 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarMem: A Training-Free Polarized Latent Graph Memory for Verifiable Multimodal Agents
Jan 31, 2026As multimodal agents evolve from passive observers to long-horizon decision-makers, they require memory systems that provide not just information availability but logical verifiability. A fundamental limitation of current architectures is the epistemic asymmetry inherent in probabilistic vision-language models and dense associative memories: they conflate semantic affinity with factual existence and structurally fail to encode negative constraints. To this end, we introduce PolarMem, a training-free Polarized Latent Graph Memory designed to ground agent reasoning in verifiable evidence. PolarMem transforms fuzzy perceptual likelihoods into discrete logical constraints through non-parametric distributional partitioning. Furthermore, it employs a polarized graph topology with orthogonal inhibitory connections to explicitly store verified negation as a primary cognitive state. At inference time, we enforce a logic-dominant retrieval paradigm, suppressing hallucinatory patterns that violate negative constraints. Extensive evaluation across eight frozen Vision--Language Models and six benchmarks demonstrates that PolarMem functions as a robust cognitive system, establishing a foundation for verifiable multimodal agents. Our code is available at https://github.com/czs-ict/PolarMem.
Theoretically Optimal Attention/FFN Ratios in Disaggregated LLM Serving
Jan 29, 2026Attention-FFN disaggregation (AFD) is an emerging architecture for LLM decoding that separates state-heavy, KV-cache-dominated Attention computation from stateless, compute-intensive FFN computation, connected by per-step communication. While AFD enables independent scaling of memory and compute resources, its performance is highly sensitive to the Attention/FFN provisioning ratio: mis-sizing induces step-level blocking and costly device idle time. We develop a tractable analytical framework for sizing AFD bundles in an $r$A-$1$F topology, where the key difficulty is that Attention-side work is nonstationary-token context grows and requests are continuously replenished with random lengths-while FFN work is stable given the aggregated batch. Using a probabilistic workload model, we derive closed-form rules for the optimal A/F ratio that maximize average throughput per instance across the system. A trace-calibrated AFD simulator validates the theory: across workloads, the theoretical optimal A/F ratio matches the simulation-optimal within 10%, and consistently reduces idle time.
A Universal Load Balancing Principle and Its Application to Large Language Model Serving
Jan 25, 2026Load balancing-the allocation of work across parallel resources to reduce delay, energy and cost-is a pervasive challenge in science and engineering, from large-scale simulation and data processing to cloud and manufacturing operations. Motivated by the emerging bottleneck in large language model (LLM) serving, we study a particularly stringent regime of load balancing that arises in barrier-synchronized, stateful systems: work cannot be freely migrated and progress is gated by the slowest participant at each step, so heterogeneity and temporal drift in workloads create persistent stragglers and substantial idle time. LLM serving under data-parallel decoding provides a prominent modern instance: in production traces, barrier-induced idle can exceed 40% of compute time per decode step. Here we develop a universal load-balancing principle, which admits a step-wise finite-horizon integer-optimization formulation and yields worst-case guarantees: across LLM decode models and a broader class of non-decreasing workload drift processes, it reduces long-run imbalance by a factor that grows with batch size and system scale. Extensive experiments corroborate the theory, showing substantial improvements in throughput and latency together with reductions in energy consumption. These results provide a general, theoretically grounded framework for load balancing, with immediate implications for sustainable LLM serving and broad relevance to other synchronization-gated resource-allocation problems.
ICPO: Illocution-Calibrated Policy Optimization for Multi-Turn Conversation
Jan 20, 2026Large Language Models (LLMs) in multi-turn conversations often suffer from a ``lost-in-conversation'' phenomenon, where they struggle to recover from early incorrect assumptions, particularly when users provide ambiguous initial instructions. We find that standard post-training techniques like Reinforcement Learning with Verifiable Rewards (RLVR) exacerbate this issue by rewarding confident, direct answers, thereby inducing overconfidence and discouraging the model from seeking clarification. To address this, we propose Illocution-Calibrated Policy Optimization (ICPO), a novel training framework that sensitizes the model to instruction ambiguity. ICPO augments the training corpus with underspecified prompts and conditions the reward signal on the user's illocutionary intent, rewarding the model for expressing uncertainty or asking for clarification when faced with ambiguity. Experiments demonstrate that ICPO fosters appropriate humility, yielding a substantial average improvement of 75\% in multi-turn conversation, while preserving robust performance on single-turn benchmarks. Our work presents a practical path toward more robust and collaborative conversational AI that can better navigate the nuances of human interaction.
