 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot denoising via neural compression: Theoretical and algorithmic framework
Jun 15, 2025Zero-shot denoising aims to denoise observations without access to training samples or clean reference images. This setting is particularly relevant in practical imaging scenarios involving specialized domains such as medical imaging or biology. In this work, we propose the Zero-Shot Neural Compression Denoiser (ZS-NCD), a novel denoising framework based on neural compression. ZS-NCD treats a neural compression network as an untrained model, optimized directly on patches extracted from a single noisy image. The final reconstruction is then obtained by aggregating the outputs of the trained model over overlapping patches. Thanks to the built-in entropy constraints of compression architectures, our method naturally avoids overfitting and does not require manual regularization or early stopping. Through extensive experiments, we show that ZS-NCD achieves state-of-the-art performance among zero-shot denoisers for both Gaussian and Poisson noise, and generalizes well to both natural and non-natural images. Additionally, we provide new finite-sample theoretical results that characterize upper bounds on the achievable reconstruction error of general maximum-likelihood compression-based denoisers. These results further establish the theoretical foundations of compression-based denoising. Our code is available at: github.com/Computational-Imaging-RU/ZS-NCDenoiser.
DeCompress: Denoising via Neural Compression
Mar 27, 2025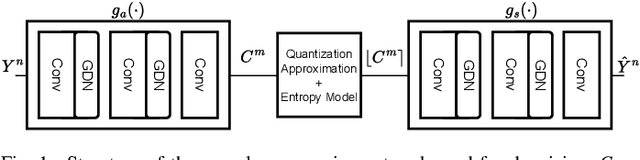



Learning-based denoising algorithms achieve state-of-the-art performance across various denoising tasks. However, training such models relies on access to large training datasets consisting of clean and noisy image pairs. On the other hand, in many imaging applications, such as microscopy, collecting ground truth images is often infeasible. To address this challenge, researchers have recently developed algorithms that can be trained without requiring access to ground truth data. However, training such models remains computationally challenging and still requires access to large noisy training samples. In this work, inspired by compression-based denoising and recent advances in neural compression, we propose a new compression-based denoising algorithm, which we name DeCompress, that i) does not require access to ground truth images, ii) does not require access to large training dataset - only a single noisy image is sufficient, iii) is robust to overfitting, and iv) achieves superior performance compared with zero-shot or unsupervised learning-based denoisers.
