 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoRTL: A Run-time Decoding Framework for RTL Code Generation with LLMs
Jul 03, 2025As one of their many applications, large language models (LLMs) have recently shown promise in automating register transfer level (RTL) code generation. However, conventional LLM decoding strategies, originally designed for natural language, often fail to meet the structural and semantic demands of RTL, leading to hallucinated, repetitive, or invalid code outputs. In this paper, we first investigate the root causes of these decoding failures through an empirical analysis of token-level entropy during RTL generation. Our findings reveal that LLMs exhibit low confidence in regions of structural ambiguity or semantic complexity, showing that standard decoding strategies fail to differentiate between regions requiring determinism (syntax-critical regions) and those that benefit from creative exploratory variability (design-critical regions). Then, to overcome this, we introduce DecoRTL, a novel run-time decoding strategy, that is both syntax-aware and contrastive for RTL code generation. DecoRTL integrates two complementary components: (i) self-consistency sampling, which generates multiple candidates and re-ranks them based on token-level agreement to promote correctness while maintaining diversity; and (ii) syntax-aware temperature adaptation, which classifies tokens by their syntactical and functional roles and adjusts the sampling temperature accordingly, enforcing low temperature for syntax-critical tokens and higher temperature for exploratory ones. Our approach operates entirely at inference time without requiring any additional model fine-tuning. Through evaluations on multiple open-source LLMs using the VerilogEval benchmark, we demonstrate significant improvements in syntactic validity, functional correctness, and output diversity, while the execution overhead (performance overhead) is imperceptible.
Trading-off Mutual Information on Feature Aggregation for Face Recognition
Sep 22, 2023Despite the advances in the field of Face Recognition (FR), the precision of these methods is not yet sufficient. To improve the FR performance, this paper proposes a technique to aggregate the outputs of two state-of-the-art (SOTA) deep FR models, namely ArcFace and AdaFace. In our approach, we leverage the transformer attention mechanism to exploit the relationship between different parts of two feature maps. By doing so, we aim to enhance the overall discriminative power of the FR system. One of the challenges in feature aggregation is the effective modeling of both local and global dependencies. Conventional transformers are known for their ability to capture long-range dependencies, but they often struggle with modeling local dependencies accurately. To address this limitation, we augment the self-attention mechanism to capture both local and global dependencies effectively. This allows our model to take advantage of the overlapping receptive fields present in corresponding locations of the feature maps. However, fusing two feature maps from different FR models might introduce redundancies to the face embedding. Since these models often share identical backbone architectures, the resulting feature maps may contain overlapping information, which can mislead the training process. To overcome this problem, we leverage the principle of Information Bottleneck to obtain a maximally informative facial representation. This ensures that the aggregated features retain the most relevant and discriminative information while minimizing redundant or misleading details. To evaluate the effectiveness of our proposed method, we conducted experiments on popular benchmarks and compared our results with state-of-the-art algorithms. The consistent improvement we observed in these benchmarks demonstrates the efficacy of our approach in enhancing FR performance.
Multi-Context Dual Hyper-Prior Neural Image Compression
Sep 19, 2023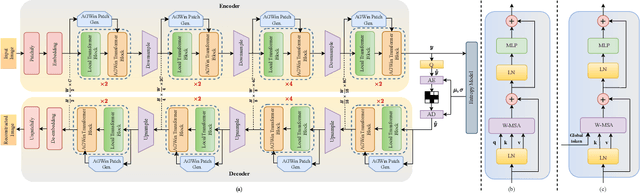
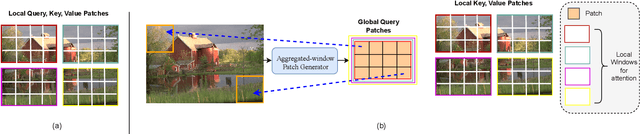
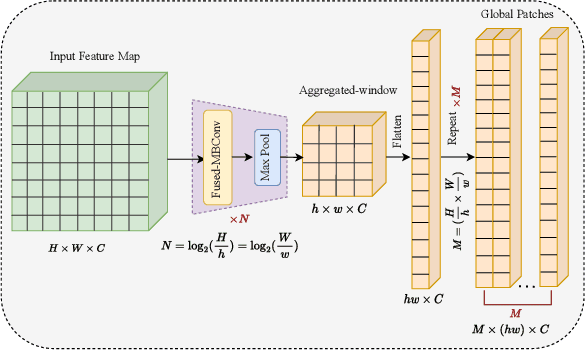
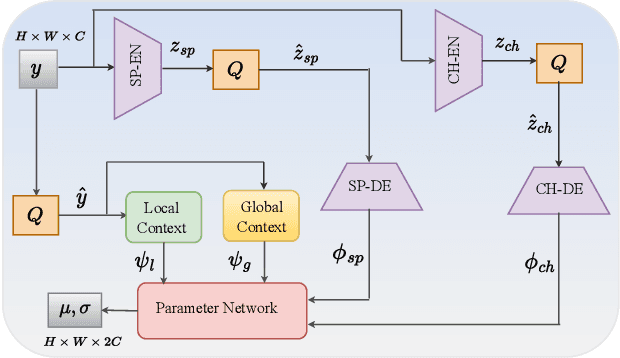
Transform and entropy models are the two core components in deep image compression neural networks. Most existing learning-based image compression methods utilize convolutional-based transform, which lacks the ability to model long-range dependencies, primarily due to the limited receptive field of the convolution operation. To address this limitation, we propose a Transformer-based nonlinear transform. This transform has the remarkable ability to efficiently capture both local and global information from the input image, leading to a more decorrelated latent representation. In addition, we introduce a novel entropy model that incorporates two different hyperpriors to model cross-channel and spatial dependencies of the latent representation. To further improve the entropy model, we add a global context that leverages distant relationships to predict the current latent more accurately. This global context employs a causal attention mechanism to extract long-range information in a content-dependent manner. Our experiments show that our proposed framework performs better than the state-of-the-art methods in terms of rate-distortion performance.
