 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAter: A Workload-Adaptive Knob Tuning System based on Workload Compression
Mar 28, 2026Selecting appropriate values for the configurable parameters of Database Management Systems (DBMS) to improve performance is a significant challenge. Recent machine learning (ML)-based tuning systems have shown strong potential, but their practical adoption is often limited by the high tuning cost. This cost arises from two main factors: (1) the system needs to evaluate a large number of configurations to identify a satisfactory one, and (2) for each configuration, the system must execute the entire target workload on the DBMS, which is both time-consuming. Existing studies have primarily addressed the first factor by improving sample efficiency, that is, by reducing the number of configurations evaluated. However, the second factor, improving runtime efficiency by reducing the time required for each evaluation, has received limited attention and remains an underexplored direction. We develop WAter, a runtime-efficient and workload-adaptive tuning system that finds near-optimal configurations at a fraction of the tuning cost compared with state-of-the-art methods. We divide the tuning process into multiple time slices and evaluate only a small subset of queries from the workload in each slice. Different subsets are evaluated across slices, and a runtime profile is used to dynamically identify more representative subsets for evaluation in subsequent slices. At the end of each time slice, the most promising configurations are evaluated on the original workload to measure their actual performance. Evaluations demonstrate that WAter identifies the best-performing configurations with up to 73.5% less tuning time and achieves up to 16.2% higher performance than the best-performing alternative.
QUITE: A Query Rewrite System Beyond Rules with LLM Agents
Jun 09, 2025Query rewrite transforms SQL queries into semantically equivalent forms that run more efficiently. Existing approaches mainly rely on predefined rewrite rules, but they handle a limited subset of queries and can cause performance regressions. This limitation stems from three challenges of rule-based query rewrite: (1) it is hard to discover and verify new rules, (2) fixed rewrite rules do not generalize to new query patterns, and (3) some rewrite techniques cannot be expressed as fixed rules. Motivated by the fact that human experts exhibit significantly better rewrite ability but suffer from scalability, and Large Language Models (LLMs) have demonstrated nearly human-level semantic and reasoning abilities, we propose a new approach of using LLMs to rewrite SQL queries beyond rules. Due to the hallucination problems in LLMs, directly applying LLMs often leads to nonequivalent and suboptimal queries. To address this issue, we propose QUITE (query rewrite), a training-free and feedback-aware system based on LLM agents that rewrites SQL queries into semantically equivalent forms with significantly better performance, covering a broader range of query patterns and rewrite strategies compared to rule-based methods. Firstly, we design a multi-agent framework controlled by a finite state machine (FSM) to equip LLMs with the ability to use external tools and enhance the rewrite process with real-time database feedback. Secondly, we develop a rewrite middleware to enhance the ability of LLMs to generate optimized query equivalents. Finally, we employ a novel hint injection technique to improve execution plans for rewritten queries. Extensive experiments show that QUITE reduces query execution time by up to 35.8% over state-of-the-art approaches and produces 24.1% more rewrites than prior methods, covering query cases that earlier systems did not handle.
