 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn A Scale From 1 to 5: Quantifying Hallucination in Faithfulness Evaluation
Oct 16, 2024



Hallucination has been a popular topic in natural language generation (NLG). In real-world applications, unfaithful content can result in bad data quality or loss of trust from end users. Thus, it is crucial to fact-check before adopting NLG for production usage, which can be expensive if done manually. In this paper, we investigate automated faithfulness evaluation in guided NLG. We developed a rubrics template and use large language models (LLMs) to score the generation into quantifiable scales. We compared popular LLMs as well as the widely adopted natural language inference (NLI) models in scoring quality and sensitivity. In addition, we developed methods to generation synthetic unfaithful data, as well as a heuristics to quantify the percentage of hallucination. Our results on 4 travel-domain industry dataset show that GPT-4 can provide accurate judgement and explanation on whether a source and a generation are factually consistent. Furthermore, we found that tuning NLI models on synthetic data can improve performance. Lastly, we present insights on latency and cost for deploying such system.
Federated Graph Representation Learning using Self-Supervision
Oct 27, 2022

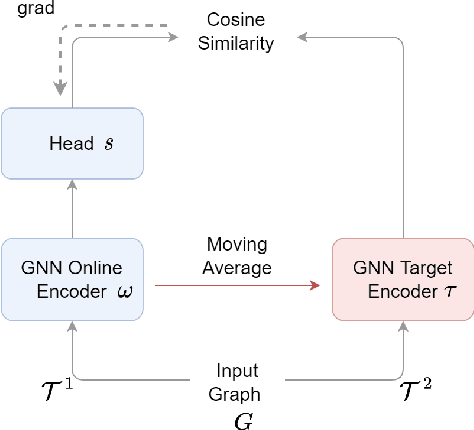
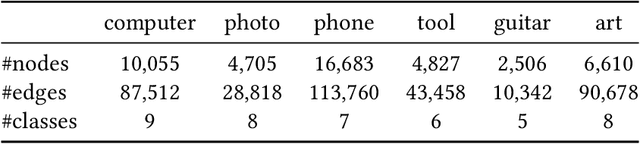
Federated graph representation learning (FedGRL) brings the benefits of distributed training to graph structured data while simultaneously addressing some privacy and compliance concerns related to data curation. However, several interesting real-world graph data characteristics viz. label deficiency and downstream task heterogeneity are not taken into consideration in current FedGRL setups. In this paper, we consider a realistic and novel problem setting, wherein cross-silo clients have access to vast amounts of unlabeled data with limited or no labeled data and additionally have diverse downstream class label domains. We then propose a novel FedGRL formulation based on model interpolation where we aim to learn a shared global model that is optimized collaboratively using a self-supervised objective and gets downstream task supervision through local client models. We provide a specific instantiation of our general formulation using BGRL a SoTA self-supervised graph representation learning method and we empirically verify its effectiveness through realistic cross-slio datasets: (1) we adapt the Twitch Gamer Network which naturally simulates a cross-geo scenario and show that our formulation can provide consistent and avg. 6.1% gains over traditional supervised federated learning objectives and on avg. 1.7% gains compared to individual client specific self-supervised training and (2) we construct and introduce a new cross-silo dataset called Amazon Co-purchase Networks that have both the characteristics of the motivated problem setting. And, we witness on avg. 11.5% gains over traditional supervised federated learning and on avg. 1.9% gains over individually trained self-supervised models. Both experimental results point to the effectiveness of our proposed formulation. Finally, both our novel problem setting and dataset contributions provide new avenues for the research in FedGRL.