 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIF: Generative Inspiration for Face Recognition at Scale
May 05, 2025

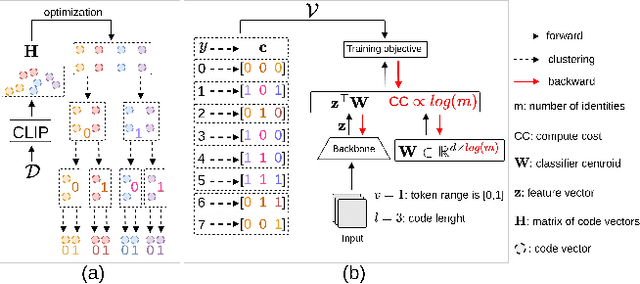
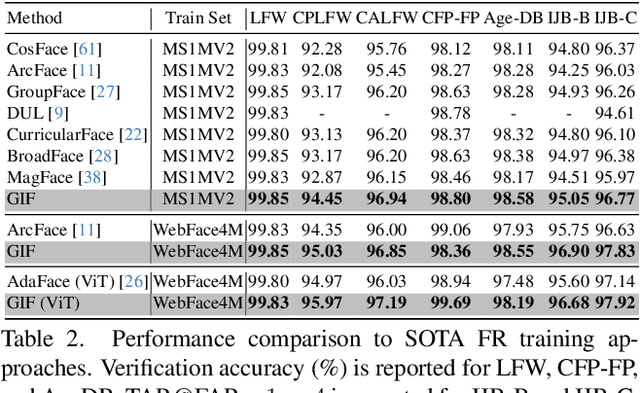
Aiming to reduce the computational cost of Softmax in massive label space of Face Recognition (FR) benchmarks, recent studies estimate the output using a subset of identities. Although promising, the association between the computation cost and the number of identities in the dataset remains linear only with a reduced ratio. A shared characteristic among available FR methods is the employment of atomic scalar labels during training. Consequently, the input to label matching is through a dot product between the feature vector of the input and the Softmax centroids. Inspired by generative modeling, we present a simple yet effective method that substitutes scalar labels with structured identity code, i.e., a sequence of integers. Specifically, we propose a tokenization scheme that transforms atomic scalar labels into structured identity codes. Then, we train an FR backbone to predict the code for each input instead of its scalar label. As a result, the associated computational cost becomes logarithmic w.r.t. number of identities. We demonstrate the benefits of the proposed method by conducting experiments. In particular, our method outperforms its competitors by 1.52%, and 0.6% at TAR@FAR$=1e-4$ on IJB-B and IJB-C, respectively, while transforming the association between computational cost and the number of identities from linear to logarithmic. See code at https://github.com/msed-Ebrahimi/GIF
FDCT: Frequency-Aware Decomposition and Cross-Modal Token-Alignment for Multi-Sensor Target Classification
Mar 12, 2025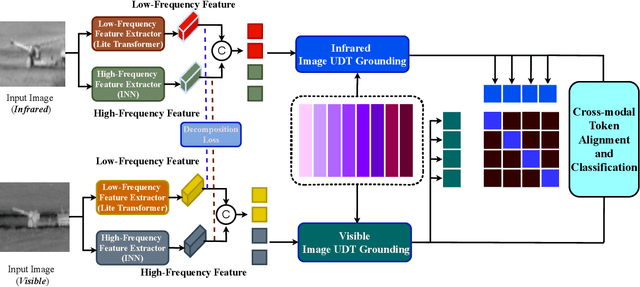
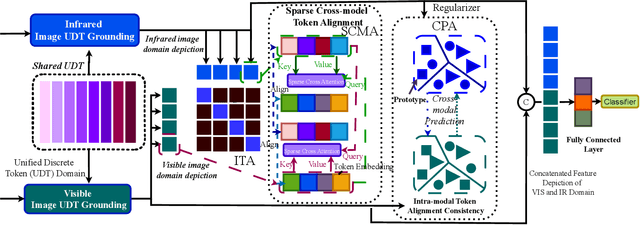
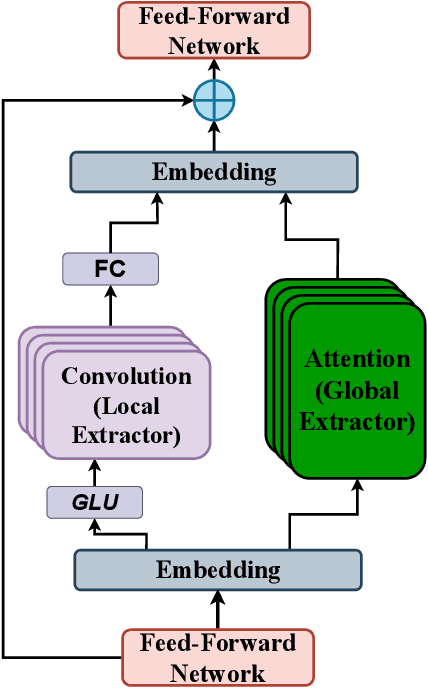
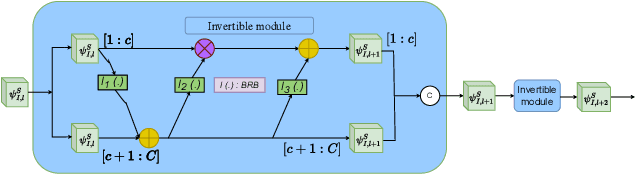
In automatic target recognition (ATR) systems, sensors may fail to capture discriminative, fine-grained detail features due to environmental conditions, noise created by CMOS chips, occlusion, parallaxes, and sensor misalignment. Therefore, multi-sensor image fusion is an effective choice to overcome these constraints. However, multi-modal image sensors are heterogeneous and have domain and granularity gaps. In addition, the multi-sensor images can be misaligned due