 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASPR: Customer Activity Sequence-based Prediction and Representation
Nov 29, 2022



Tasks critical to enterprise profitability, such as customer churn prediction, fraudulent account detection or customer lifetime value estimation, are often tackled by models trained on features engineered from customer data in tabular format. Application-specific feature engineering adds development, operationalization and maintenance costs over time. Recent advances in representation learning present an opportunity to simplify and generalize feature engineering across applications. When applying these advancements to tabular data researchers deal with data heterogeneity, variations in customer engagement history or the sheer volume of enterprise datasets. In this paper, we propose a novel approach to encode tabular data containing customer transactions, purchase history and other interactions into a generic representation of a customer's association with the business. We then evaluate these embeddings as features to train multiple models spanning a variety of applications. CASPR, Customer Activity Sequence-based Prediction and Representation, applies Transformer architecture to encode activity sequences to improve model performance and avoid bespoke feature engineering across applications. Our experiments at scale validate CASPR for both small and large enterprise applications.
Federated Graph Representation Learning using Self-Supervision
Oct 27, 2022

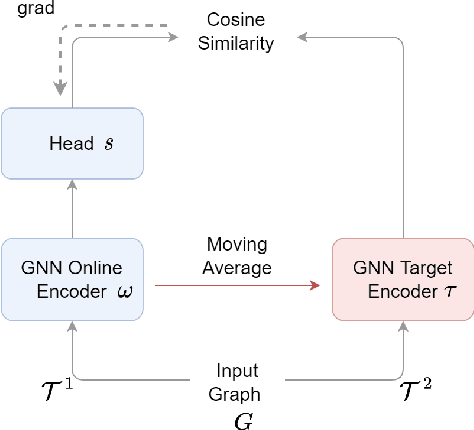
Federated graph representation learning (FedGRL) brings the benefits of distributed training to graph structured data while simultaneously addressing some privacy and compliance concerns related to data curation. However, several interesting real-world graph data characteristics viz. label deficiency and downstream task heterogeneity are not taken into consideration in current FedGRL setups. In this paper, we consider a realistic and novel problem setting, wherein cross-silo clients have access to vast amounts of unlabeled data with limited or no labeled data and additionally have diverse downstream class label domains. We then propose a novel FedGRL formulation based on model interpolation where we aim to learn a shared global model that is optimized collaboratively using a self-supervised objective and gets downstream task supervision through local client models. We provide a specific instantiation of our general formulation using BGRL a SoTA self-supervised graph representation learning method and we empirically verify its effectiveness through realistic cross-slio datasets: (1) we adapt the Twitch Gamer Network which naturally simulates a cross-geo scenario and show that our formulation can provide consistent and avg. 6.1% gains over traditional supervised federated learning objectives and on avg. 1.7% gains compared to individual client specific self-supervised training and (2) we construct and introduce a new cross-silo dataset called Amazon Co-purchase Networks that have both the characteristics of the motivated problem setting. And, we witness on avg. 11.5% gains over traditional supervised federated learning and on avg. 1.9% gains over individually trained self-supervised models. Both experimental results point to the effectiveness of our proposed formulation. Finally, both our novel problem setting and dataset contributions provide new avenues for the research in FedGRL.
Max-Quantile Grouped Infinite-Arm Bandits
Oct 04, 2022
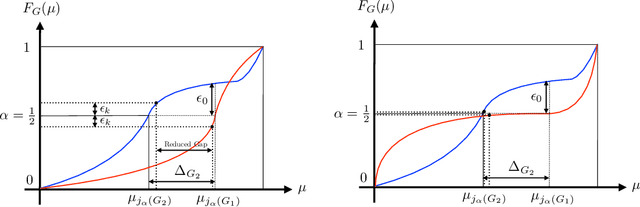
In this paper, we consider a bandit problem in which there are a number of groups each consisting of infinitely many arms. Whenever a new arm is requested from a given group, its mean reward is drawn from an unknown reservoir distribution (different for each group), and the uncertainty in the arm's mean reward can only be reduced via subsequent pulls of the arm. The goal is to identify the infinite-arm group whose reservoir distribution has the highest $(1-\alpha)$-quantile (e.g., median if $\alpha = \frac{1}{2}$), using as few total arm pulls as possible. We introduce a two-step algorithm that first requests a fixed number of arms from each group and then runs a finite-arm grouped max-quantile bandit algorithm. We characterize both the instance-dependent and worst-case regret, and provide a matching lower bound for the latter, while discussing various strengths, weaknesses, algorithmic improvements, and potential lower bounds associated with our instance-dependent upper bounds.