 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Truthfulness and Collaborative Fairness in Bayesian Learning
May 12, 2026Collaborative machine learning involves training high-quality models using datasets from a number of sources. To incentivize sources to share data, existing data valuation methods fairly reward each source based on its data submitted as is. However, as these methods do not verify nor incentivize data truthfulness, the sources can manipulate their data (e.g., by submitting duplicated or noisy data) to artificially increase their valuations and rewards or prevent others from benefiting. This paper presents the first mechanism that provably ensures (F) collaborative fairness and incentivizes (T) truthfulness at equilibrium for Bayesian models. Our mechanism combines semivalues (e.g., Shapley value), which ensure fairness, and a truthful data valuation function (DVF) based on a validation set that is unknown to the sources. As semivalues are influenced by others' data, we introduce an additional condition to prove that a source can maximize its expected data values in coalitions and semivalues by submitting a dataset that captures its true knowledge. Additionally, we discuss the implications and suitable relaxations of (F) and (T) when the mediator has a limited budget for rewards or lacks a validation set. Our theoretical findings are validated on synthetic and real-world datasets.
A Single-Sample Polylogarithmic Regret Bound for Nonstationary Online Linear Programming
Mar 15, 2026We study nonstationary Online Linear Programming (OLP), where $n$ orders arrive sequentially with reward-resource consumption pairs that form a sequence of independent, but not necessarily identically distributed, random vectors. At the beginning of the planning horizon, the decision-maker is provided with a resource endowment that is sufficient to fulfill a significant portion of the requests. The decision-maker seeks to maximize the expected total reward by making immediate and irrevocable acceptance or rejection decisions for each order, subject to this resource endowment. We focus on the challenging single-sample setting, where only one sample from each of the $n$ distributions is available at the start of the planning horizon. We propose a novel re-solving algorithm that integrates a dynamic programming perspective with the dual-based frameworks traditionally employed in stationary environments. In the large-resource regime, where the resource endowment scales linearly with the number of orders, we prove that our algorithm achieves $O((\log n)^2)$ regret across a broad class of nonstationary distribution sequences. Our results demonstrate that polylogarithmic regret is attainable even under significant environmental shifts and minimal data availability, bridging the gap between stationary OLP and more volatile real-world resource allocation problems.
Is Multi-Distribution Learning as Easy as PAC Learning: Sharp Rates with Bounded Label Noise
Feb 24, 2026Towards understanding the statistical complexity of learning from heterogeneous sources, we study the problem of multi-distribution learning. Given $k$ data sources, the goal is to output a classifier for each source by exploiting shared structure to reduce sample complexity. We focus on the bounded label noise setting to determine whether the fast $1/ε$ rates achievable in single-task learning extend to this regime with minimal dependence on $k$. Surprisingly, we show that this is not the case. We demonstrate that learning across $k$ distributions inherently incurs slow rates scaling with $k/ε^2$, even under constant noise levels, unless each distribution is learned separately. A key technical contribution is a structured hypothesis-testing framework that captures the statistical cost of certifying near-optimality under bounded noise-a cost we show is unavoidable in the multi-distribution setting. Finally, we prove that when competing with the stronger benchmark of each distribution's optimal Bayes error, the sample complexity incurs a \textit{multiplicative} penalty in $k$. This establishes a \textit{statistical} separation between random classification noise and Massart noise, highlighting a fundamental barrier unique to learning from multiple sources.
Choice-Model-Assisted Q-learning for Delayed-Feedback Revenue Management
Feb 02, 2026We study reinforcement learning for revenue management with delayed feedback, where a substantial fraction of value is determined by customer cancellations and modifications observed days after booking. We propose \emph{choice-model-assisted RL}: a calibrated discrete choice model is used as a fixed partial world model to impute the delayed component of the learning target at decision time. In the fixed-model deployment regime, we prove that tabular Q-learning with model-imputed targets converges to an $O(\varepsilon/(1-γ))$ neighborhood of the optimal Q-function, where $\varepsilon$ summarizes partial-model error, with an additional $O(t^{-1/2})$ sampling term. Experiments in a simulator calibrated from 61{,}619 hotel bookings (1{,}088 independent runs) show: (i) no statistically detectable difference from a maturity-buffer DQN baseline in stationary settings; (ii) positive effects under in-family parameter shifts, with significant gains in 5 of 10 shift scenarios after Holm--Bonferroni correction (up to 12.4\%); and (iii) consistent degradation under structural misspecification, where the choice model assumptions are violated (1.4--2.6\% lower revenue). These results characterize when partial behavioral models improve robustness under shift and when they introduce harmful bias.