A Survey of Learned Indexes for the Multi-dimensional Space
Mar 11, 2024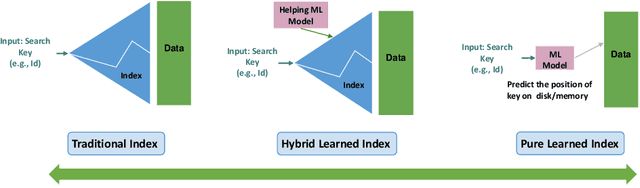


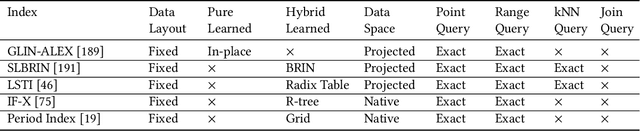
A recent research trend involves treating database index structures as Machine Learning (ML) models. In this domain, single or multiple ML models are trained to learn the mapping from keys to positions inside a data set. This class of indexes is known as "Learned Indexes." Learned indexes have demonstrated improved search performance and reduced space requirements for one-dimensional data. The concept of one-dimensional learned indexes has naturally been extended to multi-dimensional (e.g., spatial) data, leading to the development of "Learned Multi-dimensional Indexes". This survey focuses on learned multi-dimensional index structures. Specifically, it reviews the current state of this research area, explains the core concepts behind each proposed method, and classifies these methods based on several well-defined criteria. We present a taxonomy that classifies and categorizes each learned multi-dimensional index, and survey the existing literature on learned multi-dimensional indexes according to this taxonomy. Additionally, we present a timeline to illustrate the evolution of research on learned indexes. Finally, we highlight several open challenges and future research directions in this emerging and highly active field.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
SUREL+: Moving from Walks to Sets for Scalable Subgraph-based Graph Representation Learning
Mar 06, 2023Subgraph-based graph representation learning (SGRL) has recently emerged as a powerful tool in many prediction tasks on graphs due to its advantages in model expressiveness and generalization ability. Most previous SGRL models face computational issues associated with the high cost of extracting subgraphs for each training or testing query. Recently, SUREL has been proposed as a new framework to accelerate SGRL, which samples random walks offline and joins these walks as subgraphs online for prediction. Due to the reusability of sampled walks across different queries, SUREL achieves state-of-the-art performance in both scalability and prediction accuracy. However, SUREL still suffers from high computational overhead caused by node redundancy in sampled walks. In this work, we propose a novel framework SUREL+ that upgrades SUREL by using node sets instead of walks to represent subgraphs. This set-based representation avoids node duplication by definition, but the sizes of node sets can be irregular. To address this issue, we design a dedicated sparse data structure to efficiently store and fast index node sets, and provide a specialized operator to join them in parallel batches. SUREL+ is modularized to support multiple types of set samplers, structural features, and neural encoders to complement the loss of structural information due to the reduction from walks to sets. Extensive experiments have been performed to validate SUREL+ in the prediction tasks of links, relation types, and higher-order patterns. SUREL+ achieves 3-11$\times$ speedups of SUREL while maintaining comparable or even better prediction performance; compared to other SGRL baselines, SUREL+ achieves $\sim$20$\times$ speedups and significantly improves the prediction accuracy.
The "AI+R"-tree: An Instance-optimized R-tree
Jul 01, 2022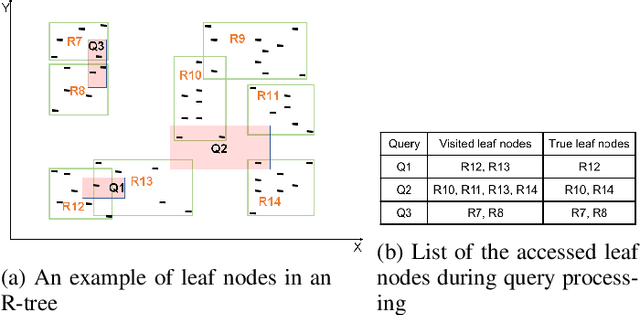

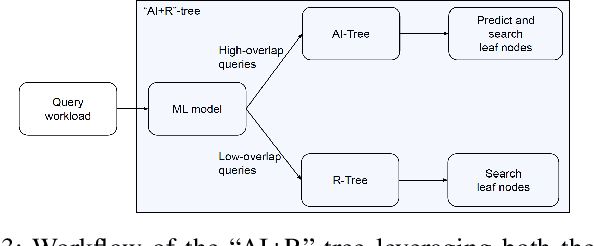
The emerging class of instance-optimized systems has shown potential to achieve high performance by specializing to a specific data and query workloads. Particularly, Machine Learning (ML) techniques have been applied successfully to build various instance-optimized components (e.g., learned indexes). This paper investigates to leverage ML techniques to enhance the performance of spatial indexes, particularly the R-tree, for a given data and query workloads. As the areas covered by the R-tree index nodes overlap in space, upon searching for a specific point in space, multiple paths from root to leaf may potentially be explored. In the worst case, the entire R-tree could be searched. In this paper, we define and use the overlap ratio to quantify the degree of extraneous leaf node accesses required by a range query. The goal is to enhance the query performance of a traditional R-tree for high-overlap range queries as they tend to incur long running-times. We introduce a new AI-tree that transforms the search operation of an R-tree into a multi-label classification task to exclude the extraneous leaf node accesses. Then, we augment a traditional R-tree to the AI-tree to form a hybrid "AI+R"-tree. The "AI+R"-tree can automatically differentiate between the high- and low-overlap queries using a learned model. Thus, the "AI+R"-tree processes high-overlap queries using the AI-tree, and the low-overlap queries using the R-tree. Experiments on real datasets demonstrate that the "AI+R"-tree can enhance the query performance over a traditional R-tree by up to 500%.
