 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric AI in the Age of Large Language Models
Jun 20, 2024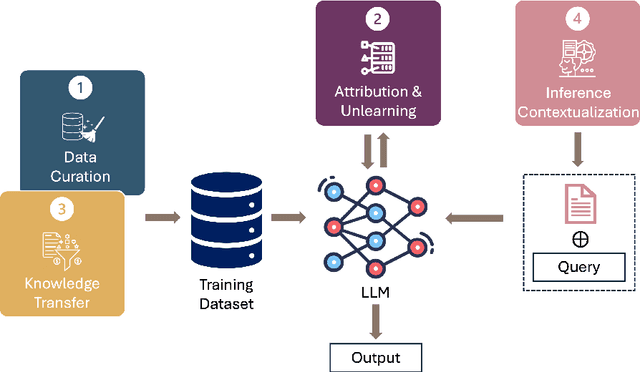
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Robustifying and Boosting Training-Free Neural Architecture Search
Mar 12, 2024



Neural architecture search (NAS) has become a key component of AutoML and a standard tool to automate the design of deep neural networks. Recently, training-free NAS as an emerging paradigm has successfully reduced the search costs of standard training-based NAS by estimating the true architecture performance with only training-free metrics. Nevertheless, the estimation ability of these metrics typically varies across different tasks, making it challenging to achieve robust and consistently good search performance on diverse tasks with only a single training-free metric. Meanwhile, the estimation gap between training-free metrics and the true architecture performances limits training-free NAS to achieve superior performance. To address these challenges, we propose the robustifying and boosting training-free NAS (RoBoT) algorithm which (a) employs the optimized combination of existing training-free metrics explored from Bayesian optimization to develop a robust and consistently better-performing metric on diverse tasks, and (b) applies greedy search, i.e., the exploitation, on the newly developed metric to bridge the aforementioned gap and consequently to boost the search performance of standard training-free NAS further. Remarkably, the expected performance of our RoBoT can be theoretically guaranteed, which improves over the existing training-free NAS under mild conditions with additional interesting insights. Our extensive experiments on various NAS benchmark tasks yield substantial empirical evidence to support our theoretical results.
DialMed: A Dataset for Dialogue-based Medication Recommendation
Feb 22, 2022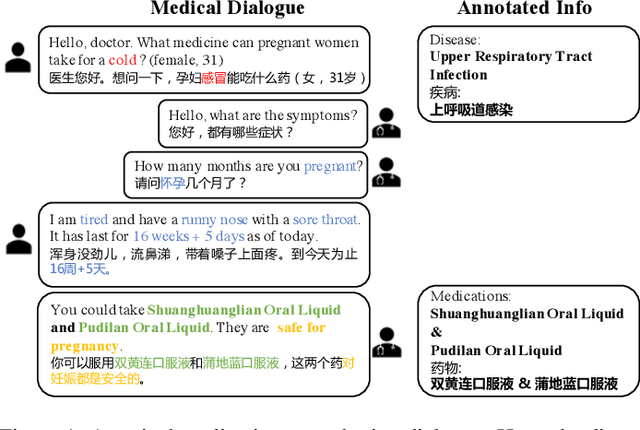