Multi-Timescale Gradient Sliding for Distributed Optimization
Jun 18, 2025We propose two first-order methods for convex, non-smooth, distributed optimization problems, hereafter called Multi-Timescale Gradient Sliding (MT-GS) and its accelerated variant (AMT-GS). Our MT-GS and AMT-GS can take advantage of similarities between (local) objectives to reduce the communication rounds, are flexible so that different subsets (of agents) can communicate at different, user-picked rates, and are fully deterministic. These three desirable features are achieved through a block-decomposable primal-dual formulation, and a multi-timescale variant of the sliding method introduced in Lan et al. (2020), Lan (2016), where different dual blocks are updated at potentially different rates. To find an $\epsilon$-suboptimal solution, the complexities of our algorithms achieve optimal dependency on $\epsilon$: MT-GS needs $O(\overline{r}A/\epsilon)$ communication rounds and $O(\overline{r}/\epsilon^2)$ subgradient steps for Lipchitz objectives, and AMT-GS needs $O(\overline{r}A/\sqrt{\epsilon\mu})$ communication rounds and $O(\overline{r}/(\epsilon\mu))$ subgradient steps if the objectives are also $\mu$-strongly convex. Here, $\overline{r}$ measures the ``average rate of updates'' for dual blocks, and $A$ measures similarities between (subgradients of) local functions. In addition, the linear dependency of communication rounds on $A$ is optimal (Arjevani and Shamir 2015), thereby providing a positive answer to the open question whether such dependency is achievable for non-smooth objectives (Arjevani and Shamir 2015).
Learning with Exact Invariances in Polynomial Time
Feb 27, 2025We study the statistical-computational trade-offs for learning with exact invariances (or symmetries) using kernel regression. Traditional methods, such as data augmentation, group averaging, canonicalization, and frame-averaging, either fail to provide a polynomial-time solution or are not applicable in the kernel setting. However, with oracle access to the geometric properties of the input space, we propose a polynomial-time algorithm that learns a classifier with \emph{exact} invariances. Moreover, our approach achieves the same excess population risk (or generalization error) as the original kernel regression problem. To the best of our knowledge, this is the first polynomial-time algorithm to achieve exact (not approximate) invariances in this context. Our proof leverages tools from differential geometry, spectral theory, and optimization. A key result in our development is a new reformulation of the problem of learning under invariances as optimizing an infinite number of linearly constrained convex quadratic programs, which may be of independent interest.
Online Scheduling for LLM Inference with KV Cache Constraints
Feb 10, 2025
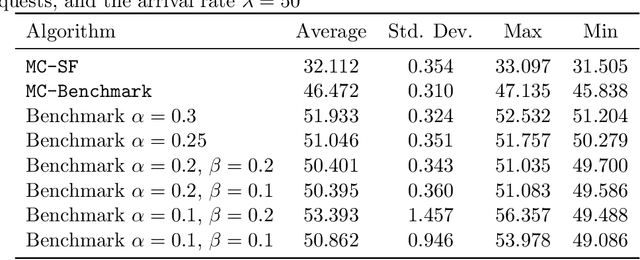
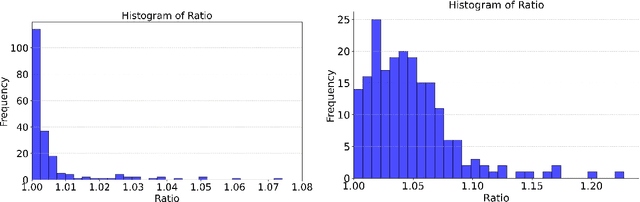
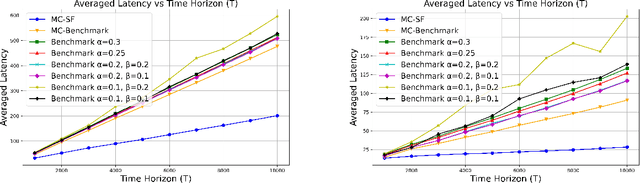
Large Language Model (LLM) inference, where a trained model generates text one word at a time in response to user prompts, is a computationally intensive process requiring efficient scheduling to optimize latency and resource utilization. A key challenge in LLM inference is the management of the Key-Value (KV) cache, which reduces redundant computations but introduces memory constraints. In this work, we model LLM inference with KV cache constraints theoretically and propose novel batching and scheduling algorithms that minimize inference latency while effectively managing the KV cache's memory. We analyze both semi-online and fully online scheduling models, and our results are threefold. First, we provide a polynomial-time algorithm that achieves exact optimality in terms of average latency in the semi-online prompt arrival model. Second, in the fully online case with a stochastic prompt arrival, we introduce an efficient online scheduling algorithm with constant regret. Third, we prove that no algorithm (deterministic or randomized) can achieve a constant competitive ratio in fully online adversarial settings. Our empirical evaluations on a public LLM inference dataset, using the Llama-70B model on A100 GPUs, show that our approach significantly outperforms benchmark algorithms used currently in practice, achieving lower latency while reducing energy consumption. Overall, our results offer a path toward more sustainable and cost-effective LLM deployment.
