 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Restoration-driven Prompt Optimization: Unlocking LLM Potential for Open-Domain Relational Triplet Extraction
Jan 21, 2026Open-domain Relational Triplet Extraction (ORTE) is the foundation for mining structured knowledge without predefined schemas. Despite the impressive in-context learning capabilities of Large Language Models (LLMs), existing methods are hindered by their reliance on static, heuristic-driven prompting strategies. Due to the lack of reflection mechanisms required to internalize erroneous signals, these methods exhibit vulnerability in semantic ambiguity, often making erroneous extraction patterns permanent. To address this bottleneck, we propose a Knowledge Reconstruction-driven Prompt Optimization (KRPO) framework to assist LLMs in continuously improving their extraction capabilities for complex ORTE task flows. Specifically, we design a self-evaluation mechanism based on knowledge restoration, which provides intrinsic feedback signals by projecting structured triplets into semantic consistency scores. Subsequently, we propose a prompt optimizer based on a textual gradient that can internalize historical experiences to iteratively optimize prompts, which can better guide LLMs to handle subsequent extraction tasks. Furthermore, to alleviate relation redundancy, we design a relation canonicalization memory that collects representative relations and provides semantically distinct schemas for the triplets. Extensive experiments across three datasets show that KRPO significantly outperforms strong baselines in the extraction F1 score.
On A Scale From 1 to 5: Quantifying Hallucination in Faithfulness Evaluation
Oct 16, 2024



Hallucination has been a popular topic in natural language generation (NLG). In real-world applications, unfaithful content can result in bad data quality or loss of trust from end users. Thus, it is crucial to fact-check before adopting NLG for production usage, which can be expensive if done manually. In this paper, we investigate automated faithfulness evaluation in guided NLG. We developed a rubrics template and use large language models (LLMs) to score the generation into quantifiable scales. We compared popular LLMs as well as the widely adopted natural language inference (NLI) models in scoring quality and sensitivity. In addition, we developed methods to generation synthetic unfaithful data, as well as a heuristics to quantify the percentage of hallucination. Our results on 4 travel-domain industry dataset show that GPT-4 can provide accurate judgement and explanation on whether a source and a generation are factually consistent. Furthermore, we found that tuning NLI models on synthetic data can improve performance. Lastly, we present insights on latency and cost for deploying such system.
Modeling Fuzzy Cluster Transitions for Topic Tracing
Apr 16, 2021
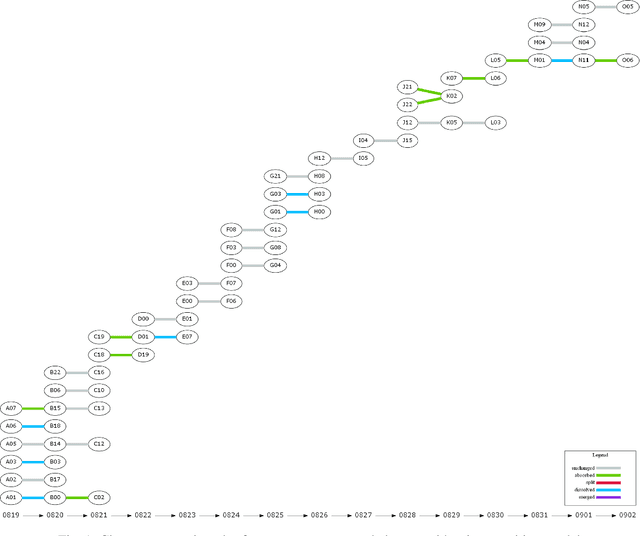

