 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCI: Generative Modeling of User Interest Shift via Cohort-based Intent Learning for CTR Prediction
Jan 26, 2026Click-through rate (CTR) prediction plays a pivotal role in online advertising and recommender systems. Despite notable progress in modeling user preferences from historical behaviors, two key challenges persist. First, exsiting discriminative paradigms focus on matching candidates to user history, often overfitting to historically dominant features and failing to adapt to rapid interest shifts. Second, a critical information chasm emerges from the point-wise ranking paradigm. By scoring each candidate in isolation, CTR models discard the rich contextual signal implied by the recalled set as a whole, leading to a misalignment where long-term preferences often override the user's immediate, evolving intent. To address these issues, we propose GenCI, a generative user intent framework that leverages semantic interest cohorts to model dynamic user preferences for CTR prediction. The framework first employs a generative model, trained with a next-item prediction (NTP) objective, to proactively produce candidate interest cohorts. These cohorts serve as explicit, candidate-agnostic representations of a user's immediate intent. A hierarchical candidate-aware network then injects this rich contextual signal into the ranking stage, refining them with cross-attention to align with both user history and the target item. The entire model is trained end-to-end, creating a more aligned and effective CTR prediction pipeline. Extensive experiments on three widely used datasets demonstrate the effectiveness of our approach.
Efficient Vision Mamba for MRI Super-Resolution via Hybrid Selective Scanning
Dec 22, 2025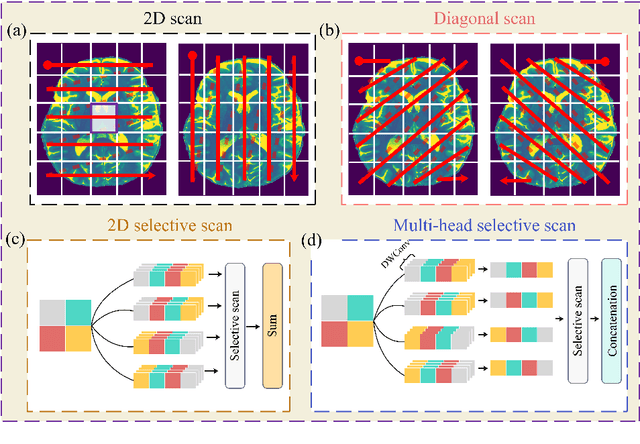
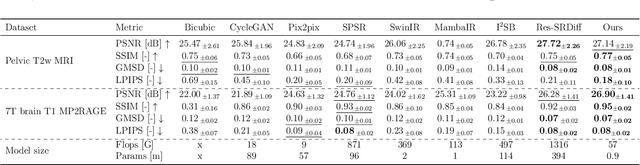
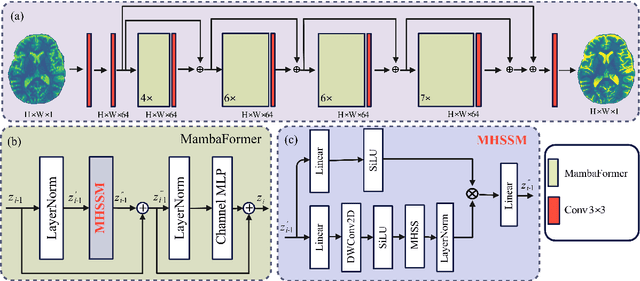

Background: High-resolution MRI is critical for diagnosis, but long acquisition times limit clinical use. Super-resolution (SR) can enhance resolution post-scan, yet existing deep learning methods face fidelity-efficiency trade-offs. Purpose: To develop a computationally efficient and accurate deep learning framework for MRI SR that preserves anatomical detail for clinical integration. Materials and Methods: We propose a novel SR framework combining multi-head selective state-space models (MHSSM) with a lightweight channel MLP. The model uses 2D patch extraction with hybrid scanning to capture long-range dependencies. Each MambaFormer block integrates MHSSM, depthwise convolutions, and gated channel mixing. Evaluation used 7T brain T1 MP2RAGE maps (n=142) and 1.5T prostate T2w MRI (n=334). Comparisons included Bicubic interpolation, GANs (CycleGAN, Pix2pix, SPSR), transformers (SwinIR), Mamba (MambaIR), and diffusion models (I2SB, Res-SRDiff). Results: Our model achieved superior performance with exceptional efficiency. For 7T brain data: SSIM=0.951+-0.021, PSNR=26.90+-1.41 dB, LPIPS=0.076+-0.022, GMSD=0.083+-0.017, significantly outperforming all baselines (p<0.001). For prostate data: SSIM=0.770+-0.049, PSNR=27.15+-2.19 dB, LPIPS=0.190+-0.095, GMSD=0.087+-0.013. The framework used only 0.9M parameters and 57 GFLOPs, reducing parameters by 99.8% and computation by 97.5% versus Res-SRDiff, while outperforming SwinIR and MambaIR in accuracy and efficiency. Conclusion: The proposed framework provides an efficient, accurate MRI SR solution, delivering enhanced anatomical detail across datasets. Its low computational demand and state-of-the-art performance show strong potential for clinical translation.
