 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Really Forget? Evaluating Unlearning with Knowledge Correlation and Confidence Awareness
Jun 06, 2025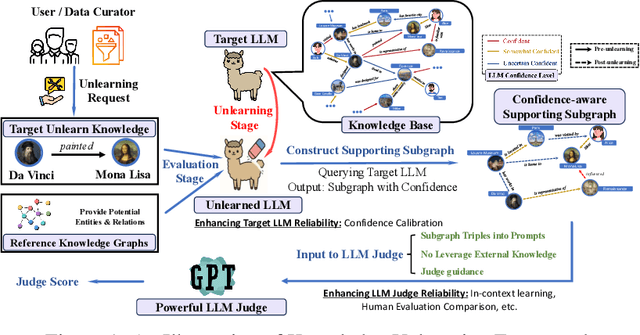
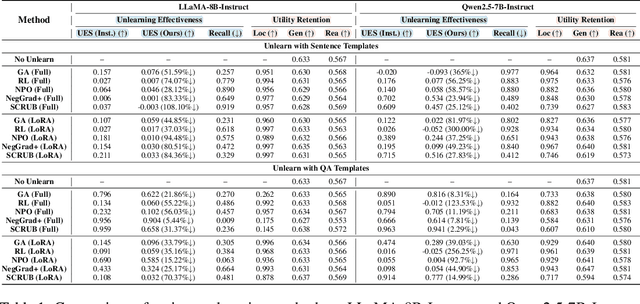
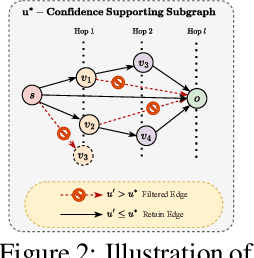
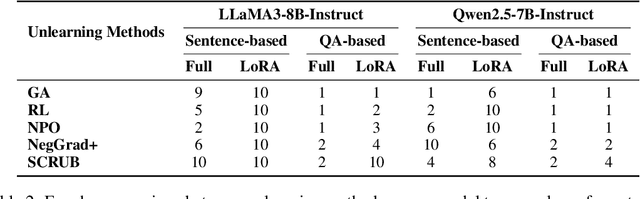
Machine unlearning techniques aim to mitigate unintended memorization in large language models (LLMs). However, existing approaches predominantly focus on the explicit removal of isolated facts, often overlooking latent inferential dependencies and the non-deterministic nature of knowledge within LLMs. Consequently, facts presumed forgotten may persist implicitly through correlated information. To address these challenges, we propose a knowledge unlearning evaluation framework that more accurately captures the implicit structure of real-world knowledge by representing relevant factual contexts as knowledge graphs with associated confidence scores. We further develop an inference-based evaluation protocol leveraging powerful LLMs as judges; these judges reason over the extracted knowledge subgraph to determine unlearning success. Our LLM judges utilize carefully designed prompts and are calibrated against human evaluations to ensure their trustworthiness and stability. Extensive experiments on our newly constructed benchmark demonstrate that our framework provides a more realistic and rigorous assessment of unlearning performance. Moreover, our findings reveal that current evaluation strategies tend to overestimate unlearning effectiveness. Our code is publicly available at https://github.com/Graph-COM/Knowledge_Unlearning.git.
Privately Learning from Graphs with Applications in Fine-tuning Large Language Models
Oct 10, 2024



Graphs offer unique insights into relationships and interactions between entities, complementing data modalities like text, images, and videos. By incorporating relational information from graph data, AI models can extend their capabilities beyond traditional tasks. However, relational data in sensitive domains such as finance and healthcare often contain private information, making privacy preservation crucial. Existing privacy-preserving methods, such as DP-SGD, which rely on gradient decoupling assumptions, are not well-suited for relational learning due to the inherent dependencies between coupled training samples. To address this challenge, we propose a privacy-preserving relational learning pipeline that decouples dependencies in sampled relations during training, ensuring differential privacy through a tailored application of DP-SGD. We apply this method to fine-tune large language models (LLMs) on sensitive graph data, and tackle the associated computational complexities. Our approach is evaluated on LLMs of varying sizes (e.g., BERT, Llama2) using real-world relational data from four text-attributed graphs. The results demonstrate significant improvements in relational learning tasks, all while maintaining robust privacy guarantees during training. Additionally, we explore the trade-offs between privacy, utility, and computational efficiency, offering insights into the practical deployment of our approach. Code is available at https://github.com/Graph-COM/PvGaLM.
