 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASPR: Customer Activity Sequence-based Prediction and Representation
Nov 29, 2022



Tasks critical to enterprise profitability, such as customer churn prediction, fraudulent account detection or customer lifetime value estimation, are often tackled by models trained on features engineered from customer data in tabular format. Application-specific feature engineering adds development, operationalization and maintenance costs over time. Recent advances in representation learning present an opportunity to simplify and generalize feature engineering across applications. When applying these advancements to tabular data researchers deal with data heterogeneity, variations in customer engagement history or the sheer volume of enterprise datasets. In this paper, we propose a novel approach to encode tabular data containing customer transactions, purchase history and other interactions into a generic representation of a customer's association with the business. We then evaluate these embeddings as features to train multiple models spanning a variety of applications. CASPR, Customer Activity Sequence-based Prediction and Representation, applies Transformer architecture to encode activity sequences to improve model performance and avoid bespoke feature engineering across applications. Our experiments at scale validate CASPR for both small and large enterprise applications.
Mitigating the Impact of Speech Recognition Errors on Chatbot using Sequence-to-Sequence Model
Dec 02, 2017

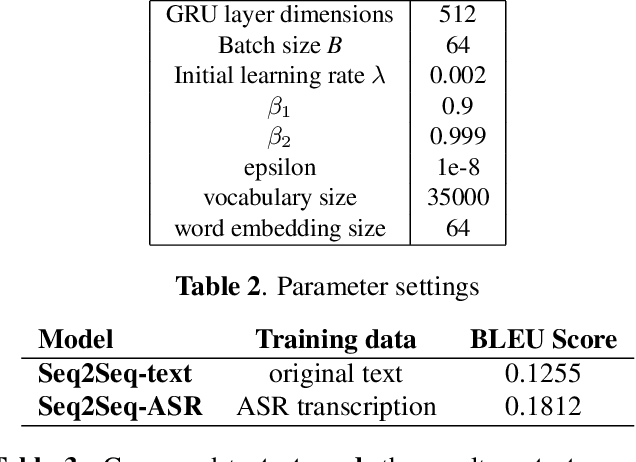

We apply sequence-to-sequence model to mitigate the impact of speech recognition errors on open domain end-to-end dialog generation. We cast the task as a domain adaptation problem where ASR transcriptions and original text are in two different domains. In this paper, our proposed model includes two individual encoders for each domain data and make their hidden states similar to ensure the decoder predict the same dialog text. The method shows that the sequence-to-sequence model can learn the ASR transcriptions and original text pair having the same meaning and eliminate the speech recognition errors. Experimental results on Cornell movie dialog dataset demonstrate that the domain adaption system help the spoken dialog system generate more similar responses with the original text answers.