Adaptively Robust LLM Inference Optimization under Prediction Uncertainty
Aug 20, 2025



We study the problem of optimizing Large Language Model (LLM) inference scheduling to minimize total latency. LLM inference is an online and multi-task service process and also heavily energy consuming by which a pre-trained LLM processes input requests and generates output tokens sequentially. Therefore, it is vital to improve its scheduling efficiency and reduce the power consumption while a great amount of prompt requests are arriving. A key challenge in LLM inference scheduling is that while the prompt length is known upon arrival, the output length, which critically impacts memory usage and processing time, is unknown. To address this uncertainty, we propose algorithms that leverage machine learning to predict output lengths, assuming the prediction provides an interval classification (min-max range) for each request. We first design a conservative algorithm, $\mathcal{A}_{\max}$, which schedules requests based on the upper bound of predicted output lengths to prevent memory overflow. However, this approach is overly conservative: as prediction accuracy decreases, performance degrades significantly due to potential overestimation. To overcome this limitation, we propose $\mathcal{A}_{\min}$, an adaptive algorithm that initially treats the predicted lower bound as the output length and dynamically refines this estimate during inferencing. We prove that $\mathcal{A}_{\min}$ achieves a log-scale competitive ratio. Through numerical simulations, we demonstrate that $\mathcal{A}_{\min}$ often performs nearly as well as the hindsight scheduler, highlighting both its efficiency and robustness in practical scenarios. Moreover, $\mathcal{A}_{\min}$ relies solely on the lower bound of the prediction interval--an advantageous design choice since upper bounds on output length are typically more challenging to predict accurately.
LLM Serving Optimization with Variable Prefill and Decode Lengths
Aug 08, 2025We study the problem of serving LLM (Large Language Model) requests where each request has heterogeneous prefill and decode lengths. In LLM serving, the prefill length corresponds to the input prompt length, which determines the initial memory usage in the KV cache. The decode length refers to the number of output tokens generated sequentially, with each additional token increasing the KV cache memory usage by one unit. Given a set of n requests, our goal is to schedule and process them to minimize the total completion time. We show that this problem is NP-hard due to the interplay of batching, placement constraints, precedence relationships, and linearly increasing memory usage. We then analyze commonly used scheduling strategies in practice, such as First-Come-First-Serve (FCFS) and Shortest-First (SF), and prove that their competitive ratios scale up sublinearly with the memory limit-a significant drawback in real-world settings where memory demand is large. To address this, we propose a novel algorithm based on a new selection metric that efficiently forms batches over time. We prove that this algorithm achieves a constant competitive ratio. Finally, we develop and evaluate a few algorithm variants inspired by this approach, including dynamic programming variants, local search methods, and an LP-based scheduler, demonstrating through comprehensive simulations that they outperform standard baselines while maintaining computational efficiency.
LRFusionPR: A Polar BEV-Based LiDAR-Radar Fusion Network for Place Recognition
Apr 27, 2025In autonomous driving, place recognition is critical for global localization in GPS-denied environments. LiDAR and radar-based place recognition methods have garnered increasing attention, as LiDAR provides precise ranging, whereas radar excels in adverse weather resilience. However, effectively leveraging LiDAR-radar fusion for place recognition remains challenging. The noisy and sparse nature of radar data limits its potential to further improve recognition accuracy. In addition, heterogeneous radar configurations complicate the development of unified cross-modality fusion frameworks. In this paper, we propose LRFusionPR, which improves recognition accuracy and robustness by fusing LiDAR with either single-chip or scanning radar. Technically, a dual-branch network is proposed to fuse different modalities within the unified polar coordinate bird's eye view (BEV) representation. In the fusion branch, cross-attention is utilized to perform cross-modality feature interactions. The knowledge from the fusion branch is simultaneously transferred to the distillation branch, which takes radar as its only input to further improve the robustness. Ultimately, the descriptors from both branches are concatenated, producing the multimodal global descriptor for place retrieval. Extensive evaluations on multiple datasets demonstrate that our LRFusionPR achieves accurate place recognition, while maintaining robustness under varying weather conditions. Our open-source code will be released at https://github.com/QiZS-BIT/LRFusionPR.
Industrial Internet Robot Collaboration System and Edge Computing Optimization
Apr 03, 2025In a complex environment, for a mobile robot to safely and collision - free avoid all obstacles, it poses high requirements for its intelligence level. Given that the information such as the position and geometric characteristics of obstacles is random, the control parameters of the robot, such as velocity and angular velocity, are also prone to random deviations. To address this issue in the framework of the Industrial Internet Robot Collaboration System, this paper proposes a global path control scheme for mobile robots based on deep learning. First of all, the dynamic equation of the mobile robot is established. According to the linear velocity and angular velocity of the mobile robot, its motion behaviors are divided into obstacle - avoidance behavior, target - turning behavior, and target approaching behavior. Subsequently, the neural network method in deep learning is used to build a global path planning model for the robot. On this basis, a fuzzy controller is designed with the help of a fuzzy control algorithm to correct the deviations that occur during path planning, thereby achieving optimized control of the robot's global path. In addition, considering edge computing optimization, the proposed model can process local data at the edge device, reducing the communication burden between the robot and the central server, and improving the real time performance of path planning. The experimental results show that for the mobile robot controlled by the research method in this paper, the deviation distance of the path angle is within 5 cm, the deviation convergence can be completed within 10 ms, and the planned path is shorter. This indicates that the proposed scheme can effectively improve the global path planning ability of mobile robots in the industrial Internet environment and promote the collaborative operation of robots through edge computing optimization.