SocialCVAE: Predicting Pedestrian Trajectory via Interaction Conditioned Latents
Feb 27, 2024



Pedestrian trajectory prediction is the key technology in many applications for providing insights into human behavior and anticipating human future motions. Most existing empirical models are explicitly formulated by observed human behaviors using explicable mathematical terms with a deterministic nature, while recent work has focused on developing hybrid models combined with learning-based techniques for powerful expressiveness while maintaining explainability. However, the deterministic nature of the learned steering behaviors from the empirical models limits the models' practical performance. To address this issue, this work proposes the social conditional variational autoencoder (SocialCVAE) for predicting pedestrian trajectories, which employs a CVAE to explore behavioral uncertainty in human motion decisions. SocialCVAE learns socially reasonable motion randomness by utilizing a socially explainable interaction energy map as the CVAE's condition, which illustrates the future occupancy of each pedestrian's local neighborhood area. The energy map is generated using an energy-based interaction model, which anticipates the energy cost (i.e., repulsion intensity) of pedestrians' interactions with neighbors. Experimental results on two public benchmarks including 25 scenes demonstrate that SocialCVAE significantly improves prediction accuracy compared with the state-of-the-art methods, with up to 16.85% improvement in Average Displacement Error (ADE) and 69.18% improvement in Final Displacement Error (FDE).
Learning Scalable Structural Representations for Link Prediction with Bloom Signatures
Dec 28, 2023



Graph neural networks (GNNs) have shown great potential in learning on graphs, but they are known to perform sub-optimally on link prediction tasks. Existing GNNs are primarily designed to learn node-wise representations and usually fail to capture pairwise relations between target nodes, which proves to be crucial for link prediction. Recent works resort to learning more expressive edge-wise representations by enhancing vanilla GNNs with structural features such as labeling tricks and link prediction heuristics, but they suffer from high computational overhead and limited scalability. To tackle this issue, we propose to learn structural link representations by augmenting the message-passing framework of GNNs with Bloom signatures. Bloom signatures are hashing-based compact encodings of node neighborhoods, which can be efficiently merged to recover various types of edge-wise structural features. We further show that any type of neighborhood overlap-based heuristic can be estimated by a neural network that takes Bloom signatures as input. GNNs with Bloom signatures are provably more expressive than vanilla GNNs and also more scalable than existing edge-wise models. Experimental results on five standard link prediction benchmarks show that our proposed model achieves comparable or better performance than existing edge-wise GNN models while being 3-200 $\times$ faster and more memory-efficient for online inference.
On the Inherent Privacy Properties of Discrete Denoising Diffusion Models
Oct 24, 2023



Privacy concerns have led to a surge in the creation of synthetic datasets, with diffusion models emerging as a promising avenue. Although prior studies have performed empirical evaluations on these models, there has been a gap in providing a mathematical characterization of their privacy-preserving capabilities. To address this, we present the pioneering theoretical exploration of the privacy preservation inherent in discrete diffusion models (DDMs) for discrete dataset generation. Focusing on per-instance differential privacy (pDP), our framework elucidates the potential privacy leakage for each data point in a given training dataset, offering insights into data preprocessing to reduce privacy risks of the synthetic dataset generation via DDMs. Our bounds also show that training with $s$-sized data points leads to a surge in privacy leakage from $(\epsilon, \mathcal{O}(\frac{1}{s^2\epsilon}))$-pDP to $(\epsilon, \mathcal{O}(\frac{1}{s\epsilon}))$-pDP during the transition from the pure noise to the synthetic clean data phase, and a faster decay in diffusion coefficients amplifies the privacy guarantee. Finally, we empirically verify our theoretical findings on both synthetic and real-world datasets.