to intricate background clutters, fluctuating illumination conditions, and uncontrolled sensor settings. In this paper, to overcome these issues, we decompose, align, and fuse multiple image sensor data for target classification. We extract the domain-specific and domain-invariant features from each sensor data. We propose to develop a shared unified discrete token (UDT) space between sensors to reduce the domain and granularity gaps. Additionally, we develop an alignment module to overcome the misalignment between multi-sensors and emphasize the discriminative representation of the UDT space. In the alignment module, we introduce sparsity constraints to provide a better cross-modal representation of the UDT space and robustness against various sensor settings. We achieve superior classification performance compared to single-modality classifiers and several state-of-the-art multi-modal fusion algorithms on four multi-sensor ATR datasets.
Decomposed Distribution Matching in Dataset Condensation
Dec 06, 2024
Dataset Condensation (DC) aims to reduce deep neural networks training efforts by synthesizing a small dataset such that it will be as effective as the original large dataset. Conventionally, DC relies on a costly bi-level optimization which prohibits its practicality. Recent research formulates DC as a distribution matching problem which circumvents the costly bi-level optimization. However, this efficiency sacrifices the DC performance. To investigate this performance degradation, we decomposed the dataset distribution into content and style. Our observations indicate two major shortcomings of: 1) style discrepancy between original and condensed data, and 2) limited intra-class diversity of condensed dataset. We present a simple yet effective method to match the style information between original and condensed data, employing statistical moments of feature maps as well-established style indicators. Moreover, we enhance the intra-class diversity by maximizing the Kullback-Leibler divergence within each synthetic class, i.e., content. We demonstrate the efficacy of our method through experiments on diverse datasets of varying size and resolution, achieving improvements of up to 4.1% on CIFAR10, 4.2% on CIFAR100, 4.3% on TinyImageNet, 2.0% on ImageNet-1K, 3.3% on ImageWoof, 2.5% on ImageNette, and 5.5% in continual learning accuracy.