Bayesian Despeckling of Structured Sources
Jan 21, 2025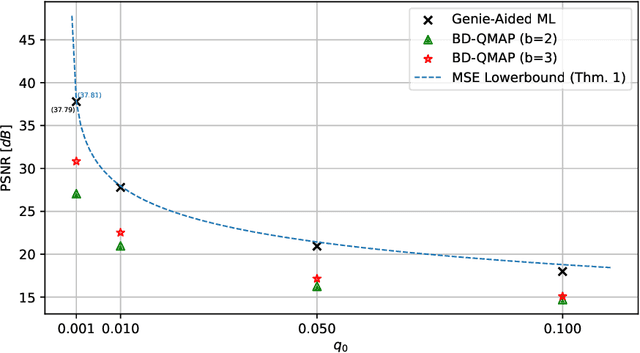
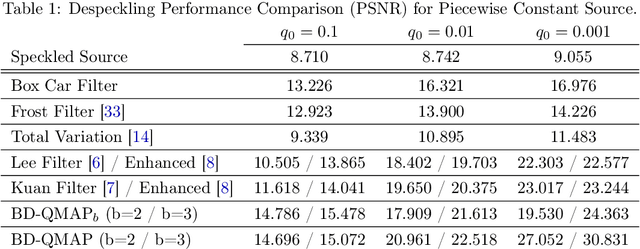
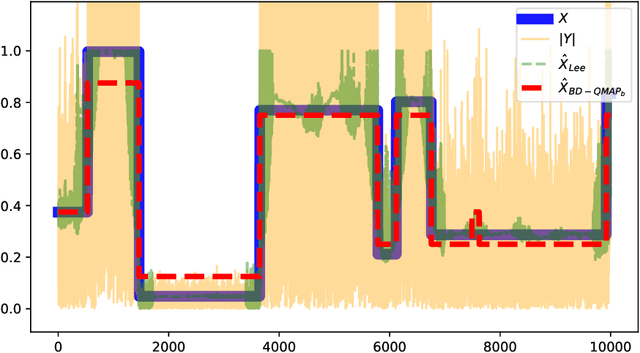
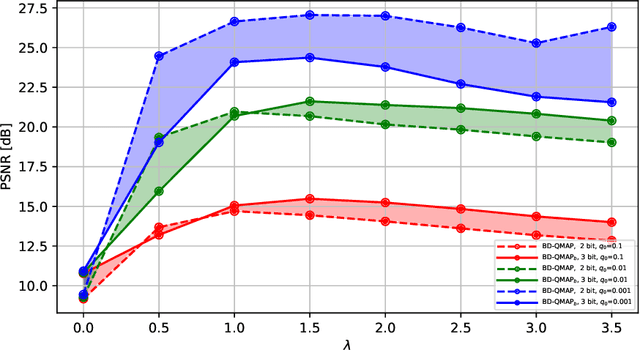
Speckle noise is a fundamental challenge in coherent imaging systems, significantly degrading image quality. Over the past decades, numerous despeckling algorithms have been developed for applications such as Synthetic Aperture Radar (SAR) and digital holography. In this paper, we aim to establish a theoretically grounded approach to despeckling. We propose a method applicable to general structured stationary stochastic sources. We demonstrate the effectiveness of the proposed method on piecewise constant sources. Additionally, we theoretically derive a lower bound on the despeckling performance for such sources. The proposed depseckler applied to the 1-Markov structured sources achieves better reconstruction performance with no strong simplification of the ground truth signal model or speckle noise.
Laplacian-guided Entropy Model in Neural Codec with Blur-dissipated Synthesis
Mar 24, 2024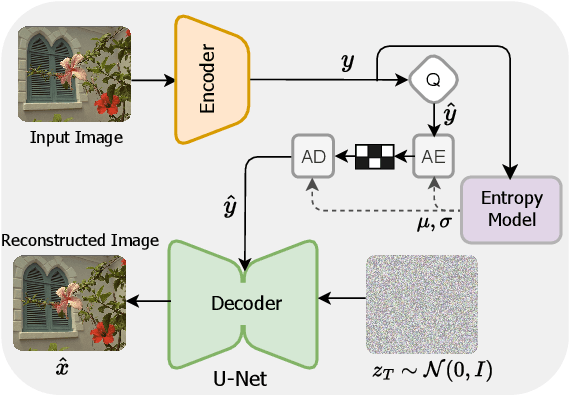

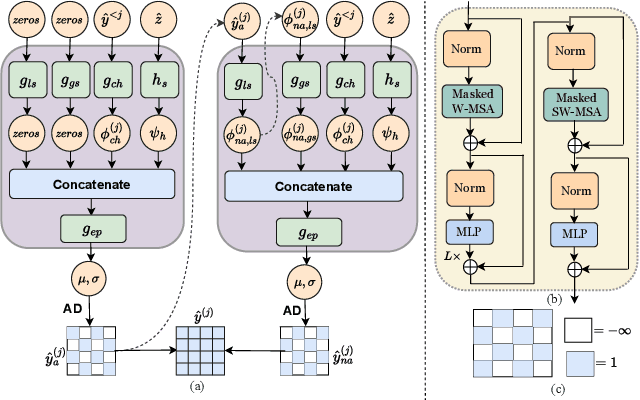
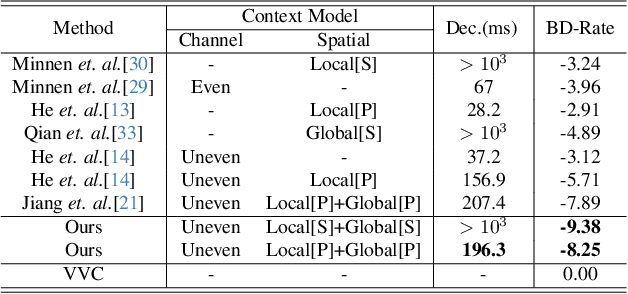
While replacing Gaussian decoders with a conditional diffusion model enhances the perceptual quality of reconstructions in neural image compression, their lack of inductive bias for image data restricts their ability to achieve state-of-the-art perceptual levels. To address this limitation, we adopt a non-isotropic diffusion model at the decoder side. This model imposes an inductive bias aimed at distinguishing between frequency contents, thereby facilitating the generation of high-quality images. Moreover, our framework is equipped with a novel entropy model that accurately models the probability distribution of latent representation by exploiting spatio-channel correlations in latent space, while accelerating the entropy decoding step. This channel-wise entropy model leverages both local and global spatial contexts within each channel chunk. The global spatial context is built upon the Transformer, which is specifically designed for image compression tasks. The designed Transformer employs a Laplacian-shaped positional encoding, the learnable parameters of which are adaptively adjusted for each channel cluster. Our experiments demonstrate that our proposed framework yields better perceptual quality compared to cutting-edge generative-based codecs, and the proposed entropy model contributes to notable bitrate savings.