Algorithm and System Co-design for Efficient Subgraph-based Graph Representation Learning
Feb 28, 2022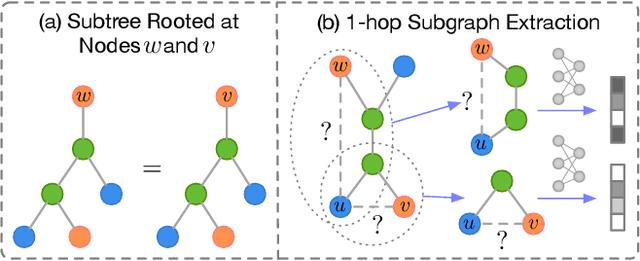

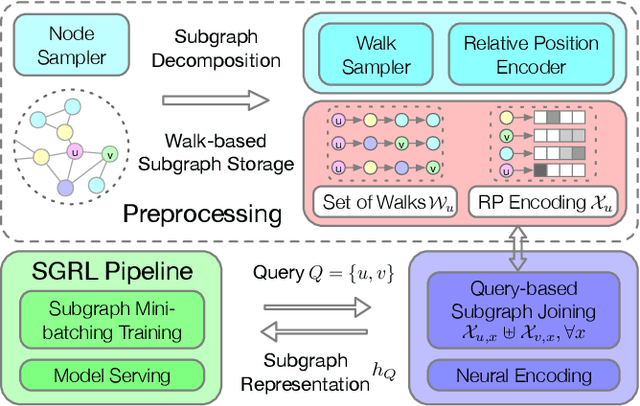
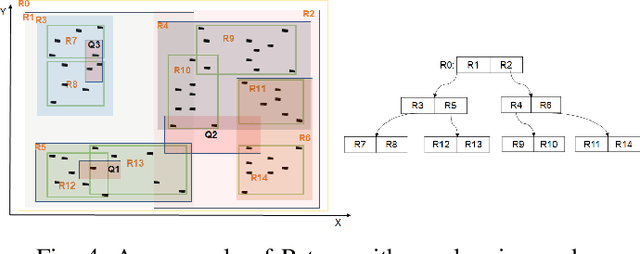
Subgraph-based graph representation learning (SGRL) has been recently proposed to deal with some fundamental challenges encountered by canonical graph neural networks (GNNs), and has demonstrated advantages in many important data science applications such as link, relation and motif prediction. However, current SGRL approaches suffer from a scalability issue since they require extracting subgraphs for each training and testing query. Recent solutions that scale up canonical GNNs may not apply to SGRL. Here, we propose a novel framework SUREL for scalable SGRL by co-designing the learning algorithm and its system support. SUREL adopts walk-based decomposition of subgraphs and reuses the walks to form subgraphs, which substantially reduces the redundancy of subgraph extraction and supports parallel computation. Experiments over seven homogeneous, heterogeneous and higher-order graphs with millions of nodes and edges demonstrate the effectiveness and scalability of SUREL. In particular, compared to SGRL baselines, SUREL achieves 10$\times$ speed-up with comparable or even better prediction performance; while compared to canonical GNNs, SUREL achieves 50% prediction accuracy improvement. SUREL is also applied to the brain vessel prediction task. SUREL significantly outperforms the state-of-the-art baseline in both prediction accuracy and efficiency.