Boosting Unconstrained Face Recognition with Targeted Style Adversary
Aug 14, 2024



While deep face recognition models have demonstrated remarkable performance, they often struggle on the inputs from domains beyond their training data. Recent attempts aim to expand the training set by relying on computationally expensive and inherently challenging image-space augmentation of image generation modules. In an orthogonal direction, we present a simple yet effective method to expand the training data by interpolating between instance-level feature statistics across labeled and unlabeled sets. Our method, dubbed Targeted Style Adversary (TSA), is motivated by two observations: (i) the input domain is reflected in feature statistics, and (ii) face recognition model performance is influenced by style information. Shifting towards an unlabeled style implicitly synthesizes challenging training instances. We devise a recognizability metric to constraint our framework to preserve the inherent identity-related information of labeled instances. The efficacy of our method is demonstrated through evaluations on unconstrained benchmarks, outperforming or being on par with its competitors while offering nearly a 70\% improvement in training speed and 40\% less memory consumption.
FDWST: Fingerphoto Deblurring using Wavelet Style Transfer
Jul 22, 2024
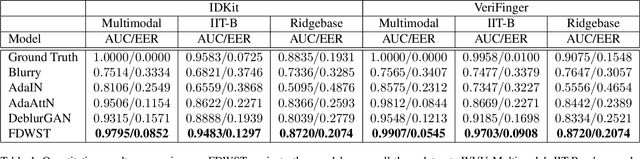
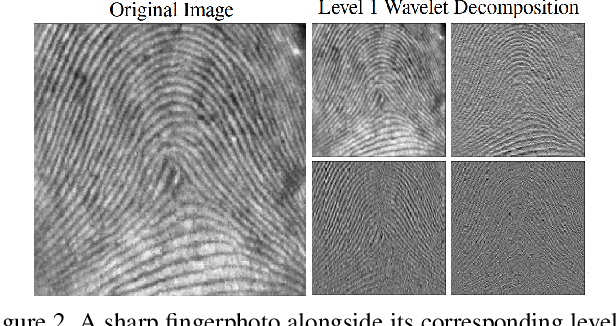
The challenge of deblurring fingerphoto images, or generating a sharp fingerphoto from a given blurry one, is a significant problem in the realm of computer vision. To address this problem, we propose a fingerphoto deblurring architecture referred to as Fingerphoto Deblurring using Wavelet Style Transfer (FDWST), which aims to utilize the information transmission of Style Transfer techniques to deblur fingerphotos. Additionally, we incorporate the Discrete Wavelet Transform (DWT) for its ability to split images into different frequency bands. By combining these two techniques, we can perform Style Transfer over a wide array of wavelet frequency bands, thereby increasing the quality and variety of sharpness information transferred from sharp to blurry images. Using this technique, our model was able to drastically increase the quality of the generated fingerphotos compared to their originals, and achieve a peak matching accuracy of 0.9907 when tasked with matching a deblurred fingerphoto to its sharp counterpart, outperforming multiple other state-of-the-art deblurring and style transfer techniques.
ARoFace: Alignment Robustness to Improve Low-Quality Face Recognition
Jul 20, 2024