OCTAL: Graph Representation Learning for LTL Model Checking
Aug 19, 2023Model Checking is widely applied in verifying the correctness of complex and concurrent systems against a specification. Pure symbolic approaches while popular, suffer from the state space explosion problem due to cross product operations required that make them prohibitively expensive for large-scale systems and/or specifications. In this paper, we propose to use graph representation learning (GRL) for solving linear temporal logic (LTL) model checking, where the system and the specification are expressed by a B{\"u}chi automaton and an LTL formula, respectively. A novel GRL-based framework \model, is designed to learn the representation of the graph-structured system and specification, which reduces the model checking problem to binary classification. Empirical experiments on two model checking scenarios show that \model achieves promising accuracy, with up to $11\times$ overall speedup against canonical SOTA model checkers and $31\times$ for satisfiability checking alone.
SUREL+: Moving from Walks to Sets for Scalable Subgraph-based Graph Representation Learning
Mar 06, 2023Subgraph-based graph representation learning (SGRL) has recently emerged as a powerful tool in many prediction tasks on graphs due to its advantages in model expressiveness and generalization ability. Most previous SGRL models face computational issues associated with the high cost of extracting subgraphs for each training or testing query. Recently, SUREL has been proposed as a new framework to accelerate SGRL, which samples random walks offline and joins these walks as subgraphs online for prediction. Due to the reusability of sampled walks across different queries, SUREL achieves state-of-the-art performance in both scalability and prediction accuracy. However, SUREL still suffers from high computational overhead caused by node redundancy in sampled walks. In this work, we propose a novel framework SUREL+ that upgrades SUREL by using node sets instead of walks to represent subgraphs. This set-based representation avoids node duplication by definition, but the sizes of node sets can be irregular. To address this issue, we design a dedicated sparse data structure to efficiently store and fast index node sets, and provide a specialized operator to join them in parallel batches. SUREL+ is modularized to support multiple types of set samplers, structural features, and neural encoders to complement the loss of structural information due to the reduction from walks to sets. Extensive experiments have been performed to validate SUREL+ in the prediction tasks of links, relation types, and higher-order patterns. SUREL+ achieves 3-11$\times$ speedups of SUREL while maintaining comparable or even better prediction performance; compared to other SGRL baselines, SUREL+ achieves $\sim$20$\times$ speedups and significantly improves the prediction accuracy.
