 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Transformer Based Generic Mixture Density Network for Scattering Timescale Estimation of Fast Radio Bursts
Jun 02, 2026The discovery rate of fast radio bursts (FRBs) continues to increase with the advent of new radio facilities and yet extracting their astrophysical parameters such as scattering timescale ($τ$) remains a significant bottleneck. Current $τ$ measurement approaches like fitting analytic template models and scattering aware de-convolution are accurate but slow, sensitive to initialization, limited by low signal to noise and often require manual supervision. These limitations inspired us to explore fast, robust and scalable machine learning methods to estimate the astrophysical parameter value. We present a deep learning approach named Multimodal Transformer Based Generic Mixture Density Network (MT-GMDN) which ingests FRB dynamic spectrum and its corresponding timeseries profile through parallel transformer encoders, fuses their latent representations and predicts the distribution of $τ$ with probabilistic output derived from generic mixture-density formulation. This formulation not only estimates the value of $τ$ but also captures the (zero inflated) nature of FRB populations where a significant fraction of bursts exhibit unresolvable scattering. We trained MT-GMDN on $\sim3500$ FRBs from CHIME/FRB \cattwo while holding out some fraction of FRBs for validation during training and for testing after the training completes. The model achieves a coefficient of determination ($R^2$) value of $94\%$ on the expected value of $τ$ for the events with measurable scattering with an excellent recall value of $90\%$ on the test data set. The model was also able to incorporate heteroskedastic errors enabling us the construction of a confidence interval for the predictions.
GIF: Generative Inspiration for Face Recognition at Scale
May 05, 2025

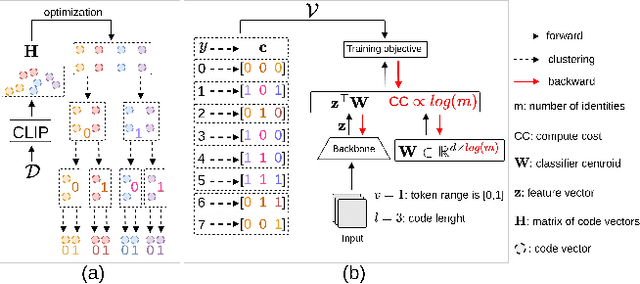
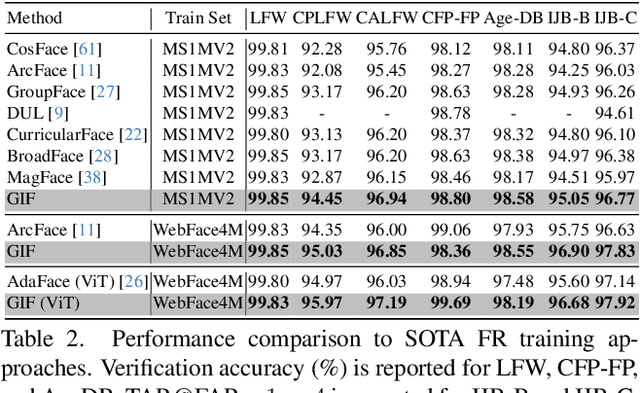
Aiming to reduce the computational cost of Softmax in massive label space of Face Recognition (FR) benchmarks, recent studies estimate the output using a subset of identities. Although promising, the association between the computation cost and the number of identities in the dataset remains linear only with a reduced ratio. A shared characteristic among available FR methods is the employment of atomic scalar labels during training. Consequently, the input to label matching is through a dot product between the feature vector of the input and the Softmax centroids. Inspired by generative modeling, we present a simple yet effective method that substitutes scalar labels with structured identity code, i.e., a sequence of integers. Specifically, we propose a tokenization scheme that transforms atomic scalar labels into structured identity codes. Then, we train an FR backbone to predict the code for each input instead of its scalar label. As a result, the associated computational cost becomes logarithmic w.r.t. number of identities. We demonstrate the benefits of the proposed method by conducting experiments. In particular, our method outperforms its competitors by 1.52%, and 0.6% at TAR@FAR$=1e-4$ on IJB-B and IJB-C, respectively, while transforming the association between computational cost and the number of identities from linear to logarithmic. See code at https://github.com/msed-Ebrahimi/GIF
Towards Efficient Real-Time Video Motion Transfer via Generative Time Series Modeling
Apr 07, 2025We propose a deep learning framework designed to significantly optimize bandwidth for motion-transfer-enabled video applications, including video conferencing, virtual reality interactions, health monitoring systems, and vision-based real-time anomaly detection. To capture complex motion effectively, we utilize the First Order Motion Model (FOMM), which encodes dynamic objects by detecting keypoints and their associated local affine transformations. These keypoints are identified using a self-supervised keypoint detector and arranged into a time series corresponding to the successive frames. Forecasting is performed on these keypoints by integrating two advanced generative time series models into the motion transfer pipeline, namely the Variational Recurrent Neural Network (VRNN) and the Gated Recurrent Unit with Normalizing Flow (GRU-NF). The predicted keypoints are subsequently synthesized into realistic video frames using an optical flow estimator paired with a generator network, thereby facilitating accurate video forecasting and enabling efficient, low-frame-rate video transmission. We validate our results across three datasets for video animation and reconstruction using the following metrics: Mean Absolute Error, Joint Embedding Predictive Architecture Embedding Distance, Structural Similarity Index, and Average Pair-wise Displacement. Our results confirm that by utilizing the superior reconstruction property of the Variational Autoencoder, the VRNN integrated FOMM excels in applications involving multi-step ahead forecasts such as video conferencing. On the other hand, by leveraging the Normalizing Flow architecture for exact likelihood estimation, and enabling efficient latent space sampling, the GRU-NF based FOMM exhibits superior capabilities for producing diverse future samples while maintaining high visual quality for tasks like real-time video-based anomaly detection.
