 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashNav: Ultra-Fast Policy Training for Robot Navigation within 20 Seconds
Jun 14, 2026Deep reinforcement learning has shown strong potential for robot navigation, but its practical deployment is still limited by the long wall-clock cost of policy training. This paper presents FlashNav, a GPU-first framework for ultra-fast range-based robot navigation training. To the best of our knowledge, FlashNav is the first DRL-based robot navigation framework that reaches seconds-level policy training, with the fastest deployable policy trained in less than 20 seconds. The key idea is to align simulation with the navigation MDP: FlashNav preserves the essential components for velocity-level navigation, including occupancy geometry, range sensing, goal-conditioned control, robot motion dynamics, collision handling, termination, and reset, while removing unnecessary rendering and high-fidelity physical details from the training loop. Built on a batched bitmap simulator and a fully GPU-resident training pipeline with our FastDSAC learner, FlashNav generates massive parallel navigation transitions entirely on GPU. Experiments on TurtleBot2 and Unitree Go2 show that FlashNav achieves a 100\% success-rate below 20 seconds on an RTX 5090 and remains within tens of seconds across desktop GPUs. The learned policies further transfer to physical wheeled and legged robots in static and dynamic indoor scenes, demonstrating that DRL-based navigation can be trained at seconds-level speed while preserving deployable obstacle-avoidance behavior.
PANDA: Preference Adaptation for Enhancing Domain-Specific Abilities of LLMs
Feb 20, 2024While Large language models (LLMs) have demonstrated considerable capabilities across various natural language tasks, they often fall short of the performance achieved by domain-specific state-of-the-art models. One potential approach to enhance domain-specific capabilities of LLMs involves fine-tuning them using corresponding datasets. However, this method can be both resource and time-intensive, and not applicable to closed-source commercial LLMs. In this paper, we propose Preference Adaptation for Enhancing Domain-specific Abilities of LLMs (PANDA), a method designed to augment the domain-specific capabilities of LLMs by leveraging insights from the response preference of expert models without requiring fine-tuning. Our experimental results reveal that PANDA significantly enhances the domain-specific ability of LLMs on text classification and interactive decision tasks. Moreover, LLM with PANDA even outperforms the expert model that being learned on 4 tasks of ScienceWorld. This finding highlights the potential of exploring tuning-free approaches to achieve weak-to-strong generalization.
Towards Unified Alignment Between Agents, Humans, and Environment
Feb 14, 2024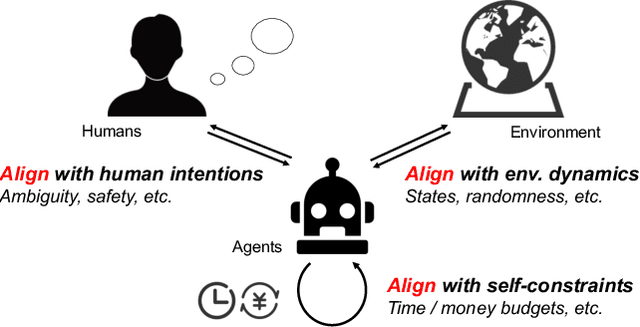
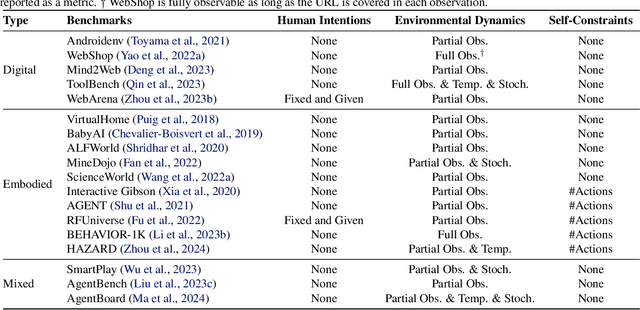
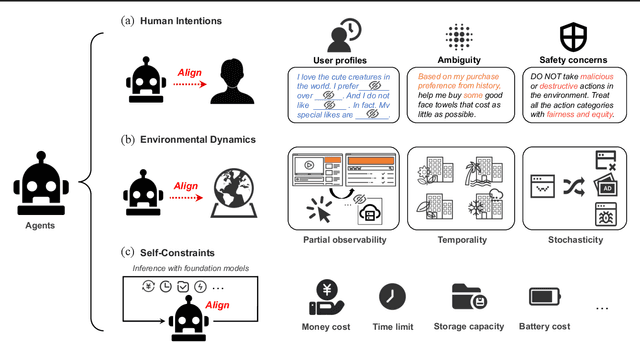

