 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Multi-Armed Bandits with Limited Control Variates
Mar 02, 2026Motivated by wireless networks where interference or channel state estimates provide partial insight into throughput, we study a variant of the classical stochastic multi-armed bandit problem in which the learner has limited access to auxiliary information. Recent work has shown that such auxiliary information, when available as control variates, can be used to get tighter confidence bounds, leading to lower regret. However, existing works assume that control variates are available in every round, which may not be realistic in several real-life scenarios. To address this, we propose UCB-LCV, an upper confidence bound (UCB) based algorithm that effectively combines the estimators obtained from rewards and control variates. When there is no control variate, UCB-LCV leads to a novel algorithm that we call UCB-NORMAL, outperforming its existing algorithms for the standard MAB setting with normally distributed rewards. Finally, we discuss variants of the proposed UCB-LCV that apply to general distributions and experimentally demonstrate that UCB-LCV outperforms existing bandit algorithms.
BarrierSteer: LLM Safety via Learning Barrier Steering
Feb 23, 2026Despite the state-of-the-art performance of large language models (LLMs) across diverse tasks, their susceptibility to adversarial attacks and unsafe content generation remains a major obstacle to deployment, particularly in high-stakes settings. Addressing this challenge requires safety mechanisms that are both practically effective and supported by rigorous theory. We introduce BarrierSteer, a novel framework that formalizes response safety by embedding learned non-linear safety constraints directly into the model's latent representation space. BarrierSteer employs a steering mechanism based on Control Barrier Functions (CBFs) to efficiently detect and prevent unsafe response trajectories during inference with high precision. By enforcing multiple safety constraints through efficient constraint merging, without modifying the underlying LLM parameters, BarrierSteer preserves the model's original capabilities and performance. We provide theoretical results establishing that applying CBFs in latent space offers a principled and computationally efficient approach to enforcing safety. Our experiments across multiple models and datasets show that BarrierSteer substantially reduces adversarial success rates, decreases unsafe generations, and outperforms existing methods.
Uncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
COBRA: Contextual Bandit Algorithm for Ensuring Truthful Strategic Agents
May 29, 2025This paper considers a contextual bandit problem involving multiple agents, where a learner sequentially observes the contexts and the agent's reported arms, and then selects the arm that maximizes the system's overall reward. Existing work in contextual bandits assumes that agents truthfully report their arms, which is unrealistic in many real-life applications. For instance, consider an online platform with multiple sellers; some sellers may misrepresent product quality to gain an advantage, such as having the platform preferentially recommend their products to online users. To address this challenge, we propose an algorithm, COBRA, for contextual bandit problems involving strategic agents that disincentivize their strategic behavior without using any monetary incentives, while having incentive compatibility and a sub-linear regret guarantee. Our experimental results also validate the different performance aspects of our proposed algorithm.
ActiveDPO: Active Direct Preference Optimization for Sample-Efficient Alignment
May 25, 2025
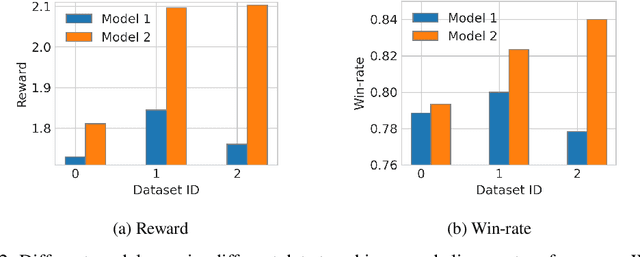

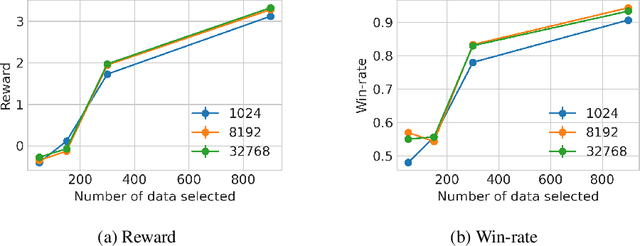
The recent success of using human preferences to align large language models (LLMs) has significantly improved their performance in various downstream tasks like question answering, mathematical reasoning, and code generation. However,3 achieving effective LLM alignment depends on high-quality human preference datasets. Collecting these datasets requires human preference annotation, which is costly and resource-intensive, necessitating efficient active data selection methods. Existing methods either lack a strong theoretical foundation or depend on restrictive reward function assumptions (e.g., linearity). To this end, we propose an algorithm, ActiveDPO, that uses a theoretically grounded data selection criterion for non-linear reward functions while directly leveraging the LLM itself to parameterize the reward model that is used for active data selection. As a result, ActiveDPO explicitly accounts for the influence of LLM on data selection, unlike methods that select the data without considering the LLM that is being aligned, thereby leading to more effective and efficient data collection. Extensive experiments show that ActiveDPO outperforms existing methods across various models and datasets.
