 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Impact of Speech Recognition Errors on Chatbot using Sequence-to-Sequence Model
Dec 02, 2017

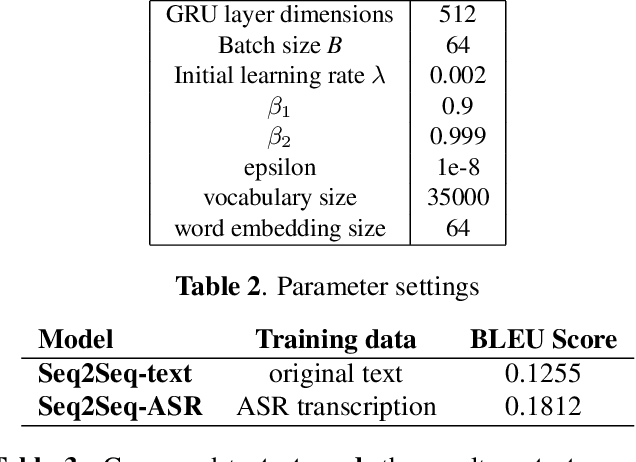

We apply sequence-to-sequence model to mitigate the impact of speech recognition errors on open domain end-to-end dialog generation. We cast the task as a domain adaptation problem where ASR transcriptions and original text are in two different domains. In this paper, our proposed model includes two individual encoders for each domain data and make their hidden states similar to ensure the decoder predict the same dialog text. The method shows that the sequence-to-sequence model can learn the ASR transcriptions and original text pair having the same meaning and eliminate the speech recognition errors. Experimental results on Cornell movie dialog dataset demonstrate that the domain adaption system help the spoken dialog system generate more similar responses with the original text answers.