The rapid progress of foundation models has led to the prosperity of autonomous agents, which leverage the universal capabilities of foundation models to conduct reasoning, decision-making, and environmental interaction. However, the efficacy of agents remains limited when operating in intricate, realistic environments. In this work, we introduce the principles of $\mathbf{U}$nified $\mathbf{A}$lignment for $\mathbf{A}$gents ($\mathbf{UA}^2$), which advocate for the simultaneous alignment of agents with human intentions, environmental dynamics, and self-constraints such as the limitation of monetary budgets. From the perspective of $\mathbf{UA}^2$, we review the current agent research and highlight the neglected factors in existing agent benchmarks and method candidates. We also conduct proof-of-concept studies by introducing realistic features to WebShop, including user profiles to demonstrate intentions, personalized reranking for complex environmental dynamics, and runtime cost statistics to reflect self-constraints. We then follow the principles of $\mathbf{UA}^2$ to propose an initial design of our agent, and benchmark its performance with several candidate baselines in the retrofitted WebShop. The extensive experimental results further prove the importance of the principles of $\mathbf{UA}^2$. Our research sheds light on the next steps of autonomous agent research with improved general problem-solving abilities.
ACQUIRED: A Dataset for Answering Counterfactual Questions In Real-Life Videos
Nov 02, 2023



Multimodal counterfactual reasoning is a vital yet challenging ability for AI systems. It involves predicting the outcomes of hypothetical circumstances based on vision and language inputs, which enables AI models to learn from failures and explore hypothetical scenarios. Despite its importance, there are only a few datasets targeting the counterfactual reasoning abilities of multimodal models. Among them, they only cover reasoning over synthetic environments or specific types of events (e.g. traffic collisions), making them hard to reliably benchmark the model generalization ability in diverse real-world scenarios and reasoning dimensions. To overcome these limitations, we develop a video question answering dataset, ACQUIRED: it consists of 3.9K annotated videos, encompassing a wide range of event types and incorporating both first and third-person viewpoints, which ensures a focus on real-world diversity. In addition, each video is annotated with questions that span three distinct dimensions of reasoning, including physical, social, and temporal, which can comprehensively evaluate the model counterfactual abilities along multiple aspects. We benchmark our dataset against several state-of-the-art language-only and multimodal models and experimental results demonstrate a significant performance gap (>13%) between models and humans. The findings suggest that multimodal counterfactual reasoning remains an open challenge and ACQUIRED is a comprehensive and reliable benchmark for inspiring future research in this direction.