Active Human Feedback Collection via Neural Contextual Dueling Bandits
Apr 16, 2025Collecting human preference feedback is often expensive, leading recent works to develop principled algorithms to select them more efficiently. However, these works assume that the underlying reward function is linear, an assumption that does not hold in many real-life applications, such as online recommendation and LLM alignment. To address this limitation, we propose Neural-ADB, an algorithm based on the neural contextual dueling bandit framework that provides a principled and practical method for collecting human preference feedback when the underlying latent reward function is non-linear. We theoretically show that when preference feedback follows the Bradley-Terry-Luce model, the worst sub-optimality gap of the policy learned by Neural-ADB decreases at a sub-linear rate as the preference dataset increases. Our experimental results on problem instances derived from synthetic preference datasets further validate the effectiveness of Neural-ADB.
TETRIS: Optimal Draft Token Selection for Batch Speculative Decoding
Feb 21, 2025We propose TETRIS, a novel method that optimizes the total throughput of batch speculative decoding in multi-request settings. Unlike existing methods that optimize for a single request or a group of requests as a whole, TETRIS actively selects the most promising draft tokens (for every request in a batch) to be accepted when verified in parallel, resulting in fewer rejected tokens and hence less wasted computing resources. Such an effective resource utilization to achieve fast inference in large language models (LLMs) is especially important to service providers with limited inference capacity. Compared to baseline speculative decoding, TETRIS yields a consistently higher acceptance rate and more effective utilization of the limited inference capacity. We show theoretically and empirically that TETRIS outperforms baseline speculative decoding and existing methods that dynamically select draft tokens, leading to a more efficient batch inference in LLMs.
Online Fair Division with Contextual Bandits
Aug 23, 2024This paper considers a novel online fair division problem involving multiple agents in which a learner observes an indivisible item that has to be irrevocably allocated to one of the agents while satisfying a fairness and efficiency constraint. Existing algorithms assume a small number of items with a sufficiently large number of copies, which ensures a good utility estimation for all item-agent pairs. However, such an assumption may not hold in many real-life applications, e.g., an online platform that has a large number of users (items) who only use the platform's service providers (agents) a few times (a few copies of items), which makes it difficult to estimate the utility for all item-agent pairs. To overcome this challenge, we model the online fair division problem using contextual bandits, assuming the utility is an unknown function of the item-agent features. We then propose algorithms for online fair division with sub-linear regret guarantees. Our experimental results also verify the different performance aspects of the proposed algorithms.
Neural Dueling Bandits
Jul 24, 2024Contextual dueling bandit is used to model the bandit problems, where a learner's goal is to find the best arm for a given context using observed noisy preference feedback over the selected arms for the past contexts. However, existing algorithms assume the reward function is linear, which can be complex and non-linear in many real-life applications like online recommendations or ranking web search results. To overcome this challenge, we use a neural network to estimate the reward function using preference feedback for the previously selected arms. We propose upper confidence bound- and Thompson sampling-based algorithms with sub-linear regret guarantees that efficiently select arms in each round. We then extend our theoretical results to contextual bandit problems with binary feedback, which is in itself a non-trivial contribution. Experimental results on the problem instances derived from synthetic datasets corroborate our theoretical results.
Understanding the Relationship between Prompts and Response Uncertainty in Large Language Models
Jul 20, 2024Large language models (LLMs) are widely used in decision-making, but their reliability, especially in critical tasks like healthcare, is not well-established. Therefore, understanding how LLMs reason and make decisions is crucial for their safe deployment. This paper investigates how the uncertainty of responses generated by LLMs relates to the information provided in the input prompt. Leveraging the insight that LLMs learn to infer latent concepts during pretraining, we propose a prompt-response concept model that explains how LLMs generate responses and helps understand the relationship between prompts and response uncertainty. We show that the uncertainty decreases as the prompt's informativeness increases, similar to epistemic uncertainty. Our detailed experimental results on real datasets validate our proposed model.