Aiming to enhance Face Recognition (FR) on Low-Quality (LQ) inputs, recent studies suggest incorporating synthetic LQ samples into training. Although promising, the quality factors that are considered in these works are general rather than FR-specific, \eg, atmospheric turbulence, resolution, \etc. Motivated by the observation of the vulnerability of current FR models to even small Face Alignment Errors (FAE) in LQ images, we present a simple yet effective method that considers FAE as another quality factor that is tailored to FR. We seek to improve LQ FR by enhancing FR models' robustness to FAE. To this aim, we formalize the problem as a combination of differentiable spatial transformations and adversarial data augmentation in FR. We perturb the alignment of the training samples using a controllable spatial transformation and enrich the training with samples expressing FAE. We demonstrate the benefits of the proposed method by conducting evaluations on IJB-B, IJB-C, IJB-S (+4.3\% Rank1), and TinyFace (+2.63\%). \href{https://github.com/msed-Ebrahimi/ARoFace}{https://github.com/msed-Ebrahimi/ARoFace}
Laplacian-guided Entropy Model in Neural Codec with Blur-dissipated Synthesis
Mar 24, 2024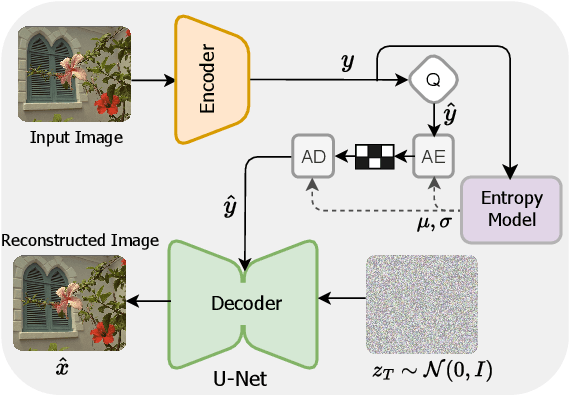

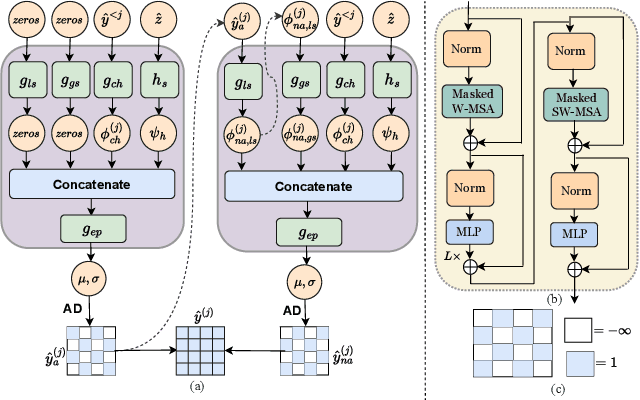
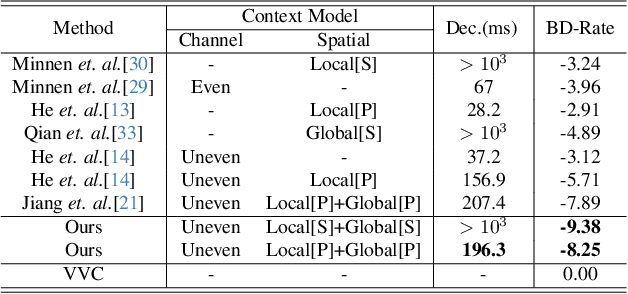
While replacing Gaussian decoders with a conditional diffusion model enhances the perceptual quality of reconstructions in neural image compression, their lack of inductive bias for image data restricts their ability to achieve state-of-the-art perceptual levels. To address this limitation, we adopt a non-isotropic diffusion model at the decoder side. This model imposes an inductive bias aimed at distinguishing between frequency contents, thereby facilitating the generation of high-quality images. Moreover, our framework is equipped with a novel entropy model that accurately models the probability distribution of latent representation by exploiting spatio-channel correlations in latent space, while accelerating the entropy decoding step. This channel-wise entropy model leverages both local and global spatial contexts within each channel chunk. The global spatial context is built upon the Transformer, which is specifically designed for image compression tasks. The designed Transformer employs a Laplacian-shaped positional encoding, the learnable parameters of which are adaptively adjusted for each channel cluster. Our experiments demonstrate that our proposed framework yields better perceptual quality compared to cutting-edge generative-based codecs, and the proposed entropy model contributes to notable bitrate savings.