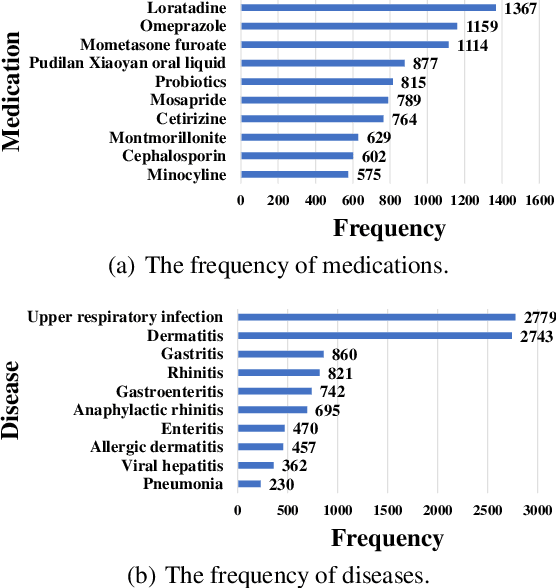

Medication recommendation is a crucial task for intelligent healthcare systems. Previous studies mainly recommend medications with electronic health records(EHRs). However, some details of interactions between doctors and patients may be ignored in EHRs, which are essential for automatic medication recommendation. Therefore, we make the first attempt to recommend medications with the conversations between doctors and patients. In this work, we construct DialMed, the first high-quality dataset for medical dialogue-based medication recommendation task. It contains 11,996 medical dialogues related to 16 common diseases from 3 departments and 70 corresponding common medications. Furthermore, we propose a Dialogue structure and Disease knowledge aware Network(DDN), where a graph attention network is utilized to model the dialogue structure and the knowledge graph is used to introduce external disease knowledge. The extensive experimental results demonstrate that the proposed method is a promising solution to recommend medications with medical dialogues. The dataset and code are available at https://github.com/Hhhhhhhzf/DialMed.
DeepVisualInsight: Time-Travelling Visualization for Spatio-Temporal Causality of Deep Classification Training
Dec 31, 2021
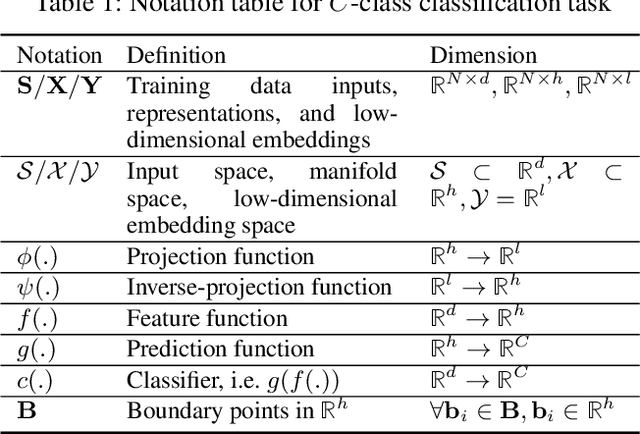
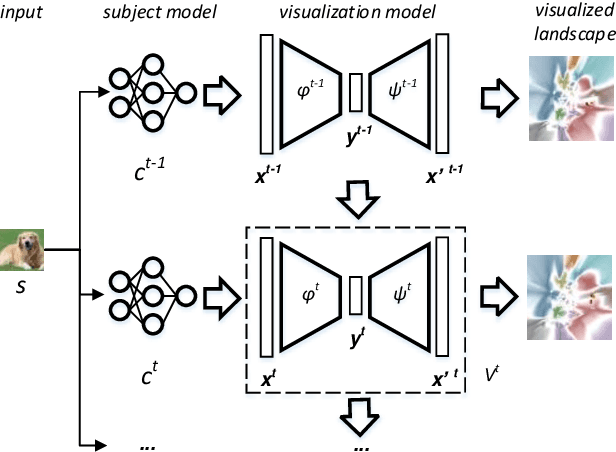
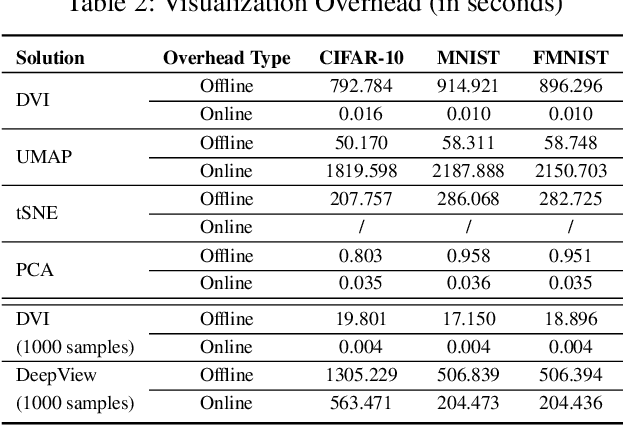
Understanding how the predictions of deep learning models are formed during the training process is crucial to improve model performance and fix model defects, especially when we need to investigate nontrivial training strategies such as active learning, and track the root cause of unexpected training results such as performance degeneration. In this work, we propose a time-travelling visual solution DeepVisualInsight (DVI), aiming to manifest the spatio-temporal causality while training a deep learning image classifier. The spatio-temporal causality demonstrates how the gradient-descent algorithm and various training data sampling techniques can influence and reshape the layout of learnt input representation and the classification boundaries in consecutive epochs. Such causality allows us to observe and analyze the whole learning process in the visible low dimensional space. Technically, we propose four spatial and temporal properties and design our visualization solution to satisfy them. These properties preserve the most important information when inverse-)projecting input samples between the visible low-dimensional and the invisible high-dimensional space, for causal analyses. Our extensive experiments show that, comparing to baseline approaches, we achieve the best visualization performance regarding the spatial/temporal properties and visualization efficiency. Moreover, our case study shows that our visual solution can well reflect the characteristics of various training scenarios, showing good potential of DVI as a debugging tool for analyzing deep learning training processes.