Neural-based Compression Scheme for Solar Image Data
Nov 06, 2023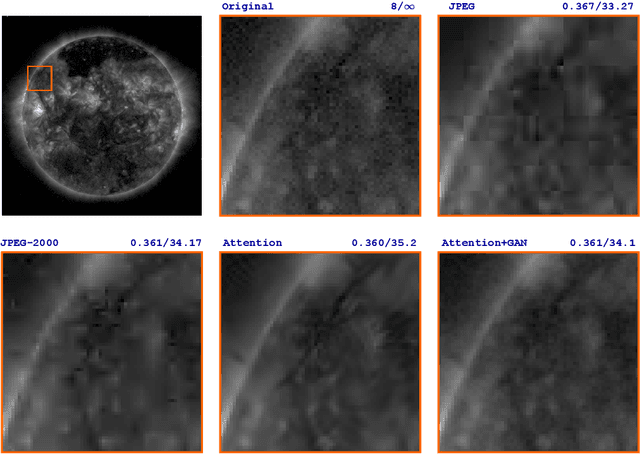
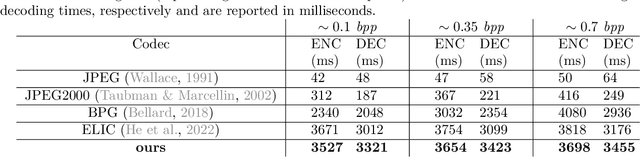
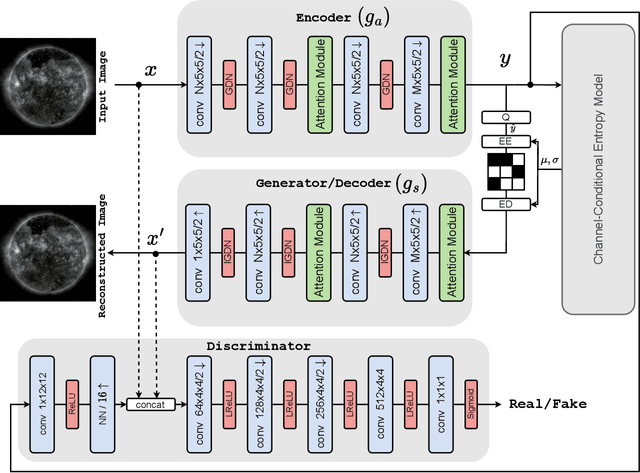
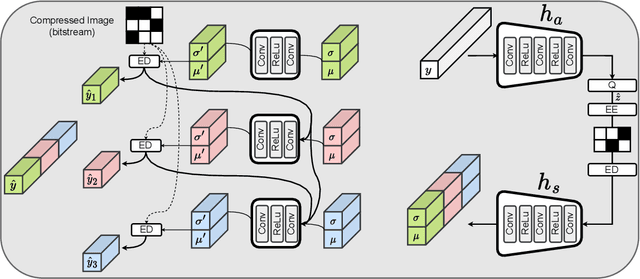
Studying the solar system and especially the Sun relies on the data gathered daily from space missions. These missions are data-intensive and compressing this data to make them efficiently transferable to the ground station is a twofold decision to make. Stronger compression methods, by distorting the data, can increase data throughput at the cost of accuracy which could affect scientific analysis of the data. On the other hand, preserving subtle details in the compressed data requires a high amount of data to be transferred, reducing the desired gains from compression. In this work, we propose a neural network-based lossy compression method to be used in NASA's data-intensive imagery missions. We chose NASA's SDO mission which transmits 1.4 terabytes of data each day as a proof of concept for the proposed algorithm. In this work, we propose an adversarially trained neural network, equipped with local and non-local attention modules to capture both the local and global structure of the image resulting in a better trade-off in rate-distortion (RD) compared to conventional hand-engineered codecs. The RD variational autoencoder used in this work is jointly trained with a channel-dependent entropy model as a shared prior between the analysis and synthesis transforms to make the entropy coding of the latent code more effective. Our neural image compression algorithm outperforms currently-in-use and state-of-the-art codecs such as JPEG and JPEG-2000 in terms of the RD performance when compressing extreme-ultraviolet (EUV) data. As a proof of concept for use of this algorithm in SDO data analysis, we have performed coronal hole (CH) detection using our compressed images, and generated consistent segmentations, even at a compression rate of $\sim0.1$ bits per pixel (compared to 8 bits per pixel on the original data) using EUV data from SDO.