Understanding Non-linearity in Graph Neural Networks from the Bayesian-Inference Perspective
Jul 27, 2022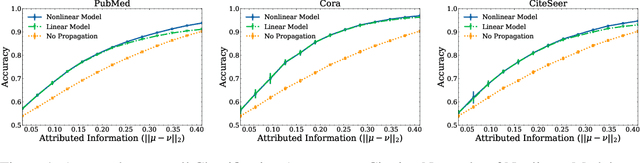

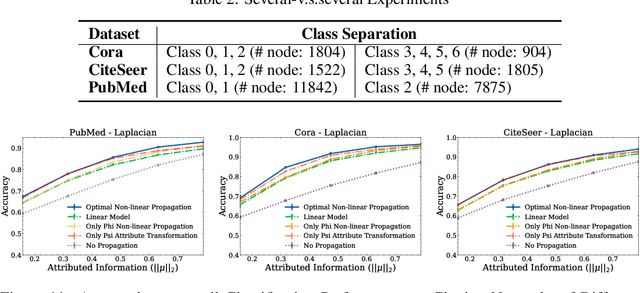
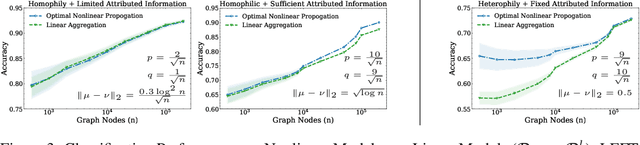
Graph neural networks (GNNs) have shown superiority in many prediction tasks over graphs due to their impressive capability of capturing nonlinear relations in graph-structured data. However, for node classification tasks, often, only marginal improvement of GNNs over their linear counterparts has been observed. Previous works provide very few understandings of this phenomenon. In this work, we resort to Bayesian learning to deeply investigate the functions of non-linearity in GNNs for node classification tasks. Given a graph generated from the statistical model CSBM, we observe that the max-a-posterior estimation of a node label given its own and neighbors' attributes consists of two types of non-linearity, a possibly non-linear transformation of node attributes and a ReLU-activated feature aggregation from neighbors. The latter surprisingly matches the type of non-linearity used in many GNN models. By further imposing Gaussian assumption on node attributes, we prove that the superiority of those ReLU activations is only significant when the node attributes are far more informative than the graph structure, which nicely matches many previous empirical observations. A similar argument can be achieved when there is a distribution shift of node attributes between the training and testing datasets. Finally, we verify our theory on both synthetic and real-world networks.
Equivariant and Stable Positional Encoding for More Powerful Graph Neural Networks
Mar 03, 2022
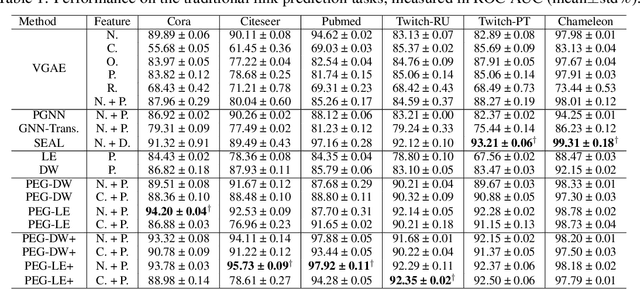
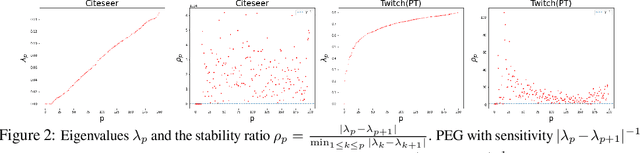
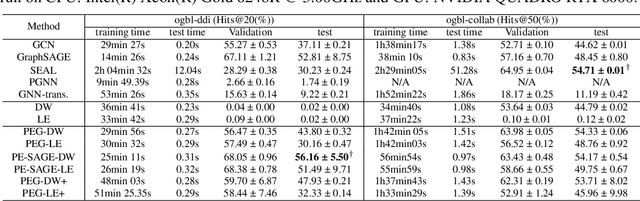
Graph neural networks (GNN) have shown great advantages in many graph-based learning tasks but often fail to predict accurately for a task-based on sets of nodes such as link/motif prediction and so on. Many works have recently proposed to address this problem by using random node features or node distance features. However, they suffer from either slow convergence, inaccurate prediction, or high complexity. In this work, we revisit GNNs that allow using positional features of nodes given by positional encoding (PE) techniques such as Laplacian Eigenmap, Deepwalk, etc. GNNs with PE often get criticized because they are not generalizable to unseen graphs (inductive) or stable. Here, we study these issues in a principled way and propose a provable solution, a class of GNN layers termed PEG with rigorous mathematical analysis. PEG uses separate channels to update the original node features and positional features. PEG imposes permutation equivariance w.r.t. the original node features and rotation equivariance w.r.t. the positional features simultaneously. Extensive link prediction experiments over 8 real-world networks demonstrate the advantages of PEG in generalization and scalability.