 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital-Twin Empowered Deep Reinforcement Learning For Site-Specific Radio Resource Management in NextG Wireless Aerial Corridor
Feb 03, 2026Joint base station (BS) association and beam selection in multi-UAV aerial corridors constitutes a challenging radio resource management (RRM) problem. It is driven by high-dimensional action spaces, need for substantial overhead to acquire global channel state information (CSI), rapidly varying propagation channels, and stringent latency requirements. Conventional combinatorial optimization methods, while near-optimal, are computationally prohibitive for real-time operation in such dynamic environments. While learning-based approaches can mitigate computational complexity and CSI overhead, the need for extensive site-specific (SS) datasets for model training remains a key challenge. To address these challenges, we develop a Digital Twin (DT)-enabled two-stage optimization framework that couples physics-based beam gain modeling with DRL for scalable online decision-making. In the first stage, a channel twin (CT) is constructed using a high-fidelity ray-tracing solver with geo-spatial contexts, and network information to capture SS propagation characteristics, and dual annealing algorithm is employed to precompute optimal transmission beam directions. In the second stage, a Multi-Head Proximal Policy Optimization (MH-PPO) agent, equipped with a scalable multi-head actor-critic architecture, is trained on the DT-generated channel dataset to directly map complex channel and beam states to jointly execute UAV-BS-beam association decisions. The proposed PPO agent achieves a 44%-121% improvement over DQN and 249%-807% gain over traditional heuristic based optimization schemes in a dense UAV scenario, while reducing inference latency by several orders of magnitude. These results demonstrate that DT-driven training pipelines can deliver high-performance, low-latency RRM policies tailored to SS deployments suitable for real-time resource management in next-generation aerial corridor networks.
KANGURA: Kolmogorov-Arnold Network-Based Geometry-Aware Learning with Unified Representation Attention for 3D Modeling of Complex Structures
Nov 17, 2025Microbial Fuel Cells (MFCs) offer a promising pathway for sustainable energy generation by converting organic matter into electricity through microbial processes. A key factor influencing MFC performance is the anode structure, where design and material properties play a crucial role. Existing predictive models struggle to capture the complex geometric dependencies necessary to optimize these structures. To solve this problem, we propose KANGURA: Kolmogorov-Arnold Network-Based Geometry-Aware Learning with Unified Representation Attention. KANGURA introduces a new approach to three-dimensional (3D) machine learning modeling. It formulates prediction as a function decomposition problem, where Kolmogorov-Arnold Network (KAN)- based representation learning reconstructs geometric relationships without a conventional multi- layer perceptron (MLP). To refine spatial understanding, geometry-disentangled representation learning separates structural variations into interpretable components, while unified attention mechanisms dynamically enhance critical geometric regions. Experimental results demonstrate that KANGURA outperforms over 15 state-of-the-art (SOTA) models on the ModelNet40 benchmark dataset, achieving 92.7% accuracy, and excels in a real-world MFC anode structure problem with 97% accuracy. This establishes KANGURA as a robust framework for 3D geometric modeling, unlocking new possibilities for optimizing complex structures in advanced manufacturing and quality-driven engineering applications.
Towards Efficient Real-Time Video Motion Transfer via Generative Time Series Modeling
Apr 07, 2025We propose a deep learning framework designed to significantly optimize bandwidth for motion-transfer-enabled video applications, including video conferencing, virtual reality interactions, health monitoring systems, and vision-based real-time anomaly detection. To capture complex motion effectively, we utilize the First Order Motion Model (FOMM), which encodes dynamic objects by detecting keypoints and their associated local affine transformations. These keypoints are identified using a self-supervised keypoint detector and arranged into a time series corresponding to the successive frames. Forecasting is performed on these keypoints by integrating two advanced generative time series models into the motion transfer pipeline, namely the Variational Recurrent Neural Network (VRNN) and the Gated Recurrent Unit with Normalizing Flow (GRU-NF). The predicted keypoints are subsequently synthesized into realistic video frames using an optical flow estimator paired with a generator network, thereby facilitating accurate video forecasting and enabling efficient, low-frame-rate video transmission. We validate our results across three datasets for video animation and reconstruction using the following metrics: Mean Absolute Error, Joint Embedding Predictive Architecture Embedding Distance, Structural Similarity Index, and Average Pair-wise Displacement. Our results confirm that by utilizing the superior reconstruction property of the Variational Autoencoder, the VRNN integrated FOMM excels in applications involving multi-step ahead forecasts such as video conferencing. On the other hand, by leveraging the Normalizing Flow architecture for exact likelihood estimation, and enabling efficient latent space sampling, the GRU-NF based FOMM exhibits superior capabilities for producing diverse future samples while maintaining high visual quality for tasks like real-time video-based anomaly detection.