Trading-off Mutual Information on Feature Aggregation for Face Recognition
Sep 22, 2023Despite the advances in the field of Face Recognition (FR), the precision of these methods is not yet sufficient. To improve the FR performance, this paper proposes a technique to aggregate the outputs of two state-of-the-art (SOTA) deep FR models, namely ArcFace and AdaFace. In our approach, we leverage the transformer attention mechanism to exploit the relationship between different parts of two feature maps. By doing so, we aim to enhance the overall discriminative power of the FR system. One of the challenges in feature aggregation is the effective modeling of both local and global dependencies. Conventional transformers are known for their ability to capture long-range dependencies, but they often struggle with modeling local dependencies accurately. To address this limitation, we augment the self-attention mechanism to capture both local and global dependencies effectively. This allows our model to take advantage of the overlapping receptive fields present in corresponding locations of the feature maps. However, fusing two feature maps from different FR models might introduce redundancies to the face embedding. Since these models often share identical backbone architectures, the resulting feature maps may contain overlapping information, which can mislead the training process. To overcome this problem, we leverage the principle of Information Bottleneck to obtain a maximally informative facial representation. This ensures that the aggregated features retain the most relevant and discriminative information while minimizing redundant or misleading details. To evaluate the effectiveness of our proposed method, we conducted experiments on popular benchmarks and compared our results with state-of-the-art algorithms. The consistent improvement we observed in these benchmarks demonstrates the efficacy of our approach in enhancing FR performance.
