 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Graph Representation Learning using Self-Supervision
Oct 27, 2022

Federated graph representation learning (FedGRL) brings the benefits of distributed training to graph structured data while simultaneously addressing some privacy and compliance concerns related to data curation. However, several interesting real-world graph data characteristics viz. label deficiency and downstream task heterogeneity are not taken into consideration in current FedGRL setups. In this paper, we consider a realistic and novel problem setting, wherein cross-silo clients have access to vast amounts of unlabeled data with limited or no labeled data and additionally have diverse downstream class label domains. We then propose a novel FedGRL formulation based on model interpolation where we aim to learn a shared global model that is optimized collaboratively using a self-supervised objective and gets downstream task supervision through local client models. We provide a specific instantiation of our general formulation using BGRL a SoTA self-supervised graph representation learning method and we empirically verify its effectiveness through realistic cross-slio datasets: (1) we adapt the Twitch Gamer Network which naturally simulates a cross-geo scenario and show that our formulation can provide consistent and avg. 6.1% gains over traditional supervised federated learning objectives and on avg. 1.7% gains compared to individual client specific self-supervised training and (2) we construct and introduce a new cross-silo dataset called Amazon Co-purchase Networks that have both the characteristics of the motivated problem setting. And, we witness on avg. 11.5% gains over traditional supervised federated learning and on avg. 1.9% gains over individually trained self-supervised models. Both experimental results point to the effectiveness of our proposed formulation. Finally, both our novel problem setting and dataset contributions provide new avenues for the research in FedGRL.
OCTAL: Graph Representation Learning for LTL Model Checking
Jul 26, 2022Model Checking is widely applied in verifying the correctness of complex and concurrent systems against a specification. Pure symbolic approaches while popular, still suffer from the state space explosion problem that makes them impractical for large scale systems and/or specifications. In this paper, we propose to use graph representation learning (GRL) for solving linear temporal logic (LTL) model checking, where the system and the specification are expressed by a B\"uchi automaton and an LTL formula respectively. A novel GRL-based framework OCTAL, is designed to learn the representation of the graph-structured system and specification, which reduces the model checking problem to binary classification in the latent space. The empirical experiments show that OCTAL achieves comparable accuracy against canonical SOTA model checkers on three different datasets, with up to $5\times$ overall speedup and above $63\times$ for satisfiability checking alone.
Adversarial Graph Augmentation to Improve Graph Contrastive Learning
Jun 25, 2021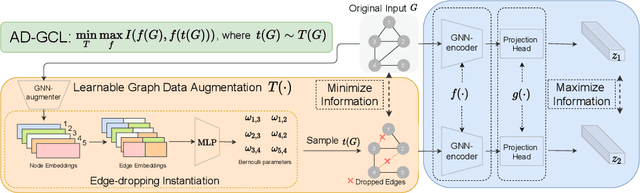
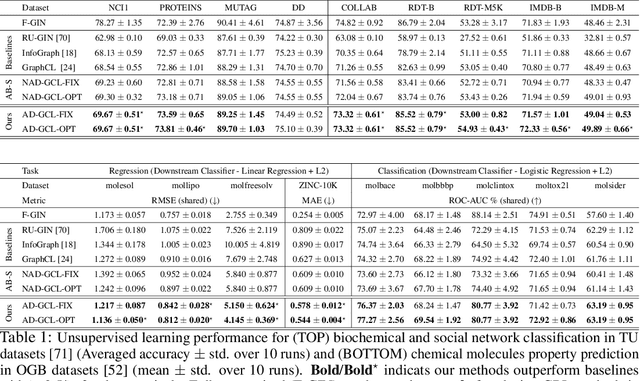
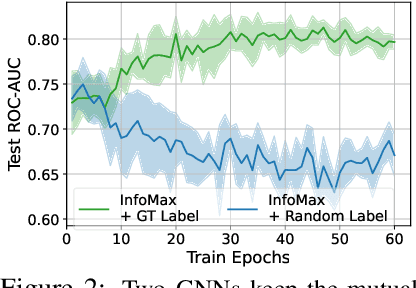
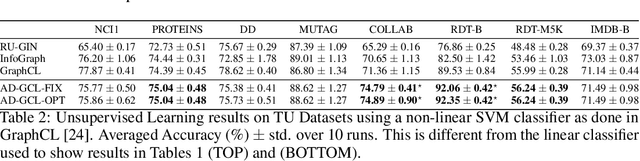
Self-supervised learning of graph neural networks (GNN) is in great need because of the widespread label scarcity issue in real-world graph/network data. Graph contrastive learning (GCL), by training GNNs to maximize the correspondence between the representations of the same graph in its different augmented forms, may yield robust and transferable GNNs even without using labels. However, GNNs trained by traditional GCL often risk capturing redundant graph features and thus may be brittle and provide sub-par performance in downstream tasks. Here, we propose a novel principle, termed adversarial-GCL (AD-GCL), which enables GNNs to avoid capturing redundant information during the training by optimizing adversarial graph augmentation strategies used in GCL. We pair AD-GCL with theoretical explanations and design a practical instantiation based on trainable edge-dropping graph augmentation. We experimentally validate AD-GCL by comparing with the state-of-the-art GCL methods and achieve performance gains of up-to $14\%$ in unsupervised, $6\%$ in transfer, and $3\%$ in semi-supervised learning settings overall with 18 different benchmark datasets for the tasks of molecule property regression and classification, and social network classification.