PrefPoE: Advantage-Guided Preference Fusion for Learning Where to Explore
Nov 11, 2025Exploration in reinforcement learning remains a critical challenge, as naive entropy maximization often results in high variance and inefficient policy updates. We introduce \textbf{PrefPoE}, a novel \textit{Preference-Product-of-Experts} framework that performs intelligent, advantage-guided exploration via the first principled application of product-of-experts (PoE) fusion for single-task exploration-exploitation balancing. By training a preference network to concentrate probability mass on high-advantage actions and fusing it with the main policy through PoE, PrefPoE creates a \textbf{soft trust region} that stabilizes policy updates while maintaining targeted exploration. Across diverse control tasks spanning both continuous and discrete action spaces, PrefPoE demonstrates consistent improvements: +321\% on HalfCheetah-v4 (1276~$\rightarrow$~5375), +69\% on Ant-v4, +276\% on LunarLander-v2, with consistently enhanced training stability and sample efficiency. Unlike standard PPO, which suffers from entropy collapse, PrefPoE sustains adaptive exploration through its unique dynamics, thereby preventing premature convergence and enabling superior performance. Our results establish that learning \textit{where to explore} through advantage-guided preferences is as crucial as learning how to act, offering a general framework for enhancing policy gradient methods across the full spectrum of reinforcement learning domains. Code and pretrained models are available in supplementary materials.
Multi-Modal Robust Enhancement for Coastal Water Segmentation: A Systematic HSV-Guided Framework
Sep 10, 2025Coastal water segmentation from satellite imagery presents unique challenges due to complex spectral characteristics and irregular boundary patterns. Traditional RGB-based approaches often suffer from training instability and poor generalization in diverse maritime environments. This paper introduces a systematic robust enhancement framework, referred to as Robust U-Net, that leverages HSV color space supervision and multi-modal constraints for improved coastal water segmentation. Our approach integrates five synergistic components: HSV-guided color supervision, gradient-based coastline optimization, morphological post-processing, sea area cleanup, and connectivity control. Through comprehensive ablation studies, we demonstrate that HSV supervision provides the highest impact (0.85 influence score), while the complete framework achieves superior training stability (84\% variance reduction) and enhanced segmentation quality. Our method shows consistent improvements across multiple evaluation metrics while maintaining computational efficiency. For reproducibility, our training configurations and code are available here: https://github.com/UofgCoastline/ICASSP-2026-Robust-Unet.
Adaptive Evolutionary Framework for Safe, Efficient, and Cooperative Autonomous Vehicle Interactions
Sep 09, 2025Modern transportation systems face significant challenges in ensuring road safety, given serious injuries caused by road accidents. The rapid growth of autonomous vehicles (AVs) has prompted new traffic designs that aim to optimize interactions among AVs. However, effective interactions between AVs remains challenging due to the absence of centralized control. Besides, there is a need for balancing multiple factors, including passenger demands and overall traffic efficiency. Traditional rule-based, optimization-based, and game-theoretic approaches each have limitations in addressing these challenges. Rule-based methods struggle with adaptability and generalization in complex scenarios, while optimization-based methods often require high computational resources. Game-theoretic approaches, such as Stackelberg and Nash games, suffer from limited adaptability and potential inefficiencies in cooperative settings. This paper proposes an Evolutionary Game Theory (EGT)-based framework for AV interactions that overcomes these limitations by utilizing a decentralized and adaptive strategy evolution mechanism. A causal evaluation module (CEGT) is introduced to optimize the evolutionary rate, balancing mutation and evolution by learning from historical interactions. Simulation results demonstrate the proposed CEGT outperforms EGT and popular benchmark games in terms of lower collision rates, improved safety distances, higher speeds, and overall better performance compared to Nash and Stackelberg games across diverse scenarios and parameter settings.