Learning Action Conditions from Instructional Manuals for Instruction Understanding
May 25, 2022
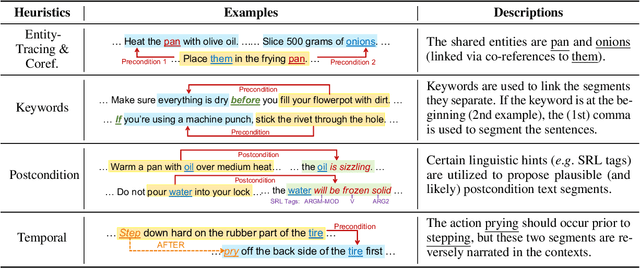

The ability to infer pre- and postconditions of an action is vital for comprehending complex instructions, and is essential for applications such as autonomous instruction-guided agents and assistive AI that supports humans to perform physical tasks. In this work, we propose a task dubbed action condition inference, and collecting a high-quality, human annotated dataset of preconditions and postconditions of actions in instructional manuals. We propose a weakly supervised approach to automatically construct large-scale training instances from online instructional manuals, and curate a densely human-annotated and validated dataset to study how well the current NLP models can infer action-condition dependencies in the instruction texts. We design two types of models differ by whether contextualized and global information is leveraged, as well as various combinations of heuristics to construct the weak supervisions. Our experimental results show a >20% F1-score improvement with considering the entire instruction contexts and a >6% F1-score benefit with the proposed heuristics.
Can Model Compression Improve NLP Fairness
Jan 21, 2022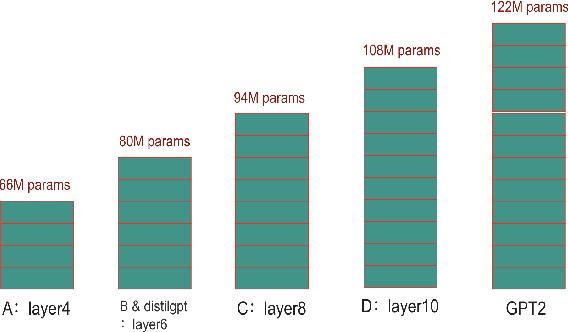
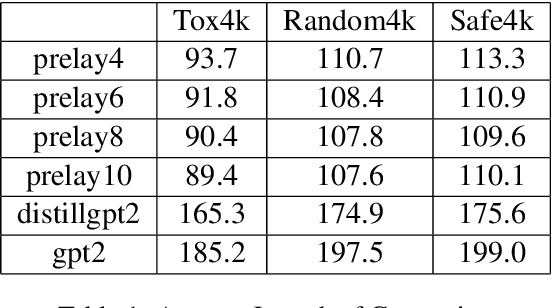
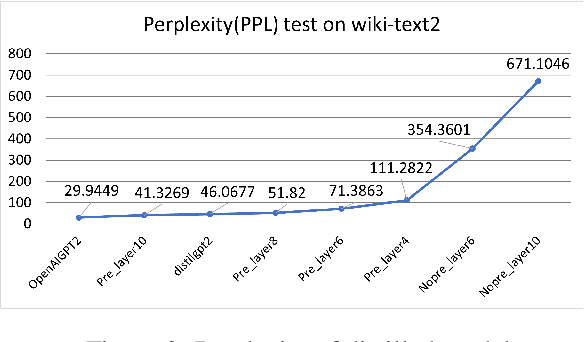
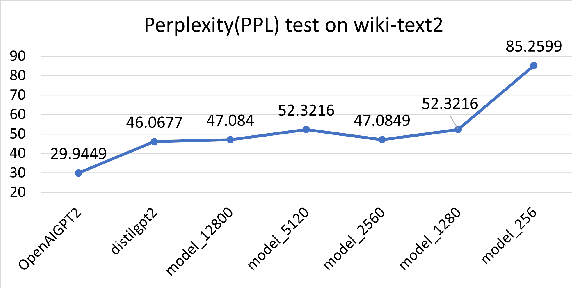
Model compression techniques are receiving increasing attention; however, the effect of compression on model fairness is still under explored. This is the first paper to examine the effect of distillation and pruning on the toxicity and bias of generative language models. We test Knowledge Distillation and Pruning methods on the GPT2 model and found a consistent pattern of toxicity and bias reduction after model distillation; this result can be potentially interpreted by existing line of research which describes model compression as a regularization technique; our work not only serves as a reference for safe deployment of compressed models, but also extends the discussion of "compression as regularization" into the setting of neural LMs, and hints at the possibility of using compression to develop fairer models.