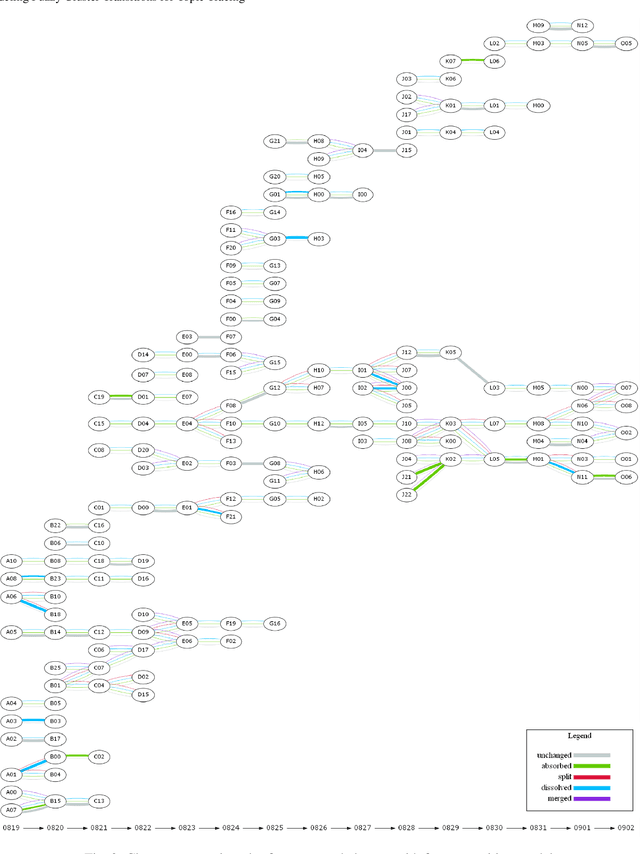
Twitter can be viewed as a data source for Natural Language Processing (NLP) tasks. The continuously updating data streams on Twitter make it challenging to trace real-time topic evolution. In this paper, we propose a framework for modeling fuzzy transitions of topic clusters. We extend our previous work on crisp cluster transitions by incorporating fuzzy logic in order to enrich the underlying structures identified by the framework. We apply the methodology to both computer generated clusters of nouns from tweets and human tweet annotations. The obtained fuzzy transitions are compared with the crisp transitions, on both computer generated clusters and human labeled topic sets.
Tracing Topic Transitions with Temporal Graph Clusters
Apr 16, 2021
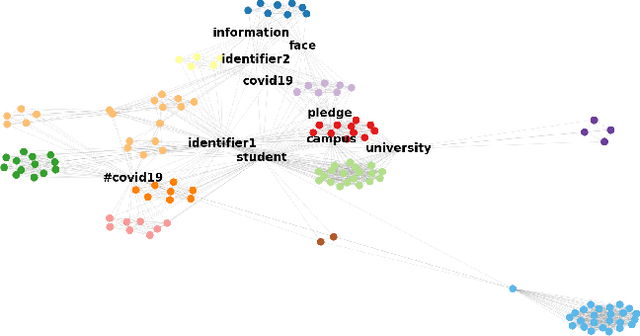

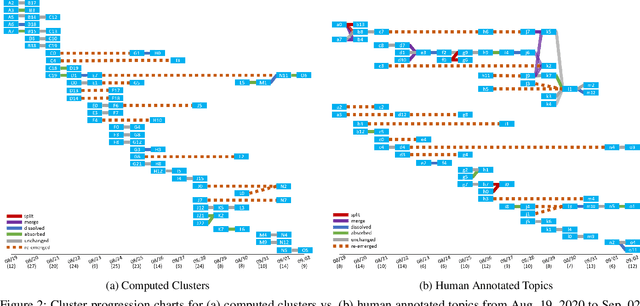
Twitter serves as a data source for many Natural Language Processing (NLP) tasks. It can be challenging to identify topics on Twitter due to continuous updating data stream. In this paper, we present an unsupervised graph based framework to identify the evolution of sub-topics within two weeks of real-world Twitter data. We first employ a Markov Clustering Algorithm (MCL) with a node removal method to identify optimal graph clusters from temporal Graph-of-Words (GoW). Subsequently, we model the clustering transitions between the temporal graphs to identify the topic evolution. Finally, the transition flows generated from both computational approach and human annotations are compared to ensure the validity of our framework.
Graph-of-Tweets: A Graph Merging Approach to Sub-event Identification
Jan 08, 2021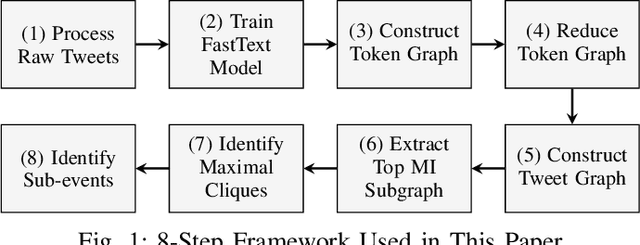
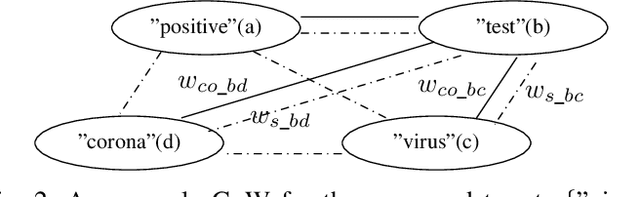