Mean Field Game-Based Interactive Trajectory Planning Using Physics-Inspired Unified Potential Fields
Sep 09, 2025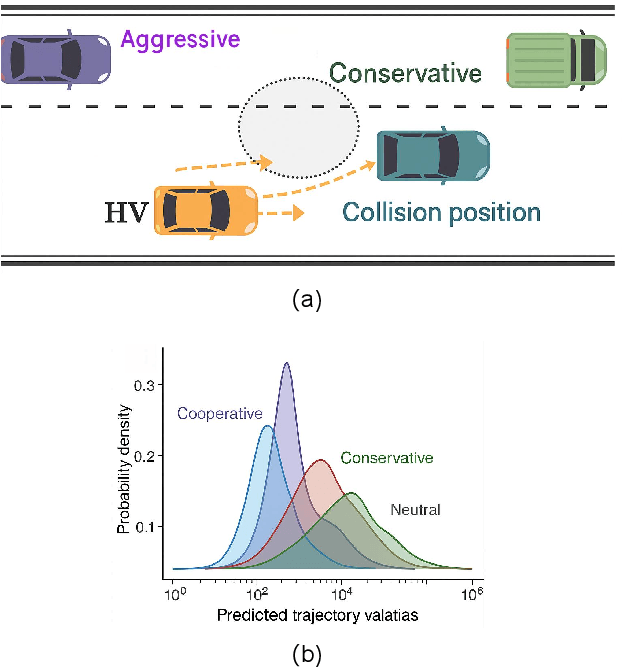
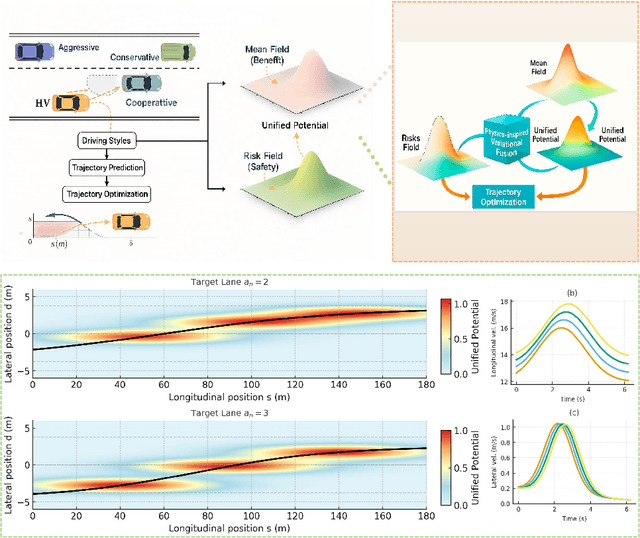
Interactive trajectory planning in autonomous driving must balance safety, efficiency, and scalability under heterogeneous driving behaviors. Existing methods often face high computational cost or rely on external safety critics. To address this, we propose an Interaction-Enriched Unified Potential Field (IUPF) framework that fuses style-dependent benefit and risk fields through a physics-inspired variational model, grounded in mean field game theory. The approach captures conservative, aggressive, and cooperative behaviors without additional safety modules, and employs stochastic differential equations to guarantee Nash equilibrium with exponential convergence. Simulations on lane changing and overtaking scenarios show that IUPF ensures safe distances, generates smooth and efficient trajectories, and outperforms traditional optimization and game-theoretic baselines in both adaptability and computational efficiency.
Attention and Risk-Aware Decision Framework for Safe Autonomous Driving
Sep 09, 2025Autonomous driving has attracted great interest due to its potential capability in full-unsupervised driving. Model-based and learning-based methods are widely used in autonomous driving. Model-based methods rely on pre-defined models of the environment and may struggle with unforeseen events. Proximal policy optimization (PPO), an advanced learning-based method, can adapt to the above limits by learning from interactions with the environment. However, existing PPO faces challenges with poor training results, and low training efficiency in long sequences. Moreover, the poor training results are equivalent to collisions in driving tasks. To solve these issues, this paper develops an improved PPO by introducing the risk-aware mechanism, a risk-attention decision network, a balanced reward function, and a safety-assisted mechanism. The risk-aware mechanism focuses on highlighting areas with potential collisions, facilitating safe-driving learning of the PPO. The balanced reward function adjusts rewards based on the number of surrounding vehicles, promoting efficient exploration of the control strategy during training. Additionally, the risk-attention network enhances the PPO to hold channel and spatial attention for the high-risk areas of input images. Moreover, the safety-assisted mechanism supervises and prevents the actions with risks of collisions during the lane keeping and lane changing. Simulation results on a physical engine demonstrate that the proposed algorithm outperforms benchmark algorithms in collision avoidance, achieving higher peak reward with less training time, and shorter driving time remaining on the risky areas among multiple testing traffic flow scenarios.
