 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Aware Classroom Quality Assessment Leveraging IoT-Based Real-Time Student Monitoring
Mar 17, 2026This study presents high-throughput, real-time multi-agent affective computing framework designed to enhance classroom learning through emotional state monitoring. As large classroom sizes and limited teacher student interaction increasingly challenge educators, there is a growing need for scalable, data-driven tools capable of capturing students' emotional and engagement patterns in real time. The system was evaluated using the Classroom Emotion Dataset, consisting of 1,500 labeled images and 300 classroom detection videos. Tailored for IoT devices, the system addresses load balancing and latency challenges through efficient real-time processing. Field testing was conducted across three educational institutions in a large metropolitan area: a primary school (hereafter school A), a secondary school (school B), and a high school (school C). The system demonstrated robust performance, detecting up to 50 faces at 25 FPS and achieving 88% overall accuracy in classifying classroom engagement states. Implementation results showed positive outcomes, with favorable feedback from students, teachers, and parents regarding improved classroom interaction and teaching adaptation. Key contributions of this research include establishing a practical, IoT-based framework for emotion-aware learning environments and introducing the 'Classroom Emotion Dataset' to facilitate further validation and research.
Uncertainty Quantification for Multimodal Large Language Models with Incoherence-adjusted Semantic Volume
Feb 27, 2026Despite their capabilities, Multimodal Large Language Models (MLLMs) may produce plausible but erroneous outputs, hindering reliable deployment. Accurate uncertainty metrics could enable escalation of unreliable queries to human experts or larger models for improved performance. However, existing uncertainty metrics have practical constraints, such as being designed only for specific modalities, reliant on external tools, or computationally expensive. We introduce UMPIRE, a training-free uncertainty quantification framework for MLLMs that works efficiently across various input and output modalities without external tools, relying only on the models' own internal modality features. UMPIRE computes the incoherence-adjusted semantic volume of sampled MLLM responses for a given task instance, effectively capturing both the global semantic diversity of samples and the local incoherence of responses based on internal model confidence. We propose uncertainty desiderata for MLLMs and provide theoretical analysis motivating UMPIRE's design. Extensive experiments show that UMPIRE consistently outperforms baseline metrics in error detection and uncertainty calibration across image, audio, and video-text benchmarks, including adversarial and out-of-distribution settings. We also demonstrate UMPIRE's generalization to non-text output tasks, including image and audio generation.
LLMs Are Biased Towards Output Formats! Systematically Evaluating and Mitigating Output Format Bias of LLMs
Aug 16, 2024We present the first systematic evaluation examining format bias in performance of large language models (LLMs). Our approach distinguishes between two categories of an evaluation metric under format constraints to reliably and accurately assess performance: one measures performance when format constraints are adhered to, while the other evaluates performance regardless of constraint adherence. We then define a metric for measuring the format bias of LLMs and establish effective strategies to reduce it. Subsequently, we present our empirical format bias evaluation spanning four commonly used categories -- multiple-choice question-answer, wrapping, list, and mapping -- covering 15 widely-used formats. Our evaluation on eight generation tasks uncovers significant format bias across state-of-the-art LLMs. We further discover that improving the format-instruction following capabilities of LLMs across formats potentially reduces format bias. Based on our evaluation findings, we study prompting and fine-tuning with synthesized format data techniques to mitigate format bias. Our methods successfully reduce the variance in ChatGPT's performance among wrapping formats from 235.33 to 0.71 (%$^2$).
Waterfall: Framework for Robust and Scalable Text Watermarking
Jul 05, 2024Protecting intellectual property (IP) of text such as articles and code is increasingly important, especially as sophisticated attacks become possible, such as paraphrasing by large language models (LLMs) or even unauthorized training of LLMs on copyrighted text to infringe such IP. However, existing text watermarking methods are not robust enough against such attacks nor scalable to millions of users for practical implementation. In this paper, we propose Waterfall, the first training-free framework for robust and scalable text watermarking applicable across multiple text types (e.g., articles, code) and languages supportable by LLMs, for general text and LLM data provenance. Waterfall comprises several key innovations, such as being the first to use LLM as paraphrasers for watermarking along with a novel combination of techniques that are surprisingly effective in achieving robust verifiability and scalability. We empirically demonstrate that Waterfall achieves significantly better scalability, robust verifiability, and computational efficiency compared to SOTA article-text watermarking methods, and also showed how it could be directly applied to the watermarking of code.
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024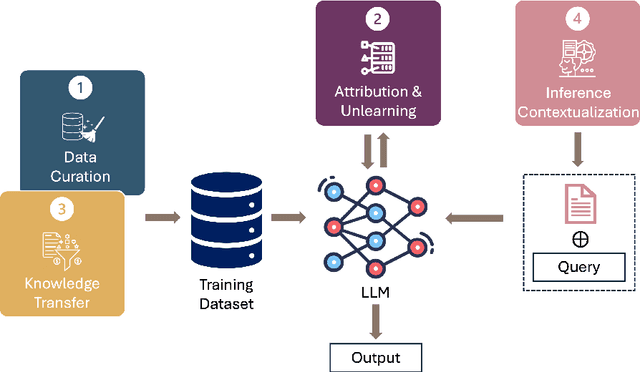
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Recognizing Families through Images with Pretrained Encoder
May 24, 2020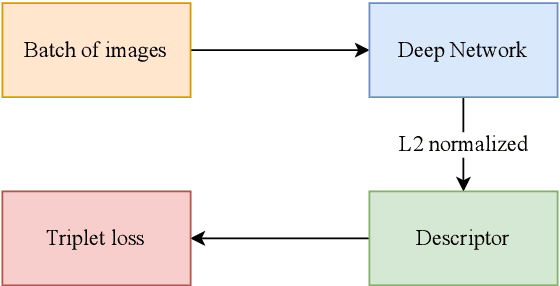
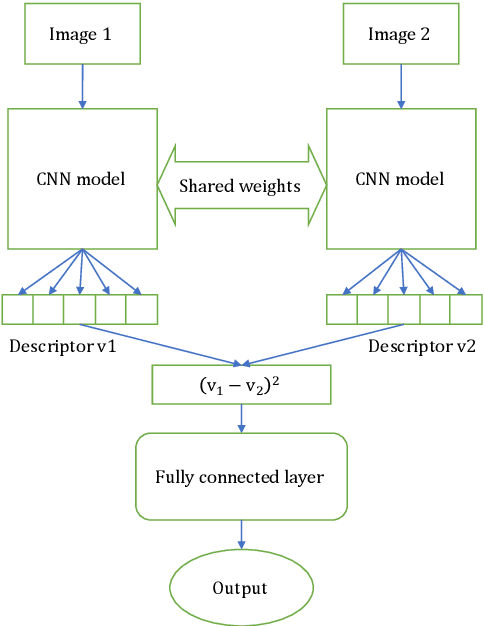


Kinship verification and kinship retrieval are emerging tasks in computer vision. Kinship verification aims at determining whether two facial images are from related people or not, while kinship retrieval is the task of retrieving possible related facial images to a person from a gallery of images. They introduce unique challenges because of the hidden relations and features that carry inherent characteristics between the facial images. We employ 3 methods, FaceNet, Siamese VGG-Face, and a combination of FaceNet and VGG-Face models as feature extractors, to achieve the 9th standing for kinship verification and the 5th standing for kinship retrieval in the Recognizing Family in The Wild 2020 competition. We then further experimented using StyleGAN2 as another encoder, with no improvement in the result.