Contrastive Learning and Cycle Consistency-based Transductive Transfer Learning for Target Annotation
Jan 22, 2024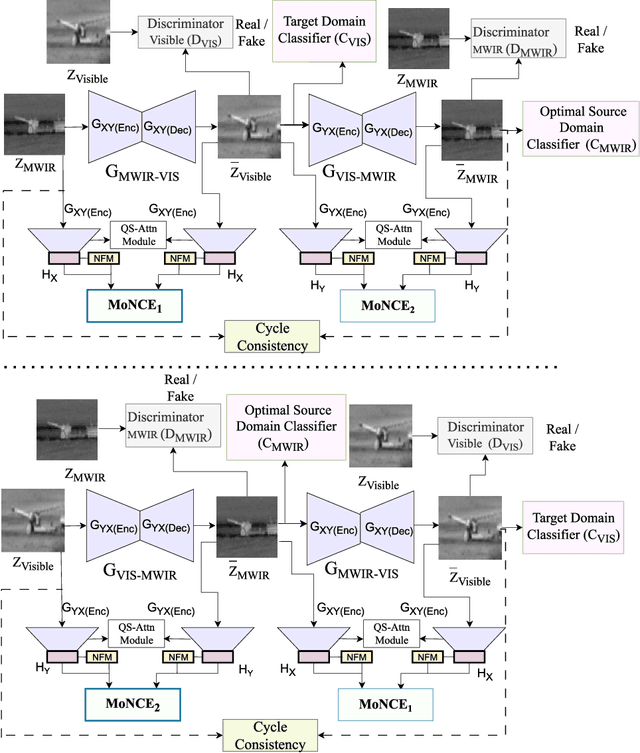
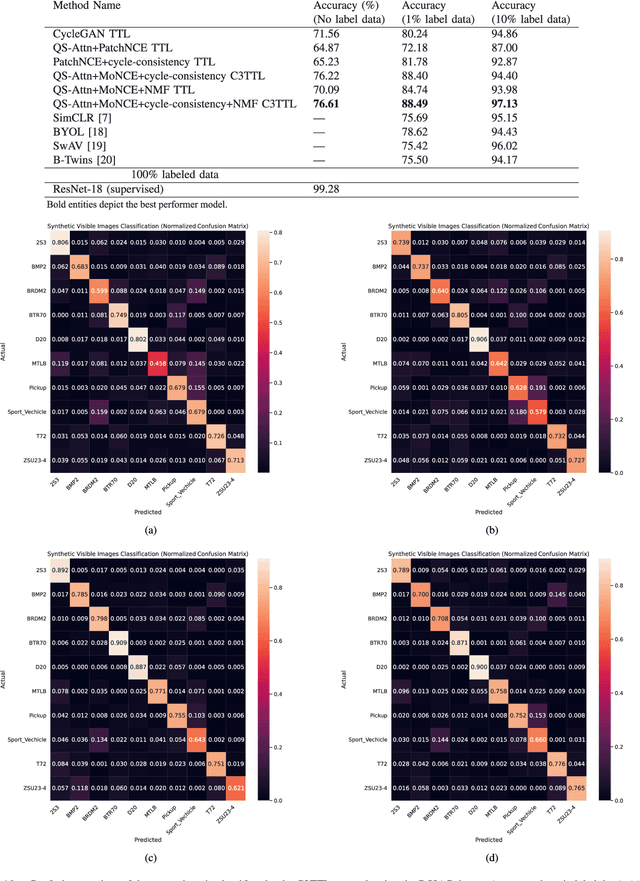
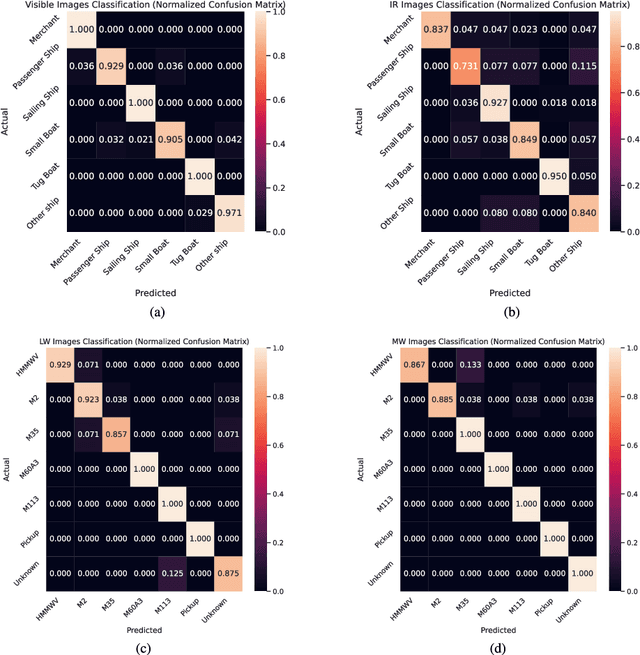
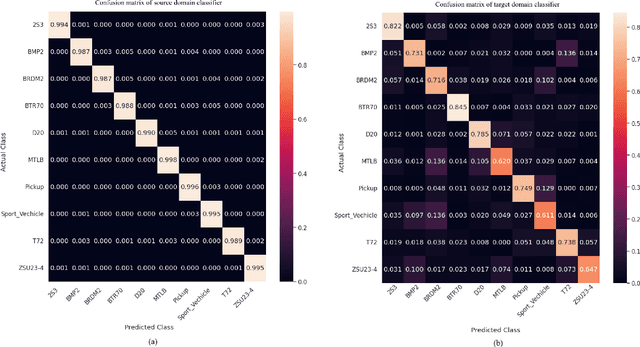
Annotating automatic target recognition (ATR) is a highly challenging task, primarily due to the unavailability of labeled data in the target domain. Hence, it is essential to construct an optimal target domain classifier by utilizing the labeled information of the source domain images. The transductive transfer learning (TTL) method that incorporates a CycleGAN-based unpaired domain translation network has been previously proposed in the literature for effective ATR annotation. Although this method demonstrates great potential for ATR, it severely suffers from lower annotation performance, higher Fr\'echet Inception Distance (FID) score, and the presence of visual artifacts in the synthetic images. To address these issues, we propose a hybrid contrastive learning base unpaired domain translation (H-CUT) network that achieves a significantly lower FID score. It incorporates both attention and entropy to emphasize the domain-specific region, a noisy feature mixup module to generate high variational synthetic negative patches, and a modulated noise contrastive estimation (MoNCE) loss to reweight all negative patches using optimal transport for better performance. Our proposed contrastive learning and cycle-consistency-based TTL (C3TTL) framework consists of two H-CUT networks and two classifiers. It simultaneously optimizes cycle-consistency, MoNCE, and identity losses. In C3TTL, two H-CUT networks have been employed through a bijection mapping to feed the reconstructed source domain images into a pretrained classifier to guide the optimal target domain classifier. Extensive experimental analysis conducted on three ATR datasets demonstrates that the proposed C3TTL method is effective in annotating civilian and military vehicles, as well as ship targets.
CATFace: Cross-Attribute-Guided Transformer with Self-Attention Distillation for Low-Quality Face Recognition
Jan 05, 2024Although face recognition (FR) has achieved great success in recent years, it is still challenging to accurately recognize faces in low-quality images due to the obscured facial details. Nevertheless, it is often feasible to make predictions about specific soft biometric (SB) attributes, such as gender, and baldness even in dealing with low-quality images. In this paper, we propose a novel multi-branch neural network that leverages SB attribute information to boost the performance of FR. To this end, we propose a cross-attribute-guided transformer fusion (CATF) module that effectively captures the long-range dependencies and relationships between FR and SB feature representations. The synergy created by the reciprocal flow of information in the dual cross-attention operations of the proposed CATF module enhances the performance of FR. Furthermore, we introduce a novel self-attention distillation framework that effectively highlights crucial facial regions, such as landmarks by aligning low-quality images with those of their high-quality counterparts in the feature space. The proposed self-attention distillation regularizes our network to learn a unified quality-invariant feature representation in unconstrained environments. We conduct extensive experiments on various FR benchmarks varying in quality. Experimental results demonstrate the superiority of our FR method compared to state-of-the-art FR studies.