SegLocNet: Multimodal Localization Network for Autonomous Driving via Bird's-Eye-View Segmentation
Feb 28, 2025Robust and accurate localization is critical for autonomous driving. Traditional GNSS-based localization methods suffer from signal occlusion and multipath effects in urban environments. Meanwhile, methods relying on high-definition (HD) maps are constrained by the high costs associated with the construction and maintenance of HD maps. Standard-definition (SD) maps-based methods, on the other hand, often exhibit unsatisfactory performance or poor generalization ability due to overfitting. To address these challenges, we propose SegLocNet, a multimodal GNSS-free localization network that achieves precise localization using bird's-eye-view (BEV) semantic segmentation. SegLocNet employs a BEV segmentation network to generate semantic maps from multiple sensor inputs, followed by an exhaustive matching process to estimate the vehicle's ego pose. This approach avoids the limitations of regression-based pose estimation and maintains high interpretability and generalization. By introducing a unified map representation, our method can be applied to both HD and SD maps without any modifications to the network architecture, thereby balancing localization accuracy and area coverage. Extensive experiments on the nuScenes and Argoverse datasets demonstrate that our method outperforms the current state-of-the-art methods, and that our method can accurately estimate the ego pose in urban environments without relying on GNSS, while maintaining strong generalization ability. Our code and pre-trained model will be released publicly.
Online Scheduling for LLM Inference with KV Cache Constraints
Feb 10, 2025
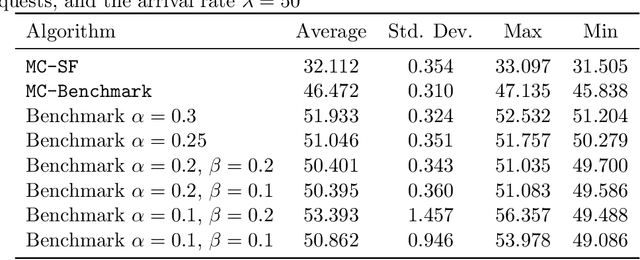
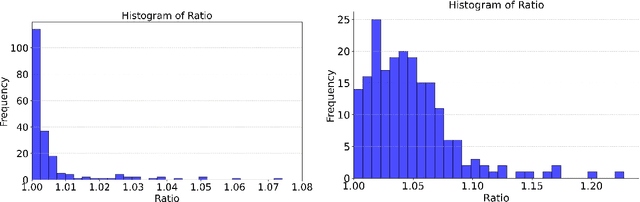
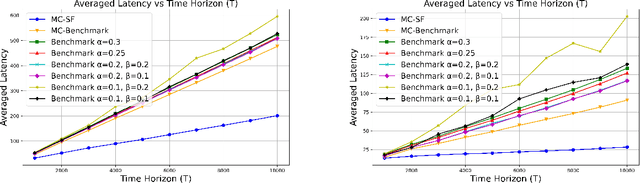
Large Language Model (LLM) inference, where a trained model generates text one word at a time in response to user prompts, is a computationally intensive process requiring efficient scheduling to optimize latency and resource utilization. A key challenge in LLM inference is the management of the Key-Value (KV) cache, which reduces redundant computations but introduces memory constraints. In this work, we model LLM inference with KV cache constraints theoretically and propose novel batching and scheduling algorithms that minimize inference latency while effectively managing the KV cache's memory. We analyze both semi-online and fully online scheduling models, and our results are threefold. First, we provide a polynomial-time algorithm that achieves exact optimality in terms of average latency in the semi-online prompt arrival model. Second, in the fully online case with a stochastic prompt arrival, we introduce an efficient online scheduling algorithm with constant regret. Third, we prove that no algorithm (deterministic or randomized) can achieve a constant competitive ratio in fully online adversarial settings. Our empirical evaluations on a public LLM inference dataset, using the Llama-70B model on A100 GPUs, show that our approach significantly outperforms benchmark algorithms used currently in practice, achieving lower latency while reducing energy consumption. Overall, our results offer a path toward more sustainable and cost-effective LLM deployment.