Multi-Context Dual Hyper-Prior Neural Image Compression
Sep 19, 2023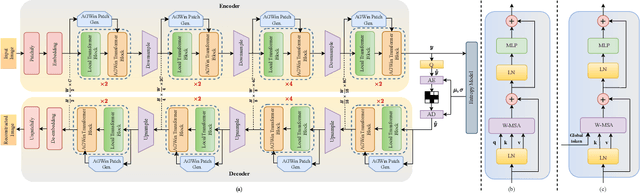
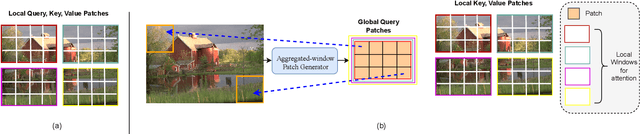
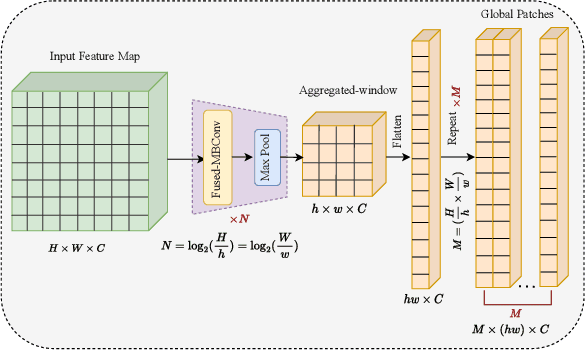
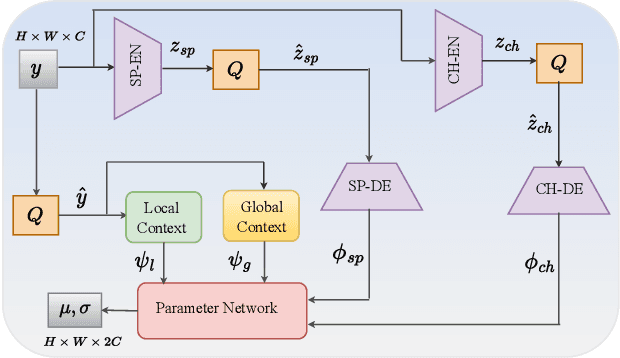
Transform and entropy models are the two core components in deep image compression neural networks. Most existing learning-based image compression methods utilize convolutional-based transform, which lacks the ability to model long-range dependencies, primarily due to the limited receptive field of the convolution operation. To address this limitation, we propose a Transformer-based nonlinear transform. This transform has the remarkable ability to efficiently capture both local and global information from the input image, leading to a more decorrelated latent representation. In addition, we introduce a novel entropy model that incorporates two different hyperpriors to model cross-channel and spatial dependencies of the latent representation. To further improve the entropy model, we add a global context that leverages distant relationships to predict the current latent more accurately. This global context employs a causal attention mechanism to extract long-range information in a content-dependent manner. Our experiments show that our proposed framework performs better than the state-of-the-art methods in terms of rate-distortion performance.
Multi-spectral Entropy Constrained Neural Compression of Solar Imagery
Sep 19, 2023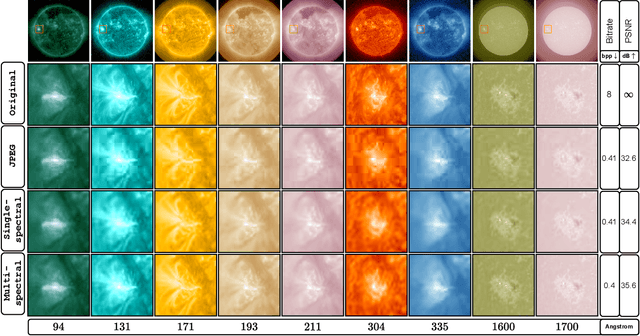
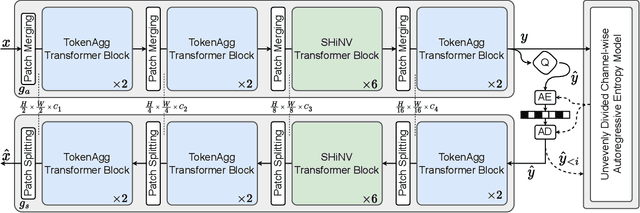
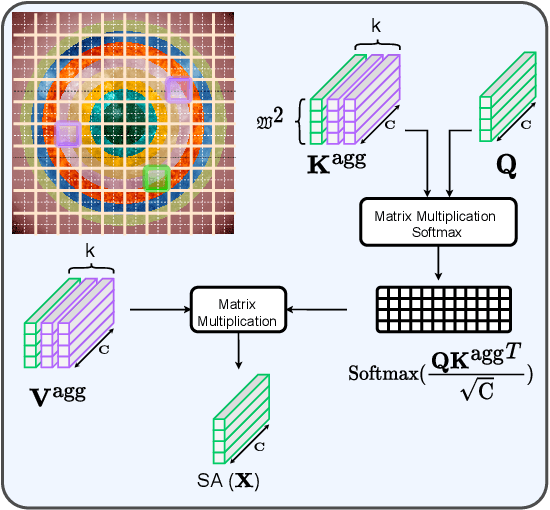
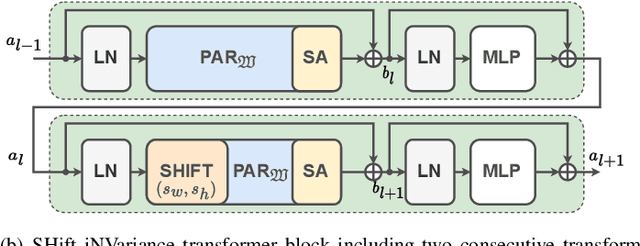
Missions studying the dynamic behaviour of the Sun are defined to capture multi-spectral images of the sun and transmit them to the ground station in a daily basis. To make transmission efficient and feasible, image compression systems need to be exploited. Recently successful end-to-end optimized neural network-based image compression systems have shown great potential to be used in an ad-hoc manner. In this work we have proposed a transformer-based multi-spectral neural image compressor to efficiently capture redundancies both intra/inter-wavelength. To unleash the locality of window-based self attention mechanism, we propose an inter-window aggregated token multi head self attention. Additionally to make the neural compressor autoencoder shift invariant, a randomly shifted window attention mechanism is used which makes the transformer blocks insensitive to translations in their input domain. We demonstrate that the proposed approach not only outperforms the conventional compression algorithms but also it is able to better decorrelates images along the multiple wavelengths compared to single spectral compression.