Modeling Fuzzy Cluster Transitions for Topic Tracing
Apr 16, 2021
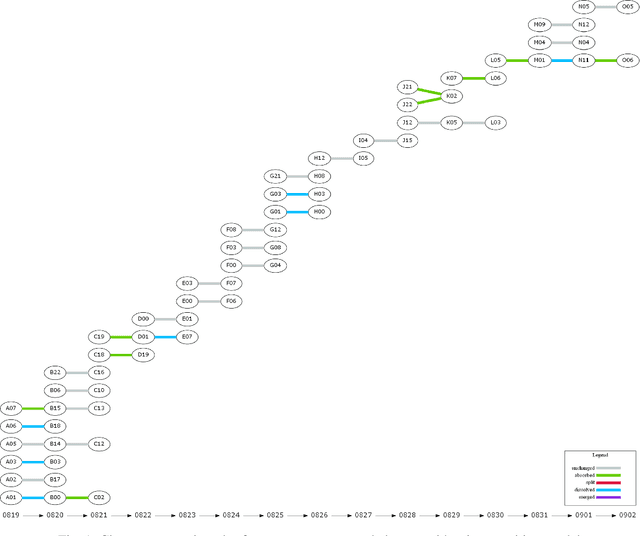

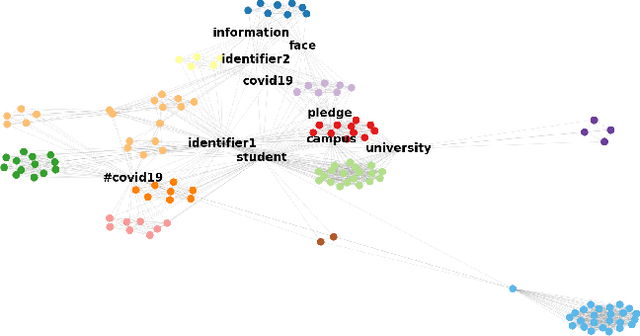
Twitter can be viewed as a data source for Natural Language Processing (NLP) tasks. The continuously updating data streams on Twitter make it challenging to trace real-time topic evolution. In this paper, we propose a framework for modeling fuzzy transitions of topic clusters. We extend our previous work on crisp cluster transitions by incorporating fuzzy logic in order to enrich the underlying structures identified by the framework. We apply the methodology to both computer generated clusters of nouns from tweets and human tweet annotations. The obtained fuzzy transitions are compared with the crisp transitions, on both computer generated clusters and human labeled topic sets.
Tracing Topic Transitions with Temporal Graph Clusters
Apr 16, 2021

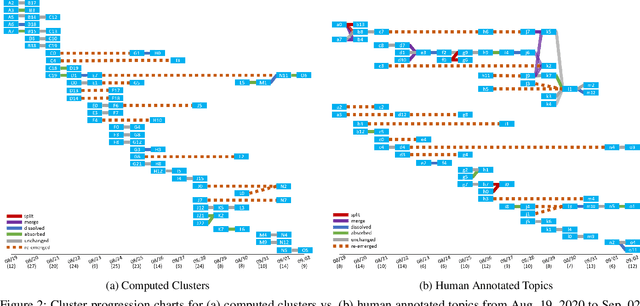
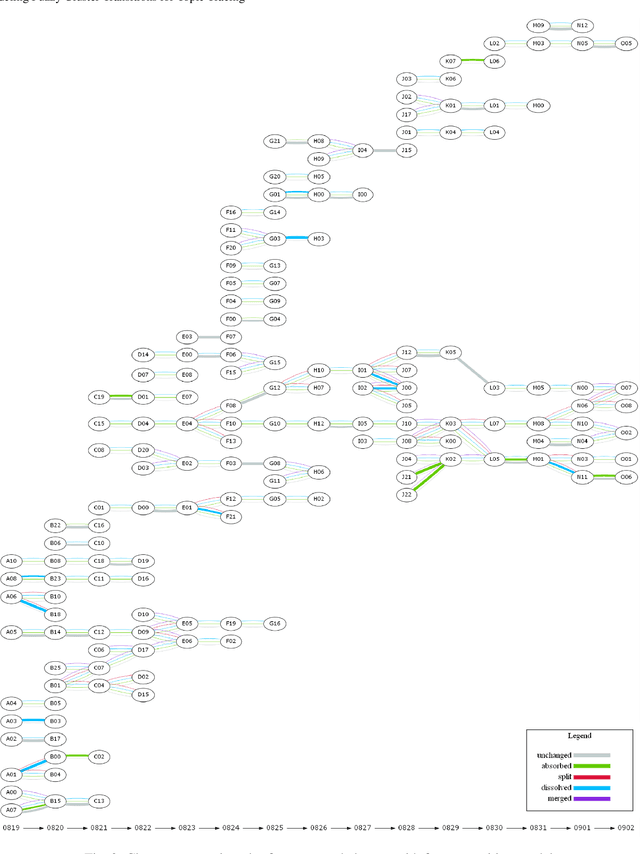
Twitter serves as a data source for many Natural Language Processing (NLP) tasks. It can be challenging to identify topics on Twitter due to continuous updating data stream. In this paper, we present an unsupervised graph based framework to identify the evolution of sub-topics within two weeks of real-world Twitter data. We first employ a Markov Clustering Algorithm (MCL) with a node removal method to identify optimal graph clusters from temporal Graph-of-Words (GoW). Subsequently, we model the clustering transitions between the temporal graphs to identify the topic evolution. Finally, the transition flows generated from both computational approach and human annotations are compared to ensure the validity of our framework.
