 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgetting Through Transforming: Enabling Federated Unlearning via Class-Aware Representation Transformation
Oct 09, 2024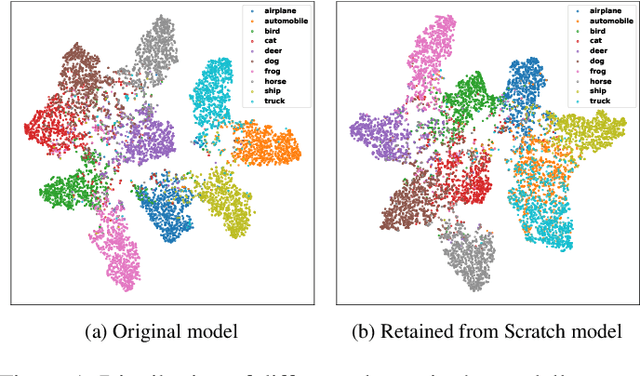

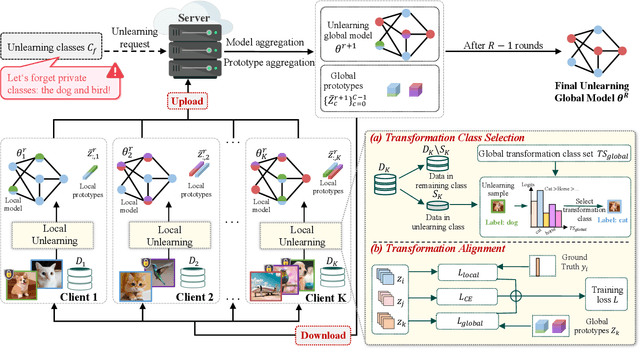

Federated Unlearning (FU) enables clients to selectively remove the influence of specific data from a trained federated learning model, addressing privacy concerns and regulatory requirements. However, existing FU methods often struggle to balance effective erasure with model utility preservation, especially for class-level unlearning in non-IID settings. We propose Federated Unlearning via Class-aware Representation Transformation (FUCRT), a novel method that achieves unlearning through class-aware representation transformation. FUCRT employs two key components: (1) a transformation class selection strategy to identify optimal forgetting directions, and (2) a transformation alignment technique using dual class-aware contrastive learning to ensure consistent transformations across clients. Extensive experiments on four datasets demonstrate FUCRT's superior performance in terms of erasure guarantee, model utility preservation, and efficiency. FUCRT achieves complete (100\%) erasure of unlearning classes while maintaining or improving performance on remaining classes, outperforming state-of-the-art baselines across both IID and Non-IID settings. Analysis of the representation space reveals FUCRT's ability to effectively merge unlearning class representations with the transformation class from remaining classes, closely mimicking the model retrained from scratch.
Contribution Evaluation of Heterogeneous Participants in Federated Learning via Prototypical Representations
Jul 02, 2024Contribution evaluation in federated learning (FL) has become a pivotal research area due to its applicability across various domains, such as detecting low-quality datasets, enhancing model robustness, and designing incentive mechanisms. Existing contribution evaluation methods, which primarily rely on data volume, model similarity, and auxiliary test datasets, have shown success in diverse scenarios. However, their effectiveness often diminishes due to the heterogeneity of data distributions, presenting a significant challenge to their applicability. In response, this paper explores contribution evaluation in FL from an entirely new perspective of representation. In this work, we propose a new method for the contribution evaluation of heterogeneous participants in federated learning (FLCE), which introduces a novel indicator \emph{class contribution momentum} to conduct refined contribution evaluation. Our core idea is the construction and application of the class contribution momentum indicator from individual, relative, and holistic perspectives, thereby achieving an effective and efficient contribution evaluation of heterogeneous participants without relying on an auxiliary test dataset. Extensive experimental results demonstrate the superiority of our method in terms of fidelity, effectiveness, efficiency, and heterogeneity across various scenarios.
Dual Class-Aware Contrastive Federated Semi-Supervised Learning
Nov 16, 2022Federated semi-supervised learning (FSSL), facilitates labeled clients and unlabeled clients jointly training a global model without sharing private data. Existing FSSL methods mostly focus on pseudo-labeling and consistency regularization to leverage the knowledge of unlabeled data, which have achieved substantial success on raw data utilization. However, their training procedures suffer from the large deviation from local models of labeled clients and unlabeled clients and the confirmation bias induced by noisy pseudo labels, which seriously damage the performance of the global model. In this paper, we propose a novel FSSL method, named Dual Class-aware Contrastive Federated Semi-Supervised Learning (DCCFSSL), which considers the local class-aware distribution of individual client's data and the global class-aware distribution of all clients' data simultaneously in the feature space. By introducing a dual class-aware contrastive module, DCCFSSL builds a common training goal for different clients to reduce the large deviation and introduces contrastive information in the feature space to alleviate the confirmation bias. Meanwhile, DCCFSSL presents an authentication-reweighted aggregation method to enhance the robustness of the server's aggregation. Extensive experiments demonstrate that DCCFSSL not only outperforms state-of-the-art methods on three benchmarked datasets, but also surpasses the FedAvg with relabeled unlabeled clients on CIFAR-10 and CIFAR-100 datasets. To our best knowledge, we are the first to present the FSSL method that utilizes only 10\% labeled clients of all clients to achieve better performance than the standard federated supervised learning that uses all clients with labeled data.
FedMCSA: Personalized Federated Learning via Model Components Self-Attention
Aug 23, 2022
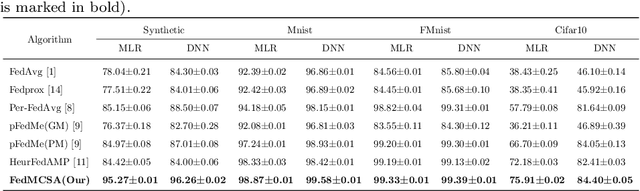