In-Situ Melt Pool Characterization via Thermal Imaging for Defect Detection in Directed Energy Deposition Using Vision Transformers
Nov 18, 2024


Directed Energy Deposition (DED) offers significant potential for manufacturing complex and multi-material parts. However, internal defects such as porosity and cracks can compromise mechanical properties and overall performance. This study focuses on in-situ monitoring and characterization of melt pools associated with porosity, aiming to improve defect detection and quality control in DED-printed parts. Traditional machine learning approaches for defect identification rely on extensive labeled datasets, often scarce and expensive to generate in real-world manufacturing. To address this, our framework employs self-supervised learning on unlabeled melt pool data using a Vision Transformer-based Masked Autoencoder (MAE) to produce highly representative embeddings. These fine-tuned embeddings are leveraged via transfer learning to train classifiers on a limited labeled dataset, enabling the effective identification of melt pool anomalies. We evaluate two classifiers: (1) a Vision Transformer (ViT) classifier utilizing the fine-tuned MAE Encoder's parameters and (2) the fine-tuned MAE Encoder combined with an MLP classifier head. Our framework achieves overall accuracy ranging from 95.44% to 99.17% and an average F1 score exceeding 80%, with the ViT Classifier slightly outperforming the MAE Encoder Classifier. This demonstrates the scalability and cost-effectiveness of our approach for automated quality control in DED, effectively detecting defects with minimal labeled data.
A Data-Efficient Sequential Learning Framework for Melt Pool Defect Classification in Laser Powder Bed Fusion
Nov 16, 2024Ensuring the quality and reliability of Metal Additive Manufacturing (MAM) components is crucial, especially in the Laser Powder Bed Fusion (L-PBF) process, where melt pool defects such as keyhole, balling, and lack of fusion can significantly compromise structural integrity. This study presents SL-RF+ (Sequentially Learned Random Forest with Enhanced Sampling), a novel Sequential Learning (SL) framework for melt pool defect classification designed to maximize data efficiency and model accuracy in data-scarce environments. SL-RF+ utilizes RF classifier combined with Least Confidence Sampling (LCS) and Sobol sequence-based synthetic sampling to iteratively select the most informative samples to learn from, thereby refining the model's decision boundaries with minimal labeled data. Results show that SL-RF+ outperformed traditional machine learning models across key performance metrics, including accuracy, precision, recall, and F1 score, demonstrating significant robustness in identifying melt pool defects with limited data. This framework efficiently captures complex defect patterns by focusing on high-uncertainty regions in the process parameter space, ultimately achieving superior classification performance without the need for extensive labeled datasets. While this study utilizes pre-existing experimental data, SL-RF+ shows strong potential for real-world applications in pure sequential learning settings, where data is acquired and labeled incrementally, mitigating the high costs and time constraints of sample acquisition.
