 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluate Summarization in Fine-Granularity: Auto Evaluation with LLM
Dec 27, 2024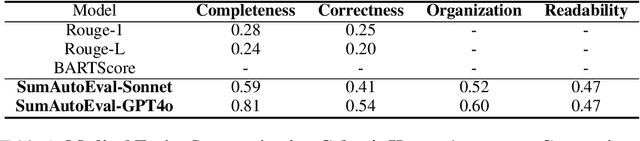
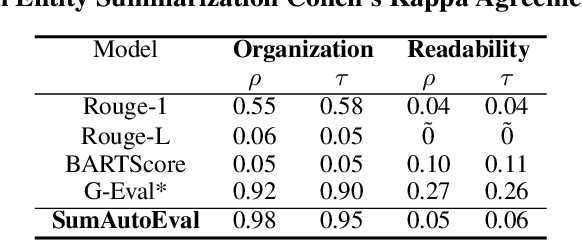
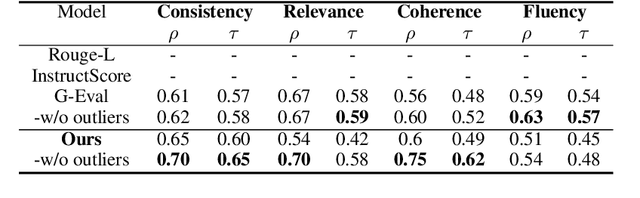
Due to the exponential growth of information and the need for efficient information consumption the task of summarization has gained paramount importance. Evaluating summarization accurately and objectively presents significant challenges, particularly when dealing with long and unstructured texts rich in content. Existing methods, such as ROUGE (Lin, 2004) and embedding similarities, often yield scores that have low correlation with human judgements and are also not intuitively understandable, making it difficult to gauge the true quality of the summaries. LLMs can mimic human in giving subjective reviews but subjective scores are hard to interpret and justify. They can be easily manipulated by altering the models and the tones of the prompts. In this paper, we introduce a novel evaluation methodology and tooling designed to address these challenges, providing a more comprehensive, accurate and interpretable assessment of summarization outputs. Our method (SumAutoEval) proposes and evaluates metrics at varying granularity levels, giving objective scores on 4 key dimensions such as completeness, correctness, Alignment and readability. We empirically demonstrate, that SumAutoEval enhances the understanding of output quality with better human correlation.
A Continued Pretrained LLM Approach for Automatic Medical Note Generation
Mar 14, 2024



LLMs are revolutionizing NLP tasks. However, the most powerful LLM, like GPT-4, is too costly for most domain-specific scenarios. We present the first continuously trained 13B Llama2-based LLM that is purpose-built for medical conversations and measured on automated scribing. Our results show that our model outperforms GPT-4 in PubMedQA with 76.6\% accuracy and matches its performance in summarizing medical conversations into SOAP notes. Notably, our model exceeds GPT-4 in capturing a higher number of correct medical concepts and outperforms human scribes with higher correctness and completeness.
CASPR: Customer Activity Sequence-based Prediction and Representation
Nov 29, 2022Tasks critical to enterprise profitability, such as customer churn prediction, fraudulent account detection or customer lifetime value estimation, are often tackled by models trained on features engineered from customer data in tabular format. Application-specific feature engineering adds development, operationalization and maintenance costs over time. Recent advances in representation learning present an opportunity to simplify and generalize feature engineering across applications. When applying these advancements to tabular data researchers deal with data heterogeneity, variations in customer engagement history or the sheer volume of enterprise datasets. In this paper, we propose a novel approach to encode tabular data containing customer transactions, purchase history and other interactions into a generic representation of a customer's association with the business. We then evaluate these embeddings as features to train multiple models spanning a variety of applications. CASPR, Customer Activity Sequence-based Prediction and Representation, applies Transformer architecture to encode activity sequences to improve model performance and avoid bespoke feature engineering across applications. Our experiments at scale validate CASPR for both small and large enterprise applications.