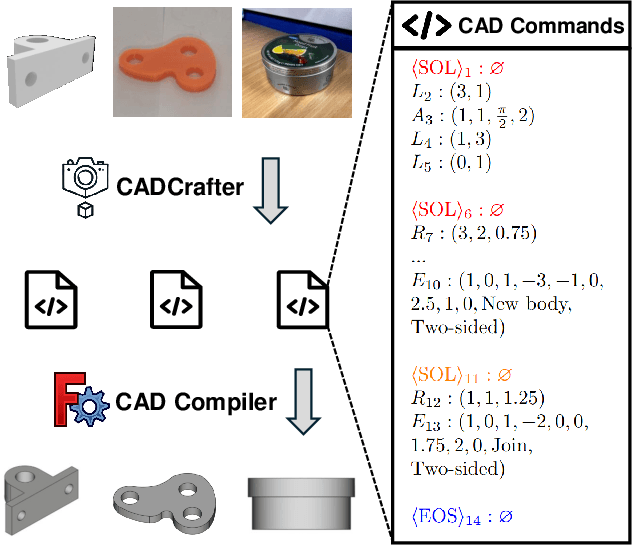
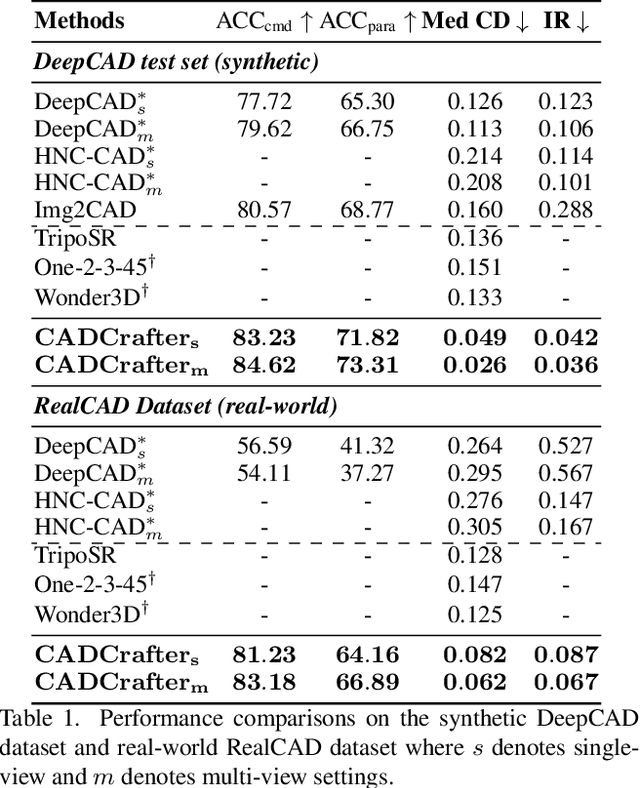
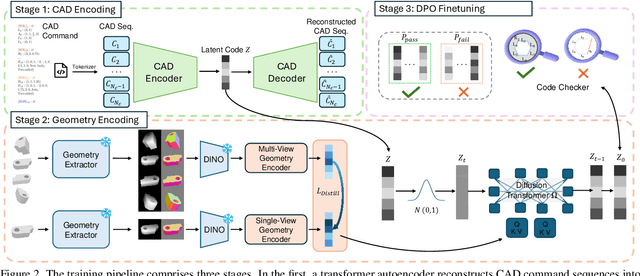
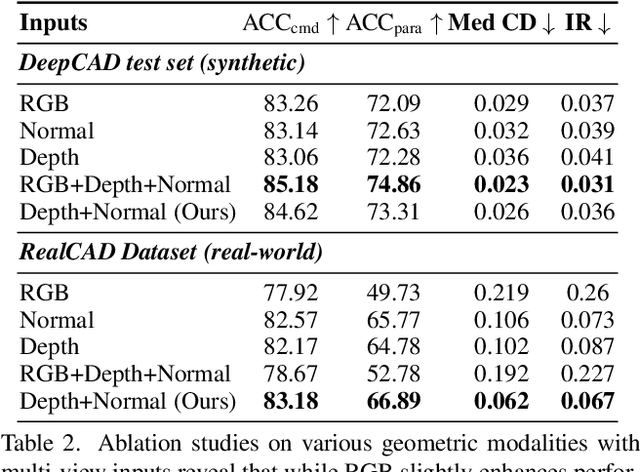
Creating CAD digital twins from the physical world is crucial for manufacturing, design, and simulation. However, current methods typically rely on costly 3D scanning with labor-intensive post-processing. To provide a user-friendly design process, we explore the problem of reverse engineering from unconstrained real-world CAD images that can be easily captured by users of all experiences. However, the scarcity of real-world CAD data poses challenges in directly training such models. To tackle these challenges, we propose CADCrafter, an image-to-parametric CAD model generation framework that trains solely on synthetic textureless CAD data while testing on real-world images. To bridge the significant representation disparity between images and parametric CAD models, we introduce a geometry encoder to accurately capture diverse geometric features. Moreover, the texture-invariant properties of the geometric features can also facilitate the generalization to real-world scenarios. Since compiling CAD parameter sequences into explicit CAD models is a non-differentiable process, the network training inherently lacks explicit geometric supervision. To impose geometric validity constraints, we employ direct preference optimization (DPO) to fine-tune our model with the automatic code checker feedback on CAD sequence quality. Furthermore, we collected a real-world dataset, comprised of multi-view images and corresponding CAD command sequence pairs, to evaluate our method. Experimental results demonstrate that our approach can robustly handle real unconstrained CAD images, and even generalize to unseen general objects.