Exploring Lexical Irregularities in Hypothesis-Only Models of Natural Language Inference
Jan 22, 2021
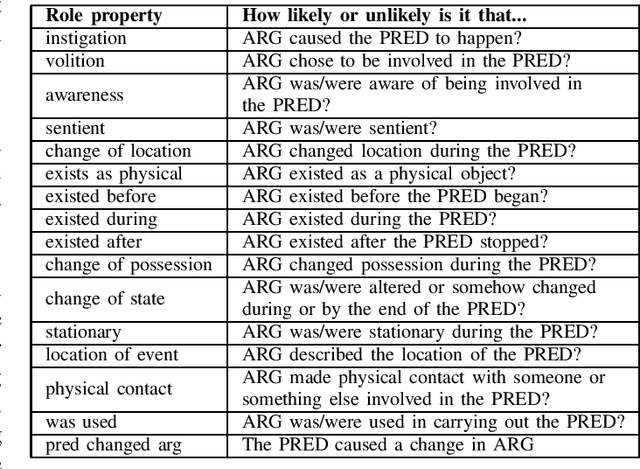
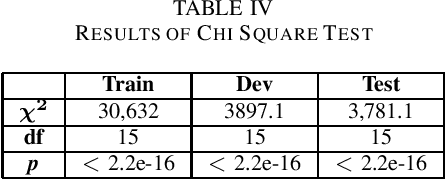
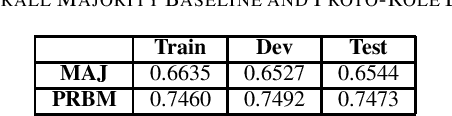
Natural Language Inference (NLI) or Recognizing Textual Entailment (RTE) is the task of predicting the entailment relation between a pair of sentences (premise and hypothesis). This task has been described as a valuable testing ground for the development of semantic representations, and is a key component in natural language understanding evaluation benchmarks. Models that understand entailment should encode both, the premise and the hypothesis. However, experiments by Poliak et al. revealed a strong preference of these models towards patterns observed only in the hypothesis, based on a 10 dataset comparison. Their results indicated the existence of statistical irregularities present in the hypothesis that bias the model into performing competitively with the state of the art. While recast datasets provide large scale generation of NLI instances due to minimal human intervention, the papers that generate them do not provide fine-grained analysis of the potential statistical patterns that can bias NLI models. In this work, we analyze hypothesis-only models trained on one of the recast datasets provided in Poliak et al. for word-level patterns. Our results indicate the existence of potential lexical biases that could contribute to inflating the model performance.