Deep learning for prediction of hepatocellular carcinoma recurrence after resection or liver transplantation: a discovery and validation study
May 31, 2021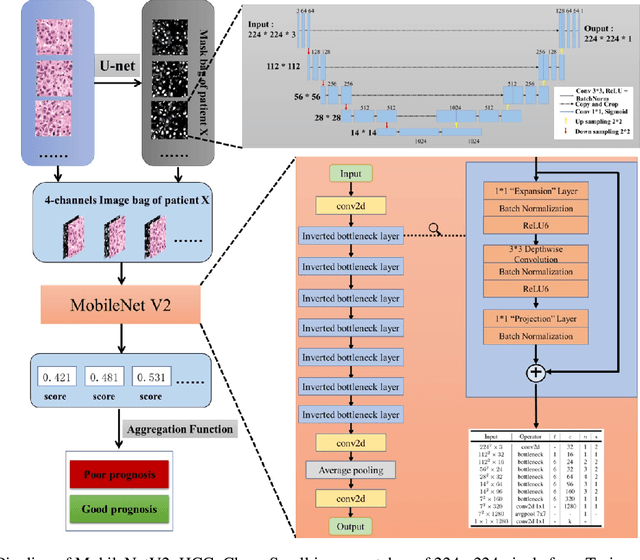
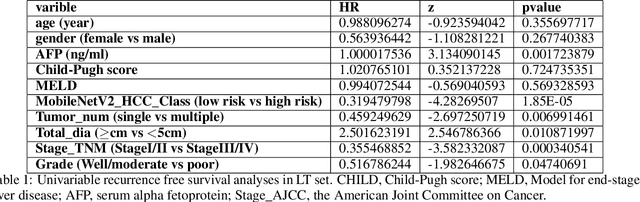
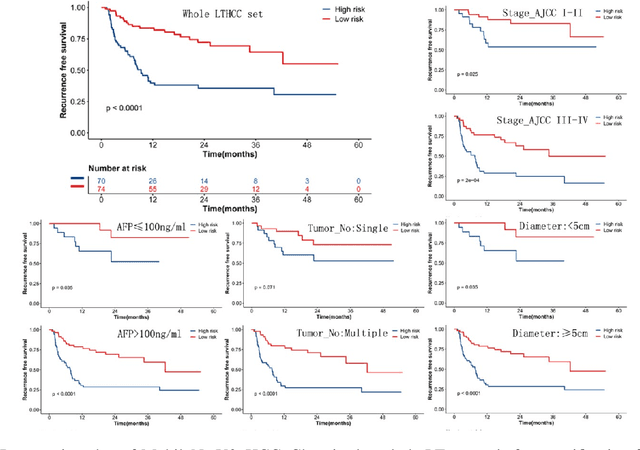
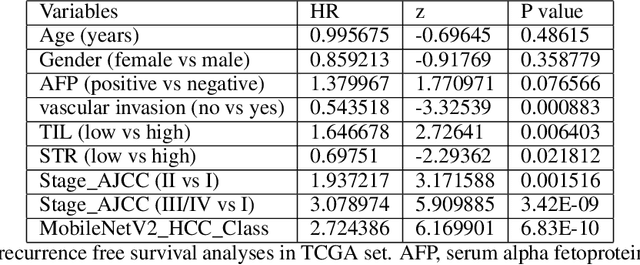
This study aimed to develop a classifier of prognosis after resection or liver transplantation (LT) for HCC by directly analysing the ubiquitously available histological images using deep learning based neural networks. Nucleus map set was used to train U-net to capture the nuclear architectural information. Train set included the patients with HCC treated by resection and has a distinct outcome. LT set contained patients with HCC treated by LT. Train set and its nuclear architectural information extracted by U-net were used to train MobileNet V2 based classifier (MobileNetV2_HCC_Class), purpose-built for classifying supersized heterogeneous images. The MobileNetV2_HCC_Class maintained relative higher discriminatory power than the other factors after HCC resection or LT in the independent validation set. Pathological review showed that the tumoral areas most predictive of recurrence were characterized by presence of stroma, high degree of cytological atypia, nuclear hyperchomasia, and a lack of immune infiltration. A clinically useful prognostic classifier was developed using deep learning allied to histological slides. The classifier has been extensively evaluated in independent patient populations with different treatment, and gives consistent excellent results across the classical clinical, biological and pathological features. The classifier assists in refining the prognostic prediction of HCC patients and identifying patients who would benefit from more intensive management.