Graph structures are powerful tools for modeling the relationships between textual elements. Graph-of-Words (GoW) has been adopted in many Natural Language tasks to encode the association between terms. However, GoW provides few document-level relationships in cases when the connections between documents are also essential. For identifying sub-events on social media like Twitter, features from both word- and document-level can be useful as they supply different information of the event. We propose a hybrid Graph-of-Tweets (GoT) model which combines the word- and document-level structures for modeling Tweets. To compress large amount of raw data, we propose a graph merging method which utilizes FastText word embeddings to reduce the GoW. Furthermore, we present a novel method to construct GoT with the reduced GoW and a Mutual Information (MI) measure. Finally, we identify maximal cliques to extract popular sub-events. Our model showed promising results on condensing lexical-level information and capturing keywords of sub-events.
Misspelling Correction with Pre-trained Contextual Language Model
Jan 08, 2021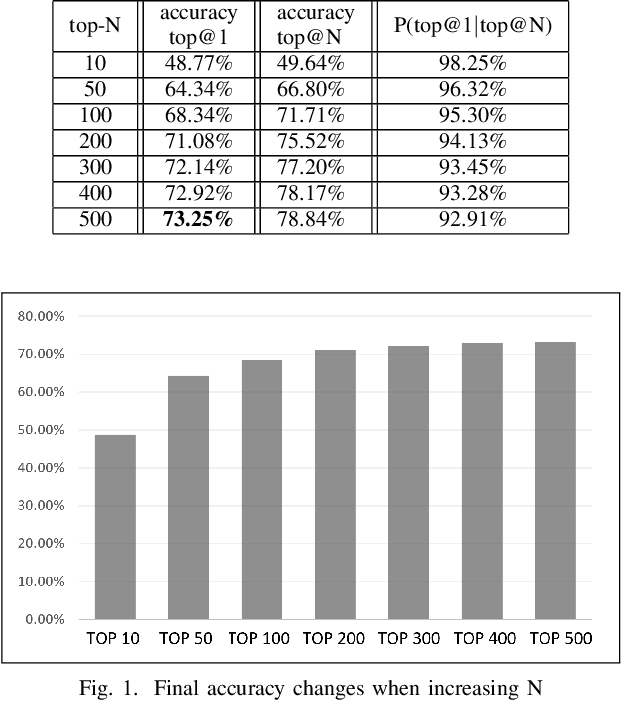


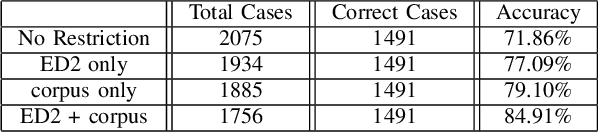
Spelling irregularities, known now as spelling mistakes, have been found for several centuries. As humans, we are able to understand most of the misspelled words based on their location in the sentence, perceived pronunciation, and context. Unlike humans, computer systems do not possess the convenient auto complete functionality of which human brains are capable. While many programs provide spelling correction functionality, many systems do not take context into account. Moreover, Artificial Intelligence systems function in the way they are trained on. With many current Natural Language Processing (NLP) systems trained on grammatically correct text data, many are vulnerable against adversarial examples, yet correctly spelled text processing is crucial for learning. In this paper, we investigate how spelling errors can be corrected in context, with a pre-trained language model BERT. We present two experiments, based on BERT and the edit distance algorithm, for ranking and selecting candidate corrections. The results of our experiments demonstrated that when combined properly, contextual word embeddings of BERT and edit distance are capable of effectively correcting spelling errors.