From Automation to Autonomy in Smart Manufacturing: A Bayesian Optimization Framework for Modeling Multi-Objective Experimentation and Sequential Decision Making
Apr 05, 2025Discovering novel materials with desired properties is essential for driving innovation. Industry 4.0 and smart manufacturing have promised transformative advances in this area through real-time data integration and automated production planning and control. However, the reliance on automation alone has often fallen short, lacking the flexibility needed for complex processes. To fully unlock the potential of smart manufacturing, we must evolve from automation to autonomous systems that go beyond rigid programming and can dynamically optimize the search for solutions. Current discovery approaches are often slow, requiring numerous trials to find optimal combinations, and costly, particularly when optimizing multiple properties simultaneously. This paper proposes a Bayesian multi-objective sequential decision-making (BMSDM) framework that can intelligently select experiments as manufacturing progresses, guiding us toward the discovery of optimal design faster and more efficiently. The framework leverages sequential learning through Bayesian Optimization, which iteratively refines a statistical model representing the underlying manufacturing process. This statistical model acts as a surrogate, allowing for efficient exploration and optimization without requiring numerous real-world experiments. This approach can significantly reduce the time and cost of data collection required by traditional experimental designs. The proposed framework is compared with traditional DoE methods and two other multi-objective optimization methods. Using a manufacturing dataset, we evaluate and compare the performance of these approaches across five evaluation metrics. BMSDM comprehensively outperforms the competing methods in multi-objective decision-making scenarios. Our proposed approach represents a significant leap forward in creating an intelligent autonomous platform capable of novel material discovery.
Confidence Adjusted Surprise Measure for Active Resourceful Trials (CA-SMART): A Data-driven Active Learning Framework for Accelerating Material Discovery under Resource Constraints
Mar 27, 2025Accelerating the discovery and manufacturing of advanced materials with specific properties is a critical yet formidable challenge due to vast search space, high costs of experiments, and time-intensive nature of material characterization. In recent years, active learning, where a surrogate machine learning (ML) model mimics the scientific discovery process of a human scientist, has emerged as a promising approach to address these challenges by guiding experimentation toward high-value outcomes with a limited budget. Among the diverse active learning philosophies, the concept of surprise (capturing the divergence between expected and observed outcomes) has demonstrated significant potential to drive experimental trials and refine predictive models. Scientific discovery often stems from surprise thereby making it a natural driver to guide the search process. Despite its promise, prior studies leveraging surprise metrics such as Shannon and Bayesian surprise lack mechanisms to account for prior confidence, leading to excessive exploration of uncertain regions that may not yield useful information. To address this, we propose the Confidence-Adjusted Surprise Measure for Active Resourceful Trials (CA-SMART), a novel Bayesian active learning framework tailored for optimizing data-driven experimentation. On a high level, CA-SMART incorporates Confidence-Adjusted Surprise (CAS) to dynamically balance exploration and exploitation by amplifying surprises in regions where the model is more certain while discounting them in highly uncertain areas. We evaluated CA-SMART on two benchmark functions (Six-Hump Camelback and Griewank) and in predicting the fatigue strength of steel. The results demonstrate superior accuracy and efficiency compared to traditional surprise metrics, standard Bayesian Optimization (BO) acquisition functions and conventional ML methods.
Digital Twin Enabled Site Specific Channel Precoding: Over the Air CIR Inference
Jan 27, 2025This paper investigates the significance of designing a reliable, intelligent, and true physical environment-aware precoding scheme by leveraging an accurately designed channel twin model to obtain realistic channel state information (CSI) for cellular communication systems. Specifically, we propose a fine-tuned multi-step channel twin design process that can render CSI very close to the CSI of the actual environment. After generating a precise CSI, we execute precoding using the obtained CSI at the transmitter end. We demonstrate a two-step parameters' tuning approach to design channel twin by ray tracing (RT) emulation, then further fine-tuning of CSI by employing an artificial intelligence (AI) based algorithm can significantly reduce the gap between actual CSI and the fine-tuned digital twin (DT) rendered CSI. The simulation results show the effectiveness of the proposed novel approach in designing a true physical environment-aware channel twin model.