Balance Scene Learning Mechanism for Offshore and Inshore Ship Detection in SAR Images
Jul 21, 2020
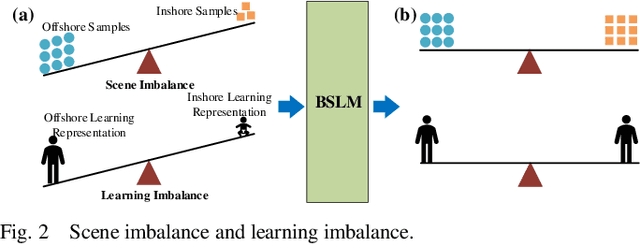
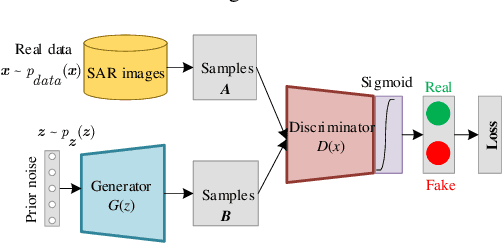
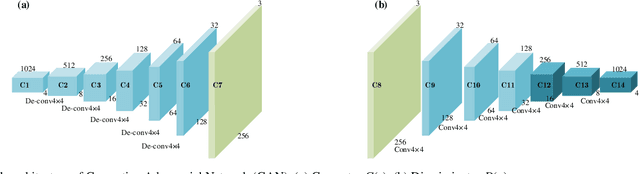
This letter proposes a novel Balance Scene Learning Mechanism (BSLM) for both offshore and inshore ship detection in SAR images.
Sherlock: Sparse Hierarchical Embeddings for Visually-aware One-class Collaborative Filtering
Apr 20, 2016

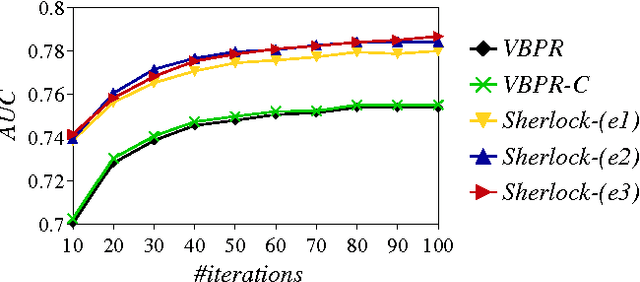
Building successful recommender systems requires uncovering the underlying dimensions that describe the properties of items as well as users' preferences toward them. In domains like clothing recommendation, explaining users' preferences requires modeling the visual appearance of the items in question. This makes recommendation especially challenging, due to both the complexity and subtlety of people's 'visual preferences,' as well as the scale and dimensionality of the data and features involved. Ultimately, a successful model should be capable of capturing considerable variance across different categories and styles, while still modeling the commonalities explained by `global' structures in order to combat the sparsity (e.g. cold-start), variability, and scale of real-world datasets. Here, we address these challenges by building such structures to model the visual dimensions across different product categories. With a novel hierarchical embedding architecture, our method accounts for both high-level (colorfulness, darkness, etc.) and subtle (e.g. casualness) visual characteristics simultaneously.