 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Learned Indexes for the Multi-dimensional Space
Mar 11, 2024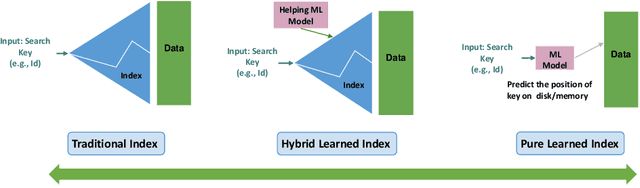


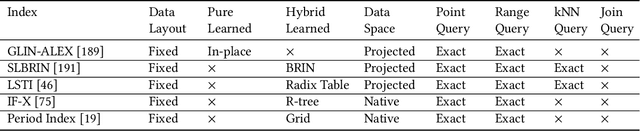
A recent research trend involves treating database index structures as Machine Learning (ML) models. In this domain, single or multiple ML models are trained to learn the mapping from keys to positions inside a data set. This class of indexes is known as "Learned Indexes." Learned indexes have demonstrated improved search performance and reduced space requirements for one-dimensional data. The concept of one-dimensional learned indexes has naturally been extended to multi-dimensional (e.g., spatial) data, leading to the development of "Learned Multi-dimensional Indexes". This survey focuses on learned multi-dimensional index structures. Specifically, it reviews the current state of this research area, explains the core concepts behind each proposed method, and classifies these methods based on several well-defined criteria. We present a taxonomy that classifies and categorizes each learned multi-dimensional index, and survey the existing literature on learned multi-dimensional indexes according to this taxonomy. Additionally, we present a timeline to illustrate the evolution of research on learned indexes. Finally, we highlight several open challenges and future research directions in this emerging and highly active field.
Binary Gaussian Copula Synthesis: A Novel Data Augmentation Technique to Advance ML-based Clinical Decision Support Systems for Early Prediction of Dialysis Among CKD Patients
Mar 01, 2024The Center for Disease Control estimates that over 37 million US adults suffer from chronic kidney disease (CKD), yet 9 out of 10 of these individuals are unaware of their condition due to the absence of symptoms in the early stages. It has a significant impact on patients' quality of life, particularly when it progresses to the need for dialysis. Early prediction of dialysis is crucial as it can significantly improve patient outcomes and assist healthcare providers in making timely and informed decisions. However, developing an effective machine learning (ML)-based Clinical Decision Support System (CDSS) for early dialysis prediction poses a key challenge due to the imbalanced nature of data. To address this challenge, this study evaluates various data augmentation techniques to understand their effectiveness on real-world datasets. We propose a new approach named Binary Gaussian Copula Synthesis (BGCS). BGCS is tailored for binary medical datasets and excels in generating synthetic minority data that mirrors the distribution of the original data. BGCS enhances early dialysis prediction by outperforming traditional methods in detecting dialysis patients. For the best ML model, Random Forest, BCGS achieved a 72% improvement, surpassing the state-of-the-art augmentation approaches. Also, we present a ML-based CDSS, designed to aid clinicians in making informed decisions. CDSS, which utilizes decision tree models, is developed to improve patient outcomes, identify critical variables, and thereby enable clinicians to make proactive decisions, and strategize treatment plans effectively for CKD patients who are more likely to require dialysis in the near future. Through comprehensive feature analysis and meticulous data preparation, we ensure that the CDSS's dialysis predictions are not only accurate but also actionable, providing a valuable tool in the management and treatment of CKD.