Neural Dueling Bandits
Jul 24, 2024Contextual dueling bandit is used to model the bandit problems, where a learner's goal is to find the best arm for a given context using observed noisy preference feedback over the selected arms for the past contexts. However, existing algorithms assume the reward function is linear, which can be complex and non-linear in many real-life applications like online recommendations or ranking web search results. To overcome this challenge, we use a neural network to estimate the reward function using preference feedback for the previously selected arms. We propose upper confidence bound- and Thompson sampling-based algorithms with sub-linear regret guarantees that efficiently select arms in each round. We then extend our theoretical results to contextual bandit problems with binary feedback, which is in itself a non-trivial contribution. Experimental results on the problem instances derived from synthetic datasets corroborate our theoretical results.
A Universal Class of Sharpness-Aware Minimization Algorithms
Jun 06, 2024Recently, there has been a surge in interest in developing optimization algorithms for overparameterized models as achieving generalization is believed to require algorithms with suitable biases. This interest centers on minimizing sharpness of the original loss function; the Sharpness-Aware Minimization (SAM) algorithm has proven effective. However, most literature only considers a few sharpness measures, such as the maximum eigenvalue or trace of the training loss Hessian, which may not yield meaningful insights for non-convex optimization scenarios like neural networks. Additionally, many sharpness measures are sensitive to parameter invariances in neural networks, magnifying significantly under rescaling parameters. Motivated by these challenges, we introduce a new class of sharpness measures in this paper, leading to new sharpness-aware objective functions. We prove that these measures are \textit{universally expressive}, allowing any function of the training loss Hessian matrix to be represented by appropriate hyperparameters. Furthermore, we show that the proposed objective functions explicitly bias towards minimizing their corresponding sharpness measures, and how they allow meaningful applications to models with parameter invariances (such as scale-invariances). Finally, as instances of our proposed general framework, we present \textit{Frob-SAM} and \textit{Det-SAM}, which are specifically designed to minimize the Frobenius norm and the determinant of the Hessian of the training loss, respectively. We also demonstrate the advantages of our general framework through extensive experiments.
Prompt Optimization with Human Feedback
May 27, 2024



Large language models (LLMs) have demonstrated remarkable performances in various tasks. However, the performance of LLMs heavily depends on the input prompt, which has given rise to a number of recent works on prompt optimization. However, previous works often require the availability of a numeric score to assess the quality of every prompt. Unfortunately, when a human user interacts with a black-box LLM, attaining such a score is often infeasible and unreliable. Instead, it is usually significantly easier and more reliable to obtain preference feedback from a human user, i.e., showing the user the responses generated from a pair of prompts and asking the user which one is preferred. Therefore, in this paper, we study the problem of prompt optimization with human feedback (POHF), in which we aim to optimize the prompt for a black-box LLM using only human preference feedback. Drawing inspiration from dueling bandits, we design a theoretically principled strategy to select a pair of prompts to query for preference feedback in every iteration, and hence introduce our algorithm named automated POHF (APOHF). We apply our APOHF algorithm to various tasks, including optimizing user instructions, prompt optimization for text-to-image generative models, and response optimization with human feedback (i.e., further refining the response using a variant of our APOHF). The results demonstrate that our APOHF can efficiently find a good prompt using a small number of preference feedback instances. Our code can be found at \url{https://github.com/xqlin98/APOHF}.