Enhancing Bandwidth Efficiency for Video Motion Transfer Applications using Deep Learning Based Keypoint Prediction
Mar 17, 2024We propose a deep learning based novel prediction framework for enhanced bandwidth reduction in motion transfer enabled video applications such as video conferencing, virtual reality gaming and privacy preservation for patient health monitoring. To model complex motion, we use the First Order Motion Model (FOMM) that represents dynamic objects using learned keypoints along with their local affine transformations. Keypoints are extracted by a self-supervised keypoint detector and organized in a time series corresponding to the video frames. Prediction of keypoints, to enable transmission using lower frames per second on the source device, is performed using a Variational Recurrent Neural Network (VRNN). The predicted keypoints are then synthesized to video frames using an optical flow estimator and a generator network. This efficacy of leveraging keypoint based representations in conjunction with VRNN based prediction for both video animation and reconstruction is demonstrated on three diverse datasets. For real-time applications, our results show the effectiveness of our proposed architecture by enabling up to 2x additional bandwidth reduction over existing keypoint based video motion transfer frameworks without significantly compromising video quality.
Binary Gaussian Copula Synthesis: A Novel Data Augmentation Technique to Advance ML-based Clinical Decision Support Systems for Early Prediction of Dialysis Among CKD Patients
Mar 01, 2024



The Center for Disease Control estimates that over 37 million US adults suffer from chronic kidney disease (CKD), yet 9 out of 10 of these individuals are unaware of their condition due to the absence of symptoms in the early stages. It has a significant impact on patients' quality of life, particularly when it progresses to the need for dialysis. Early prediction of dialysis is crucial as it can significantly improve patient outcomes and assist healthcare providers in making timely and informed decisions. However, developing an effective machine learning (ML)-based Clinical Decision Support System (CDSS) for early dialysis prediction poses a key challenge due to the imbalanced nature of data. To address this challenge, this study evaluates various data augmentation techniques to understand their effectiveness on real-world datasets. We propose a new approach named Binary Gaussian Copula Synthesis (BGCS). BGCS is tailored for binary medical datasets and excels in generating synthetic minority data that mirrors the distribution of the original data. BGCS enhances early dialysis prediction by outperforming traditional methods in detecting dialysis patients. For the best ML model, Random Forest, BCGS achieved a 72% improvement, surpassing the state-of-the-art augmentation approaches. Also, we present a ML-based CDSS, designed to aid clinicians in making informed decisions. CDSS, which utilizes decision tree models, is developed to improve patient outcomes, identify critical variables, and thereby enable clinicians to make proactive decisions, and strategize treatment plans effectively for CKD patients who are more likely to require dialysis in the near future. Through comprehensive feature analysis and meticulous data preparation, we ensure that the CDSS's dialysis predictions are not only accurate but also actionable, providing a valuable tool in the management and treatment of CKD.
An unsupervised approach towards promptable defect segmentation in laser-based additive manufacturing by Segment Anything
Dec 07, 2023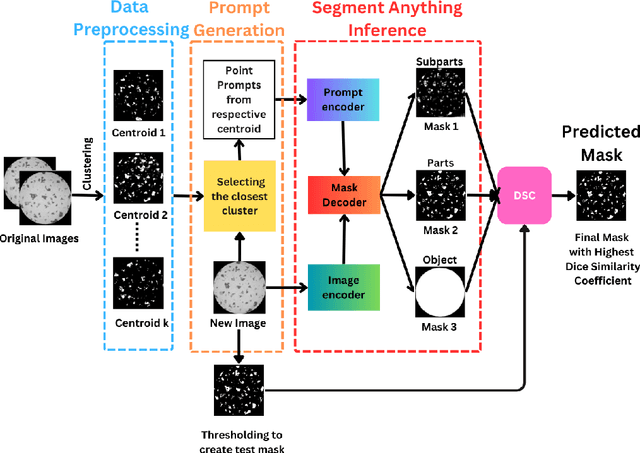
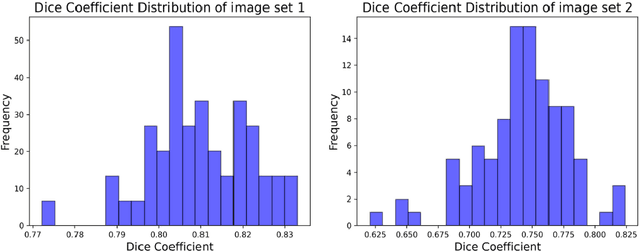

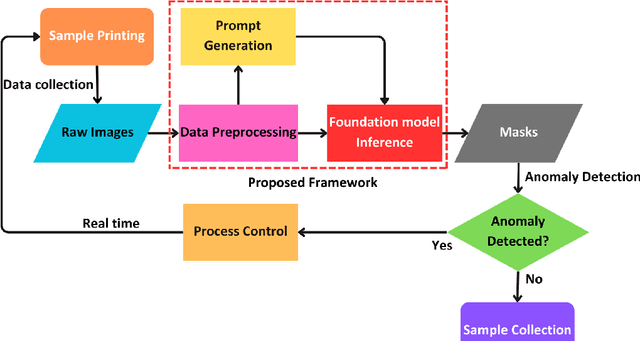
Foundation models are currently driving a paradigm shift in computer vision tasks for various fields including biology, astronomy, and robotics among others, leveraging user-generated prompts to enhance their performance. In the manufacturing domain, accurate image-based defect segmentation is imperative to ensure product quality and facilitate real-time process control. However, such tasks are often characterized by multiple challenges including the absence of labels and the requirement for low latency inference among others. To address these issues, we construct a framework for image segmentation using a state-of-the-art Vision Transformer (ViT) based Foundation model (Segment Anything Model) with