 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Scheduling for LLM Inference with KV Cache Constraints
Paper and Code

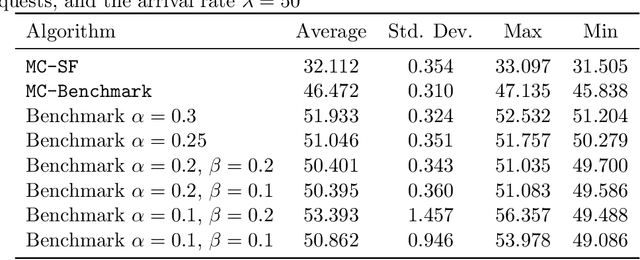
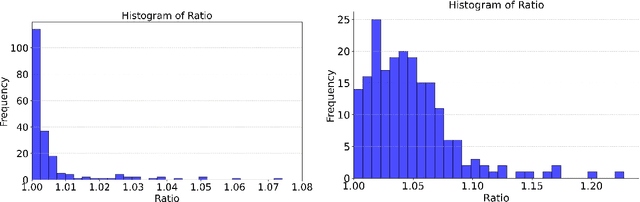
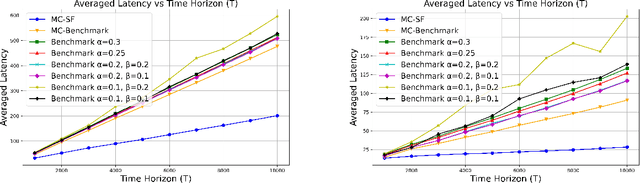
Large Language Model (LLM) inference, where a trained model generates text one word at a time in response to user prompts, is a computationally intensive process requiring efficient scheduling to optimize latency and resource utilization. A key challenge in LLM inference is the management of the Key-Value (KV) cache, which reduces redundant computations but introduces memory constraints. In this work, we model LLM inference with KV cache constraints theoretically and propose novel batching and scheduling algorithms that minimize inference latency while effectively managing the KV cache's memory. We analyze both semi-online and fully online scheduling models, and our results are threefold. First, we provide a polynomial-time algorithm that achieves exact optimality in terms of average latency in the semi-online prompt arrival model. Second, in the fully online case with a stochastic prompt arrival, we introduce an efficient online scheduling algorithm with constant regret. Third, we prove that no algorithm (deterministic or randomized) can achieve a constant competitive ratio in fully online adversarial settings. Our empirical evaluations on a public LLM inference dataset, using the Llama-70B model on A100 GPUs, show that our approach significantly outperforms benchmark algorithms used currently in practice, achieving lower latency while reducing energy consumption. Overall, our results offer a path toward more sustainable and cost-effective LLM deployment.