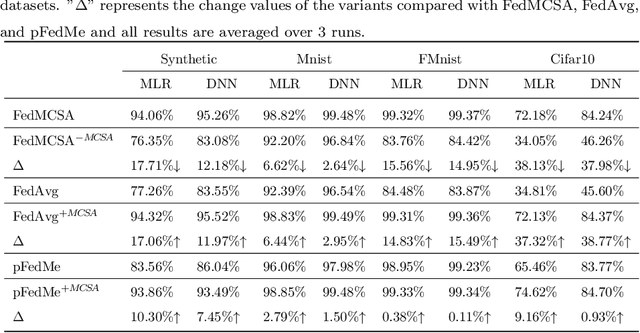
Federated learning (FL) facilitates multiple clients to jointly train a machine learning model without sharing their private data. However, Non-IID data of clients presents a tough challenge for FL. Existing personalized FL approaches rely heavily on the default treatment of one complete model as a basic unit and ignore the significance of different layers on Non-IID data of clients. In this work, we propose a new framework, federated model components self-attention (FedMCSA), to handle Non-IID data in FL, which employs model components self-attention mechanism to granularly promote cooperation between different clients. This mechanism facilitates collaboration between similar model components while reducing interference between model components with large differences. We conduct extensive experiments to demonstrate that FedMCSA outperforms the previous methods on four benchmark datasets. Furthermore, we empirically show the effectiveness of the model components self-attention mechanism, which is complementary to existing personalized FL and can significantly improve the performance of FL.
Stochastic Batch Augmentation with An Effective Distilled Dynamic Soft Label Regularizer
Jun 27, 2020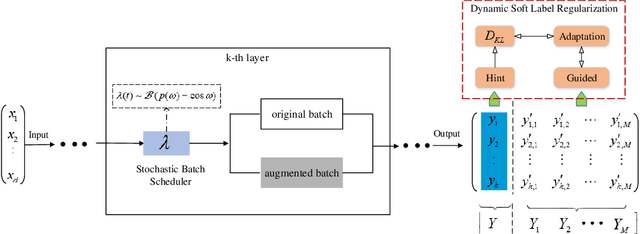

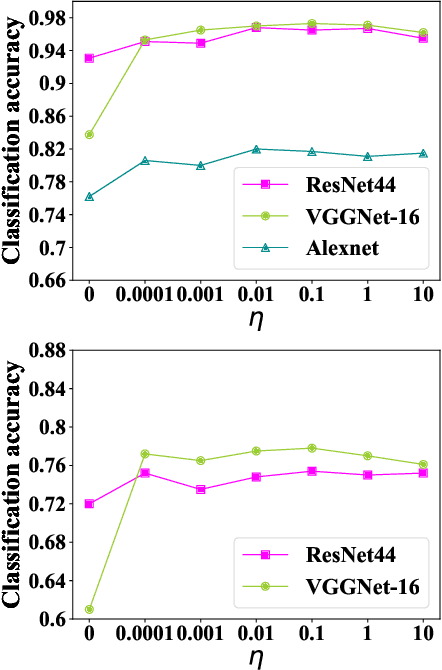
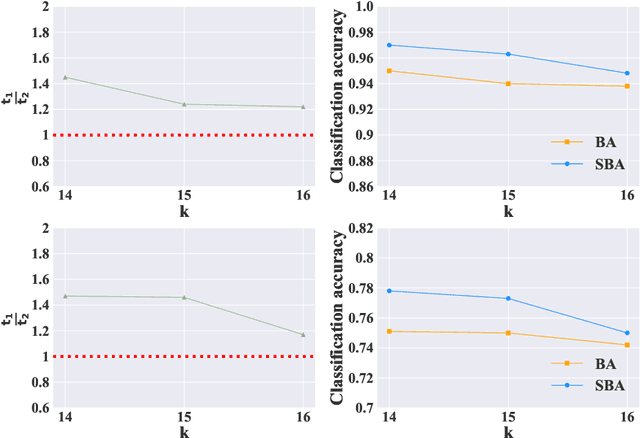
Data augmentation have been intensively used in training deep neural network to improve the generalization, whether in original space (e.g., image space) or representation space. Although being successful, the connection between the synthesized data and the original data is largely ignored in training, without considering the distribution information that the synthesized samples are surrounding the original sample in training. Hence, the behavior of the network is not optimized for this. However, that behavior is crucially important for generalization, even in the adversarial setting, for the safety of the deep learning system. In this work, we propose a framework called Stochastic Batch Augmentation (SBA) to address these problems. SBA stochastically decides whether to augment at iterations controlled by the batch scheduler and in which a ''distilled'' dynamic soft label regularization is introduced by incorporating the similarity in the vicinity distribution respect to raw samples. The proposed regularization provides direct supervision by the KL-Divergence between the output soft-max distributions of original and virtual data. Our experiments on CIFAR-10, CIFAR-100, and ImageNet show that SBA can improve the generalization of the neural networks and speed up the convergence of network training.