Context-Aware Neural Video Compression on Solar Dynamics Observatory
Sep 19, 2023
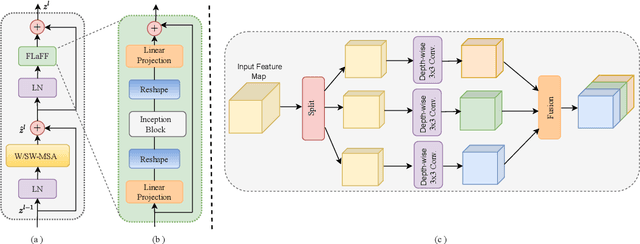
NASA's Solar Dynamics Observatory (SDO) mission collects large data volumes of the Sun's daily activity. Data compression is crucial for space missions to reduce data storage and video bandwidth requirements by eliminating redundancies in the data. In this paper, we present a novel neural Transformer-based video compression approach specifically designed for the SDO images. Our primary objective is to efficiently exploit the temporal and spatial redundancies inherent in solar images to obtain a high compression ratio. Our proposed architecture benefits from a novel Transformer block called Fused Local-aware Window (FLaWin), which incorporates window-based self-attention modules and an efficient fused local-aware feed-forward (FLaFF) network. This architectural design allows us to simultaneously capture short-range and long-range information while facilitating the extraction of rich and diverse contextual representations. Moreover, this design choice results in reduced computational complexity. Experimental results demonstrate the significant contribution of the FLaWin Transformer block to the compression performance, outperforming conventional hand-engineered video codecs such as H.264 and H.265 in terms of rate-distortion trade-off.
Frequency Disentangled Features in Neural Image Compression
Aug 04, 2023The design of a neural image compression network is governed by how well the entropy model matches the true distribution of the latent code. Apart from the model capacity, this ability is indirectly under the effect of how close the relaxed quantization is to the actual hard quantization. Optimizing the parameters of a rate-distortion variational autoencoder (R-D VAE) is ruled by this approximated quantization scheme. In this paper, we propose a feature-level frequency disentanglement to help the relaxed scalar quantization achieve lower bit rates by guiding the high entropy latent features to include most of the low-frequency texture of the image. In addition, to strengthen the de-correlating power of the transformer-based analysis/synthesis transform, an augmented self-attention score calculation based on the Hadamard product is utilized during both encoding and decoding. Channel-wise autoregressive entropy modeling takes advantage of the proposed frequency separation as it inherently directs high-informational low-frequency channels to the first chunks and conditions the future chunks on it. The proposed network not only outperforms hand-engineered codecs, but also neural network-based codecs built on computation-heavy spatially autoregressive entropy models.