Neural-based Compression Scheme for Solar Image Data
Nov 06, 2023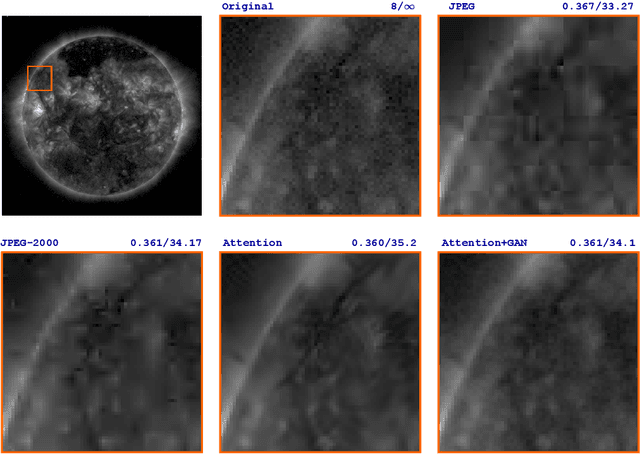
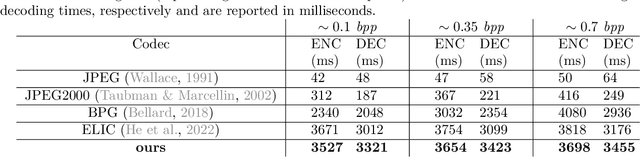
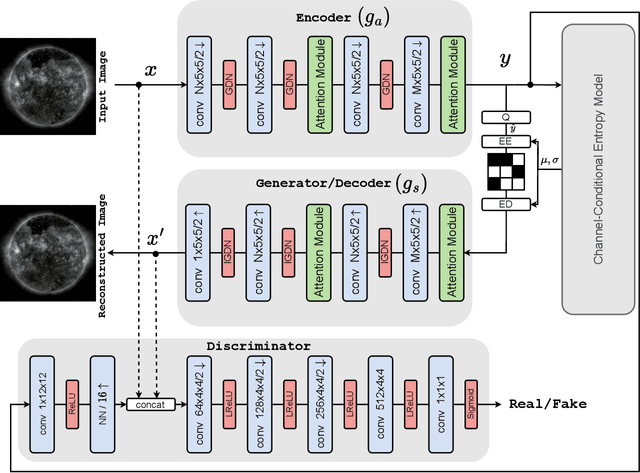
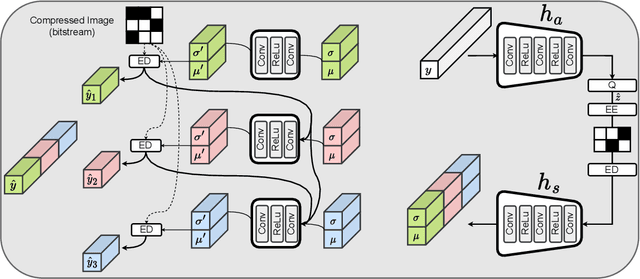
Studying the solar system and especially the Sun relies on the data gathered daily from space missions. These missions are data-intensive and compressing this data to make them efficiently transferable to the ground station is a twofold decision to make. Stronger compression methods, by distorting the data, can increase data throughput at the cost of accuracy which could affect scientific analysis of the data. On the other hand, preserving subtle details in the compressed data requires a high amount of data to be transferred, reducing the desired gains from compression. In this work, we propose a neural network-based lossy compression method to be used in NASA's data-intensive imagery missions. We chose NASA's SDO mission which transmits 1.4 terabytes of data each day as a proof of concept for the proposed algorithm. In this work, we propose an adversarially trained neural network, equipped with local and non-local attention modules to capture both the local and global structure of the image resulting in a better trade-off in rate-distortion (RD) compared to conventional hand-engineered codecs. The RD variational autoencoder used in this work is jointly trained with a channel-dependent entropy model as a shared prior between the analysis and synthesis transforms to make the entropy coding of the latent code more effective. Our neural image compression algorithm outperforms currently-in-use and state-of-the-art codecs such as JPEG and JPEG-2000 in terms of the RD performance when compressing extreme-ultraviolet (EUV) data. As a proof of concept for use of this algorithm in SDO data analysis, we have performed coronal hole (CH) detection using our compressed images, and generated consistent segmentations, even at a compression rate of $\sim0.1$ bits per pixel (compared to 8 bits per pixel on the original data) using EUV data from SDO.