Breaking the Limit of Graph Neural Networks by Improving the Assortativity of Graphs with Local Mixing Patterns
Jun 11, 2021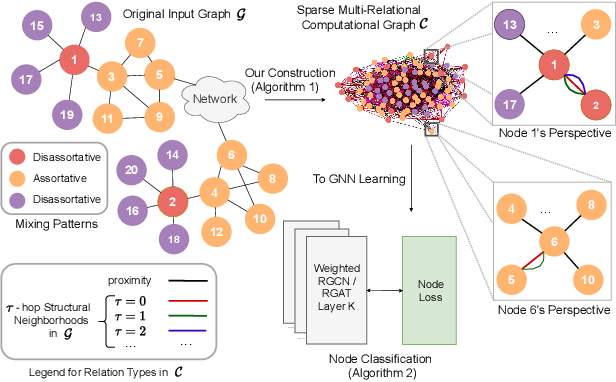
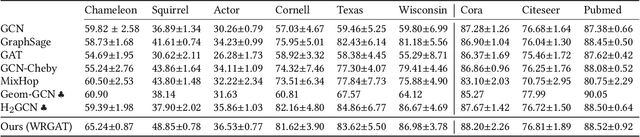
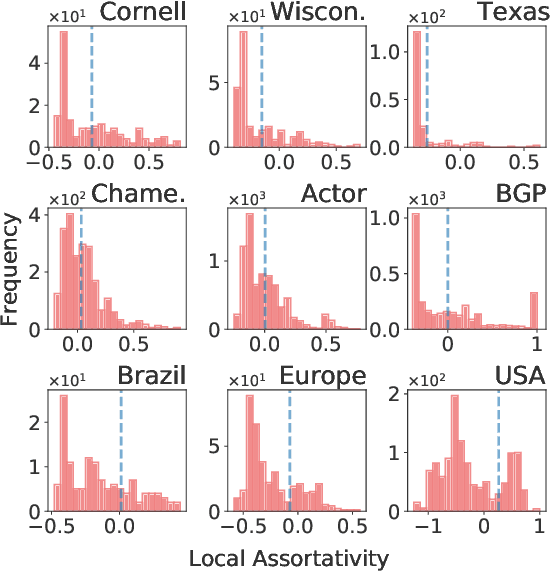
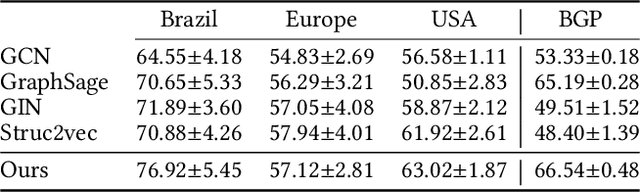
Graph neural networks (GNNs) have achieved tremendous success on multiple graph-based learning tasks by fusing network structure and node features. Modern GNN models are built upon iterative aggregation of neighbor's/proximity features by message passing. Its prediction performance has been shown to be strongly bounded by assortative mixing in the graph, a key property wherein nodes with similar attributes mix/connect with each other. We observe that real world networks exhibit heterogeneous or diverse mixing patterns and the conventional global measurement of assortativity, such as global assortativity coefficient, may not be a representative statistic in quantifying this mixing. We adopt a generalized concept, node-level assortativity, one that is based at the node level to better represent the diverse patterns and accurately quantify the learnability of GNNs. We find that the prediction performance of a wide range of GNN models is highly correlated with the node level assortativity. To break this limit, in this work, we focus on transforming the input graph into a computation graph which contains both proximity and structural information as distinct type of edges. The resulted multi-relational graph has an enhanced level of assortativity and, more importantly, preserves rich information from the original graph. We then propose to run GNNs on this computation graph and show that adaptively choosing between structure and proximity leads to improved performance under diverse mixing. Empirically, we show the benefits of adopting our transformation framework for semi-supervised node classification task on a variety of real world graph learning benchmarks.