In-Situ Melt Pool Characterization via Thermal Imaging for Defect Detection in Directed Energy Deposition Using Vision Transformers
Nov 18, 2024


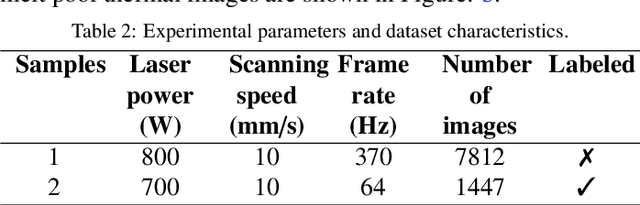
Directed Energy Deposition (DED) offers significant potential for manufacturing complex and multi-material parts. However, internal defects such as porosity and cracks can compromise mechanical properties and overall performance. This study focuses on in-situ monitoring and characterization of melt pools associated with porosity, aiming to improve defect detection and quality control in DED-printed parts. Traditional machine learning approaches for defect identification rely on extensive labeled datasets, often scarce and expensive to generate in real-world manufacturing. To address this, our framework employs self-supervised learning on unlabeled melt pool data using a Vision Transformer-based Masked Autoencoder (MAE) to produce highly representative embeddings. These fine-tuned embeddings are leveraged via transfer learning to train classifiers on a limited labeled dataset, enabling the effective identification of melt pool anomalies. We evaluate two classifiers: (1) a Vision Transformer (ViT) classifier utilizing the fine-tuned MAE Encoder's parameters and (2) the fine-tuned MAE Encoder combined with an MLP classifier head. Our framework achieves overall accuracy ranging from 95.44% to 99.17% and an average F1 score exceeding 80%, with the ViT Classifier slightly outperforming the MAE Encoder Classifier. This demonstrates the scalability and cost-effectiveness of our approach for automated quality control in DED, effectively detecting defects with minimal labeled data.
A Data-Efficient Sequential Learning Framework for Melt Pool Defect Classification in Laser Powder Bed Fusion
Nov 16, 2024Ensuring the quality and reliability of Metal Additive Manufacturing (MAM) components is crucial, especially in the Laser Powder Bed Fusion (L-PBF) process, where melt pool defects such as keyhole, balling, and lack of fusion can significantly compromise structural integrity. This study presents SL-RF+ (Sequentially Learned Random Forest with Enhanced Sampling), a novel Sequential Learning (SL) framework for melt pool defect classification designed to maximize data efficiency and model accuracy in data-scarce environments. SL-RF+ utilizes RF classifier combined with Least Confidence Sampling (LCS) and Sobol sequence-based synthetic sampling to iteratively select the most informative samples to learn from, thereby refining the model's decision boundaries with minimal labeled data. Results show that SL-RF+ outperformed traditional machine learning models across key performance metrics, including accuracy, precision, recall, and F1 score, demonstrating significant robustness in identifying melt pool defects with limited data. This framework efficiently captures complex defect patterns by focusing on high-uncertainty regions in the process parameter space, ultimately achieving superior classification performance without the need for extensive labeled datasets. While this study utilizes pre-existing experimental data, SL-RF+ shows strong potential for real-world applications in pure sequential learning settings, where data is acquired and labeled incrementally, mitigating the high costs and time constraints of sample acquisition.
Advancing Healthcare: Innovative ML Approaches for Improved Medical Imaging in Data-Constrained Environments
Oct 16, 2024



Healthcare industries face challenges when experiencing rare diseases due to limited samples. Artificial Intelligence (AI) communities overcome this situation to create synthetic data which is an ethical and privacy issue in the medical domain. This research introduces the CAT-U-Net framework as a new approach to overcome these limitations, which enhances feature extraction from medical images without the need for large datasets. The proposed framework adds an extra concatenation layer with downsampling parts, thereby improving its ability to learn from limited data while maintaining patient privacy. To validate, the proposed framework's robustness, different medical conditioning datasets were utilized including COVID-19, brain tumors, and wrist fractures. The framework achieved nearly 98% reconstruction accuracy, with a Dice coefficient close to 0.946. The proposed CAT-U-Net has the potential to make a big difference in medical image diagnostics in settings with limited data.
Deep Learning Model-Based Channel Estimation for THz Band Massive MIMO with RF Impairments
Sep 24, 2024THz band enabled large scale massive MIMO (M-MIMO) is considered as a key enabler for the 6G technology, given its enormous bandwidth and for its low latency connectivity. In the large-scale M-MIMO configuration, enlarged array aperture and small wavelengths of THz results in an amalgamation of both far field and near field paths, which makes tasks such as channel estimation for THz M-MIMO highly challenging. Moreover, at the THz transceiver, radio frequency (RF) impairments such as phase noise (PN) of the analog devices also leads to degradation in channel estimation performance. Classical estimators as well as traditional deep learning (DL) based algorithms struggle to maintain their robustness when performing for large scale antenna arrays i.e., M-MIMO, and when RF impairments are considered for practical usage. To effectively address this issue, it is crucial to utilize a neural network (NN) that has the ability to study the behaviors of the channel and RF impairment correlations, such as a recurrent neural network (RNN). The RF impairments act as sequential noise data which is subsequently incorporated with the channel data, leading to choose a specific type of RNN known as bidirectional long short-term memory (BiLSTM) which is followed by gated recurrent units (GRU) to process the sequential data. Simulation results demonstrate that our proposed model outperforms other benchmark approaches at various signal-to-noise ratio (SNR) levels.