a novel multi-point prompt generation scheme using unsupervised clustering. We apply our framework to perform real-time porosity segmentation in a case study of laser base powder bed fusion (L-PBF) and obtain high Dice Similarity Coefficients (DSC) without the necessity for any supervised fine-tuning in the model. Using such lightweight foundation model inference in conjunction with unsupervised prompt generation, we envision the construction of a real-time anomaly detection pipeline that has the potential to revolutionize the current laser-based additive manufacturing processes, thereby facilitating the shift towards Industry 4.0 and promoting defect-free production along with operational efficiency.
Accelerating material discovery with a threshold-driven hybrid acquisition policy-based Bayesian optimization
Nov 16, 2023



Advancements in materials play a crucial role in technological progress. However, the process of discovering and developing materials with desired properties is often impeded by substantial experimental costs, extensive resource utilization, and lengthy development periods. To address these challenges, modern approaches often employ machine learning (ML) techniques such as Bayesian Optimization (BO), which streamline the search for optimal materials by iteratively selecting experiments that are most likely to yield beneficial results. However, traditional BO methods, while beneficial, often struggle with balancing the trade-off between exploration and exploitation, leading to sub-optimal performance in material discovery processes. This paper introduces a novel Threshold-Driven UCB-EI Bayesian Optimization (TDUE-BO) method, which dynamically integrates the strengths of Upper Confidence Bound (UCB) and Expected Improvement (EI) acquisition functions to optimize the material discovery process. Unlike the classical BO, our method focuses on efficiently navigating the high-dimensional material design space (MDS). TDUE-BO begins with an exploration-focused UCB approach, ensuring a comprehensive initial sweep of the MDS. As the model gains confidence, indicated by reduced uncertainty, it transitions to the more exploitative EI method, focusing on promising areas identified earlier. The UCB-to-EI switching policy dictated guided through continuous monitoring of the model uncertainty during each step of sequential sampling results in navigating through the MDS more efficiently while ensuring rapid convergence. The effectiveness of TDUE-BO is demonstrated through its application on three different material datasets, showing significantly better approximation and optimization performance over the EI and UCB-based BO methods in terms of the RMSE scores and convergence efficiency, respectively.
Strategic Data Augmentation with CTGAN for Smart Manufacturing: Enhancing Machine Learning Predictions of Paper Breaks in Pulp-and-Paper Production
Nov 15, 2023



A significant challenge for predictive maintenance in the pulp-and-paper industry is the infrequency of paper breaks during the production process. In this article, operational data is analyzed from a paper manufacturing machine in which paper breaks are relatively rare but have a high economic impact. Utilizing a dataset comprising 18,398 instances derived from a quality assurance protocol, we address the scarcity of break events (124 cases) that pose a challenge for machine learning predictive models. With the help of Conditional Generative Adversarial Networks (CTGAN) and Synthetic Minority Oversampling Technique (SMOTE), we implement a novel data augmentation framework. This method ensures that the synthetic data mirrors the distribution of the real operational data but also seeks to enhance the performance metrics of predictive modeling. Before and after the data augmentation, we evaluate three different machine learning algorithms-Decision Trees (DT), Random Forest (RF), and Logistic Regression (LR). Utilizing the CTGAN-enhanced dataset, our study achieved significant improvements in predictive maintenance performance metrics. The efficacy of CTGAN in addressing data scarcity was evident, with the models' detection of machine breaks (Class 1) improving by over 30% for Decision Trees, 20% for Random Forest, and nearly 90% for Logistic Regression. With this methodological advancement, this study contributes to industrial quality control and maintenance scheduling by addressing rare event prediction in manufacturing processes.