 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Situ Melt Pool Characterization via Thermal Imaging for Defect Detection in Directed Energy Deposition Using Vision Transformers
Nov 18, 2024


Directed Energy Deposition (DED) offers significant potential for manufacturing complex and multi-material parts. However, internal defects such as porosity and cracks can compromise mechanical properties and overall performance. This study focuses on in-situ monitoring and characterization of melt pools associated with porosity, aiming to improve defect detection and quality control in DED-printed parts. Traditional machine learning approaches for defect identification rely on extensive labeled datasets, often scarce and expensive to generate in real-world manufacturing. To address this, our framework employs self-supervised learning on unlabeled melt pool data using a Vision Transformer-based Masked Autoencoder (MAE) to produce highly representative embeddings. These fine-tuned embeddings are leveraged via transfer learning to train classifiers on a limited labeled dataset, enabling the effective identification of melt pool anomalies. We evaluate two classifiers: (1) a Vision Transformer (ViT) classifier utilizing the fine-tuned MAE Encoder's parameters and (2) the fine-tuned MAE Encoder combined with an MLP classifier head. Our framework achieves overall accuracy ranging from 95.44% to 99.17% and an average F1 score exceeding 80%, with the ViT Classifier slightly outperforming the MAE Encoder Classifier. This demonstrates the scalability and cost-effectiveness of our approach for automated quality control in DED, effectively detecting defects with minimal labeled data.
A Data-Efficient Sequential Learning Framework for Melt Pool Defect Classification in Laser Powder Bed Fusion
Nov 16, 2024Ensuring the quality and reliability of Metal Additive Manufacturing (MAM) components is crucial, especially in the Laser Powder Bed Fusion (L-PBF) process, where melt pool defects such as keyhole, balling, and lack of fusion can significantly compromise structural integrity. This study presents SL-RF+ (Sequentially Learned Random Forest with Enhanced Sampling), a novel Sequential Learning (SL) framework for melt pool defect classification designed to maximize data efficiency and model accuracy in data-scarce environments. SL-RF+ utilizes RF classifier combined with Least Confidence Sampling (LCS) and Sobol sequence-based synthetic sampling to iteratively select the most informative samples to learn from, thereby refining the model's decision boundaries with minimal labeled data. Results show that SL-RF+ outperformed traditional machine learning models across key performance metrics, including accuracy, precision, recall, and F1 score, demonstrating significant robustness in identifying melt pool defects with limited data. This framework efficiently captures complex defect patterns by focusing on high-uncertainty regions in the process parameter space, ultimately achieving superior classification performance without the need for extensive labeled datasets. While this study utilizes pre-existing experimental data, SL-RF+ shows strong potential for real-world applications in pure sequential learning settings, where data is acquired and labeled incrementally, mitigating the high costs and time constraints of sample acquisition.
An unsupervised approach towards promptable defect segmentation in laser-based additive manufacturing by Segment Anything
Dec 07, 2023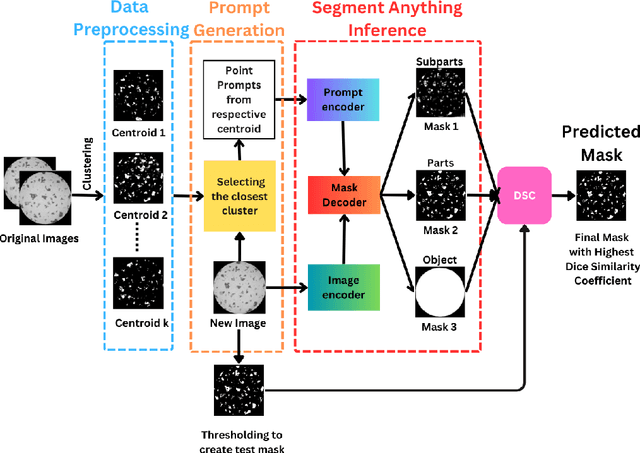
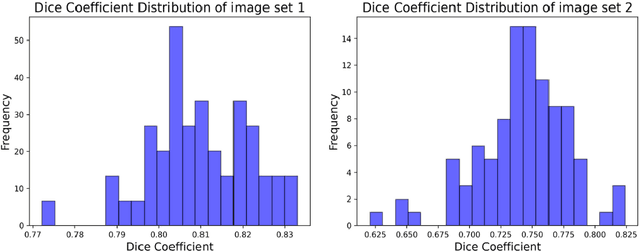

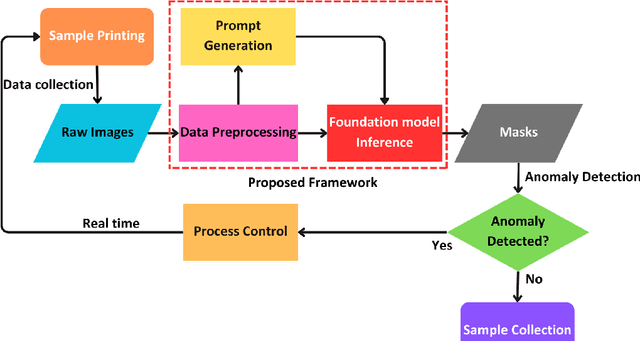
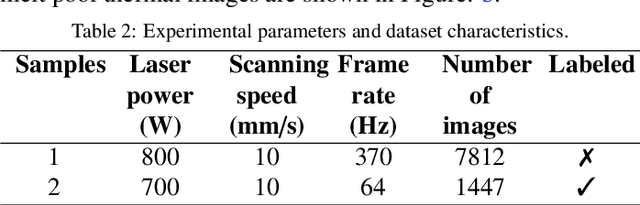
Foundation models are currently driving a paradigm shift in computer vision tasks for various fields including biology, astronomy, and robotics among others, leveraging user-generated prompts to enhance their performance. In the manufacturing domain, accurate image-based defect segmentation is imperative to ensure product quality and facilitate real-time process control. However, such tasks are often characterized by multiple challenges including the absence of labels and the requirement for low latency inference among others. To address these issues, we construct a framework for image segmentation using a state-of-the-art Vision Transformer (ViT) based Foundation model (Segment Anything Model) with a novel multi-point prompt generation scheme using unsupervised clustering. We apply our framework to perform real-time porosity segmentation in a case study of laser base powder bed fusion (L-PBF) and obtain high Dice Similarity Coefficients (DSC) without the necessity for any supervised fine-tuning in the model. Using such lightweight foundation model inference in conjunction with unsupervised prompt generation, we envision the construction of a real-time anomaly detection pipeline that has the potential to revolutionize the current laser-based additive manufacturing processes, thereby facilitating the shift towards Industry 4.0 and promoting defect-free production along with operational efficiency.