Stochastic Batch Augmentation with An Effective Distilled Dynamic Soft Label Regularizer
Jun 27, 2020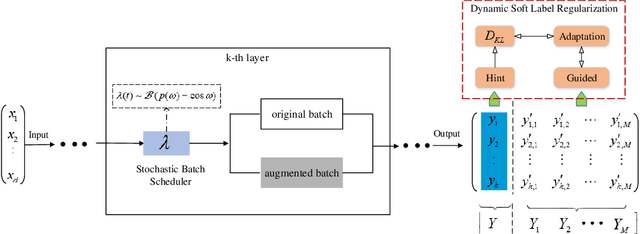

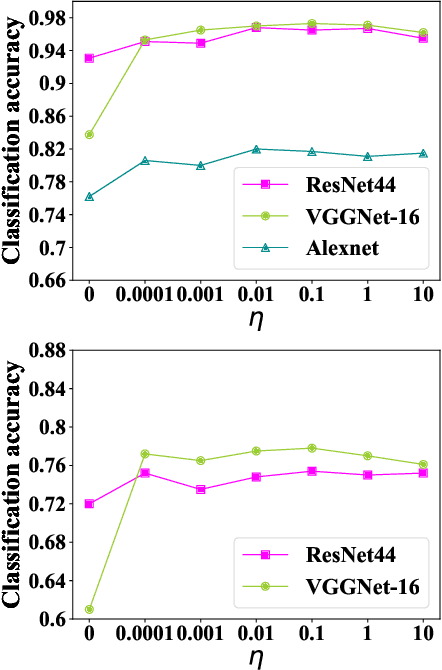
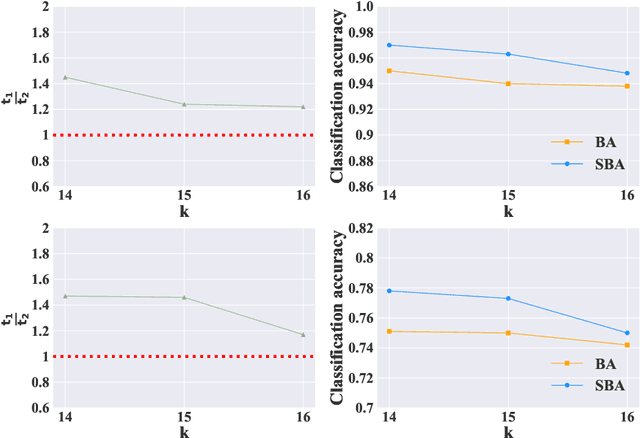
Data augmentation have been intensively used in training deep neural network to improve the generalization, whether in original space (e.g., image space) or representation space. Although being successful, the connection between the synthesized data and the original data is largely ignored in training, without considering the distribution information that the synthesized samples are surrounding the original sample in training. Hence, the behavior of the network is not optimized for this. However, that behavior is crucially important for generalization, even in the adversarial setting, for the safety of the deep learning system. In this work, we propose a framework called Stochastic Batch Augmentation (SBA) to address these problems. SBA stochastically decides whether to augment at iterations controlled by the batch scheduler and in which a ''distilled'' dynamic soft label regularization is introduced by incorporating the similarity in the vicinity distribution respect to raw samples. The proposed regularization provides direct supervision by the KL-Divergence between the output soft-max distributions of original and virtual data. Our experiments on CIFAR-10, CIFAR-100, and ImageNet show that SBA can improve the generalization of the neural networks and speed up the convergence of network training.