A Hybrid Model for Learning Embeddings and Logical Rules Simultaneously from Knowledge Graphs
Sep 22, 2020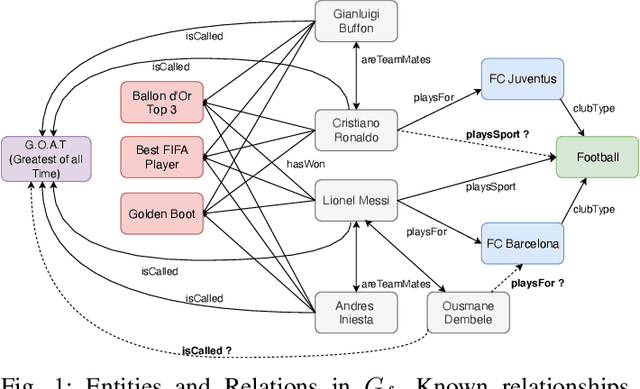
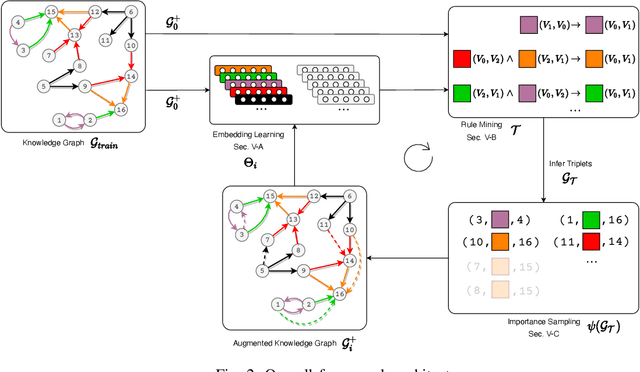
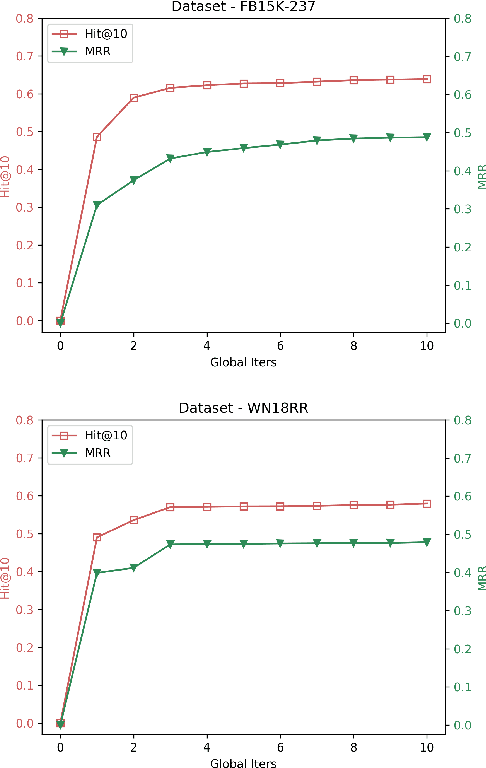

The problem of knowledge graph (KG) reasoning has been widely explored by traditional rule-based systems and more recently by knowledge graph embedding methods. While logical rules can capture deterministic behavior in a KG they are brittle and mining ones that infer facts beyond the known KG is challenging. Probabilistic embedding methods are effective in capturing global soft statistical tendencies and reasoning with them is computationally efficient. While embedding representations learned from rich training data are expressive, incompleteness and sparsity in real-world KGs can impact their effectiveness. We aim to leverage the complementary properties of both methods to develop a hybrid model that learns both high-quality rules and embeddings simultaneously. Our method uses a cross feedback paradigm wherein, an embedding model is used to guide the search of a rule mining system to mine rules and infer new facts. These new facts are sampled and further used to refine the embedding model. Experiments on multiple benchmark datasets show the effectiveness of our method over other competitive standalone and hybrid baselines. We also show its efficacy in a sparse KG setting and finally explore the connection with negative sampling.