Marine Chlorophyll Prediction and Driver Analysis based on LSTM-RF Hybrid Models
Aug 07, 2025Marine chlorophyll concentration is an important indicator of ecosystem health and carbon cycle strength, and its accurate prediction is crucial for red tide warning and ecological response. In this paper, we propose a LSTM-RF hybrid model that combines the advantages of LSTM and RF, which solves the deficiencies of a single model in time-series modelling and nonlinear feature portrayal. Trained with multi-source ocean data(temperature, salinity, dissolved oxygen, etc.), the experimental results show that the LSTM-RF model has an R^2 of 0.5386, an MSE of 0.005806, and an MAE of 0.057147 on the test set, which is significantly better than using LSTM (R^2 = 0.0208) and RF (R^2 =0.4934) alone , respectively. The standardised treatment and sliding window approach improved the prediction accuracy of the model and provided an innovative solution for high-frequency prediction of marine ecological variables.
Limited-Angle CBCT Reconstruction via Geometry-Integrated Cycle-domain Denoising Diffusion Probabilistic Models
Jun 16, 2025



Cone-beam CT (CBCT) is widely used in clinical radiotherapy for image-guided treatment, improving setup accuracy, adaptive planning, and motion management. However, slow gantry rotation limits performance by introducing motion artifacts, blurring, and increased dose. This work aims to develop a clinically feasible method for reconstructing high-quality CBCT volumes from consecutive limited-angle acquisitions, addressing imaging challenges in time- or dose-constrained settings. We propose a limited-angle (LA) geometry-integrated cycle-domain (LA-GICD) framework for CBCT reconstruction, comprising two denoising diffusion probabilistic models (DDPMs) connected via analytic cone-beam forward and back projectors. A Projection-DDPM completes missing projections, followed by back-projection, and an Image-DDPM refines the volume. This dual-domain design leverages complementary priors from projection and image spaces to achieve high-quality reconstructions from limited-angle (<= 90 degrees) scans. Performance was evaluated against full-angle reconstruction. Four board-certified medical physicists conducted assessments. A total of 78 planning CTs in common CBCT geometries were used for training and evaluation. The method achieved a mean absolute error of 35.5 HU, SSIM of 0.84, and PSNR of 29.8 dB, with visibly reduced artifacts and improved soft-tissue clarity. LA-GICD's geometry-aware dual-domain learning, embedded in analytic forward/backward operators, enabled artifact-free, high-contrast reconstructions from a single 90-degree scan, reducing acquisition time and dose four-fold. LA-GICD improves limited-angle CBCT reconstruction with strong data fidelity and anatomical realism. It offers a practical solution for short-arc acquisitions, enhancing CBCT use in radiotherapy by providing clinically applicable images with reduced scan time and dose for more accurate, personalized treatments.
Automated Treatment Planning for Interstitial HDR Brachytherapy for Locally Advanced Cervical Cancer using Deep Reinforcement Learning
Jun 13, 2025High-dose-rate (HDR) brachytherapy plays a critical role in the treatment of locally advanced cervical cancer but remains highly dependent on manual treatment planning expertise. The objective of this study is to develop a fully automated HDR brachytherapy planning framework that integrates reinforcement learning (RL) and dose-based optimization to generate clinically acceptable treatment plans with improved consistency and efficiency. We propose a hierarchical two-stage autoplanning framework. In the first stage, a deep Q-network (DQN)-based RL agent iteratively selects treatment planning parameters (TPPs), which control the trade-offs between target coverage and organ-at-risk (OAR) sparing. The agent's state representation includes both dose-volume histogram (DVH) metrics and current TPP values, while its reward function incorporates clinical dose objectives and safety constraints, including D90, V150, V200 for targets, and D2cc for all relevant OARs (bladder, rectum, sigmoid, small bowel, and large bowel). In the second stage, a customized Adam-based optimizer computes the corresponding dwell time distribution for the selected TPPs using a clinically informed loss function. The framework was evaluated on a cohort of patients with complex applicator geometries. The proposed framework successfully learned clinically meaningful TPP adjustments across diverse patient anatomies. For the unseen test patients, the RL-based automated planning method achieved an average score of 93.89%, outperforming the clinical plans which averaged 91.86%. These findings are notable given that score improvements were achieved while maintaining full target coverage and reducing CTV hot spots in most cases.