Broaden your SCOPE! Efficient Multi-turn Conversation Planning for LLMs using Semantic Space
Mar 14, 2025Large language models (LLMs) are used in chatbots or AI assistants to hold conversations with a human user. In such applications, the quality (e.g., user engagement, safety) of a conversation is important and can only be exactly known at the end of the conversation. To maximize its expected quality, conversation planning reasons about the stochastic transitions within a conversation to select the optimal LLM response at each turn. Existing simulation-based conversation planning algorithms typically select the optimal response by simulating future conversations with a large number of LLM queries at every turn. However, this process is extremely time-consuming and hence impractical for real-time conversations. This paper presents a novel approach called Semantic space COnversation Planning with improved Efficiency (SCOPE) that exploits the dense semantic representation of conversations to perform conversation planning efficiently. In particular, SCOPE models the stochastic transitions in conversation semantics and their associated rewards to plan entirely within the semantic space. This allows us to select the optimal LLM response at every conversation turn without needing additional LLM queries for simulation. As a result, SCOPE can perform conversation planning 70 times faster than conventional simulation-based planning algorithms when applied to a wide variety of conversation starters and two reward functions seen in the real world, yet achieving a higher reward within a practical planning budget. Our code can be found at: https://github.com/chenzhiliang94/convo-plan-SCOPE.
On the Adversarial Risk of Test Time Adaptation: An Investigation into Realistic Test-Time Data Poisoning
Oct 07, 2024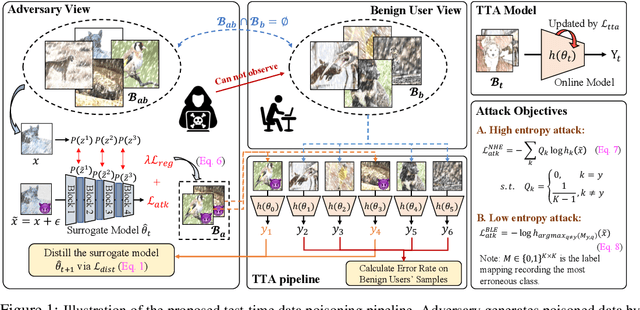



Test-time adaptation (TTA) updates the model weights during the inference stage using testing data to enhance generalization. However, this practice exposes TTA to adversarial risks. Existing studies have shown that when TTA is updated with crafted adversarial test samples, also known as test-time poisoned data, the performance on benign samples can deteriorate. Nonetheless, the perceived adversarial risk may be overstated if the poisoned data is generated under overly strong assumptions. In this work, we first review realistic assumptions for test-time data poisoning, including white-box versus grey-box attacks, access to benign data, attack budget, and more. We then propose an effective and realistic attack method that better produces poisoned samples without access to benign samples, and derive an effective in-distribution attack objective. We also design two TTA-aware attack objectives. Our benchmarks of existing attack methods reveal that the TTA methods are more robust than previously believed. In addition, we analyze effective defense strategies to help develop adversarially robust TTA methods.
Data Distribution Valuation
Oct 06, 2024
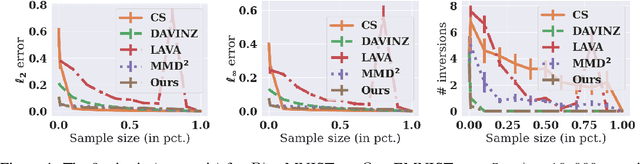

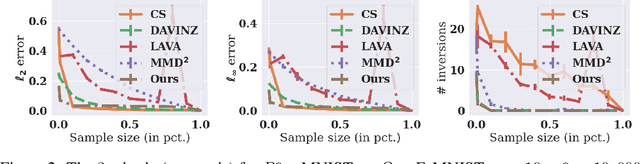
Data valuation is a class of techniques for quantitatively assessing the value of data for applications like pricing in data marketplaces. Existing data valuation methods define a value for a discrete dataset. However, in many use cases, users are interested in not only the value of the dataset, but that of the distribution from which the dataset was sampled. For example, consider a buyer trying to evaluate whether to purchase data from different vendors. The buyer may observe (and compare) only a small preview sample from each vendor, to decide which vendor's data distribution is most useful to the buyer and purchase. The core question is how should we compare the values of data distributions from their samples? Under a Huber characterization of the data heterogeneity across vendors, we propose a maximum mean discrepancy (MMD)-based valuation method which enables theoretically principled and actionable policies for comparing data distributions from samples. We empirically demonstrate that our method is sample-efficient and effective in identifying valuable data distributions against several existing baselines, on multiple real-world datasets (e.g., network intrusion detection, credit card fraud detection) and downstream applications (classification, regression).