AAFACE: Attribute-aware Attentional Network for Face Recognition
Aug 14, 2023



In this paper, we present a new multi-branch neural network that simultaneously performs soft biometric (SB) prediction as an auxiliary modality and face recognition (FR) as the main task. Our proposed network named AAFace utilizes SB attributes to enhance the discriminative ability of FR representation. To achieve this goal, we propose an attribute-aware attentional integration (AAI) module to perform weighted integration of FR with SB feature maps. Our proposed AAI module is not only fully context-aware but also capable of learning complex relationships between input features by means of the sequential multi-scale channel and spatial sub-modules. Experimental results verify the superiority of our proposed network compared with the state-of-the-art (SoTA) SB prediction and FR methods.
Frequency Disentangled Features in Neural Image Compression
Aug 04, 2023The design of a neural image compression network is governed by how well the entropy model matches the true distribution of the latent code. Apart from the model capacity, this ability is indirectly under the effect of how close the relaxed quantization is to the actual hard quantization. Optimizing the parameters of a rate-distortion variational autoencoder (R-D VAE) is ruled by this approximated quantization scheme. In this paper, we propose a feature-level frequency disentanglement to help the relaxed scalar quantization achieve lower bit rates by guiding the high entropy latent features to include most of the low-frequency texture of the image. In addition, to strengthen the de-correlating power of the transformer-based analysis/synthesis transform, an augmented self-attention score calculation based on the Hadamard product is utilized during both encoding and decoding. Channel-wise autoregressive entropy modeling takes advantage of the proposed frequency separation as it inherently directs high-informational low-frequency channels to the first chunks and conditions the future chunks on it. The proposed network not only outperforms hand-engineered codecs, but also neural network-based codecs built on computation-heavy spatially autoregressive entropy models.
DTW-Merge: A Novel Data Augmentation Technique for Time Series Classification
Mar 01, 2021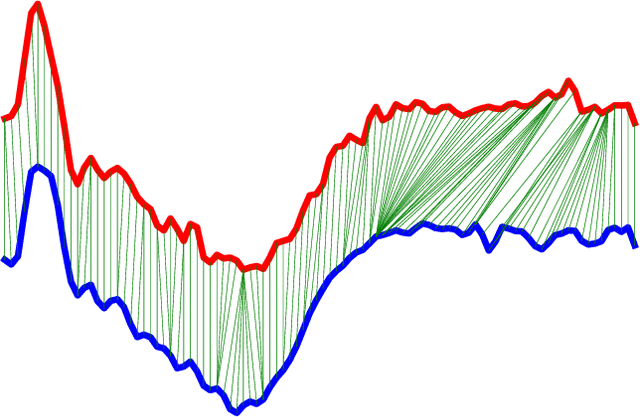
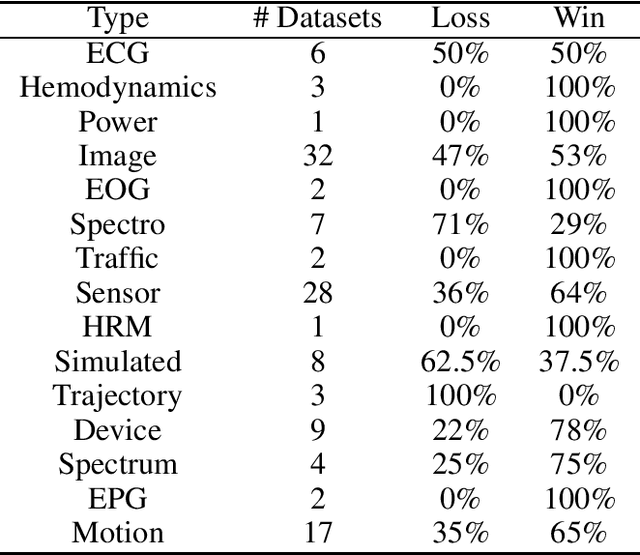
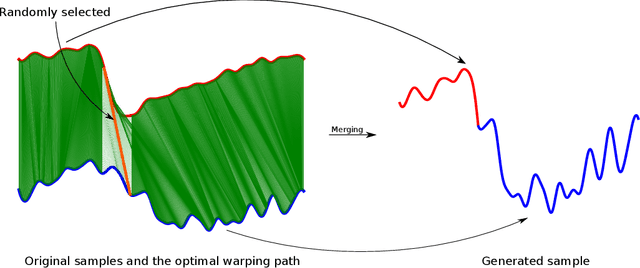
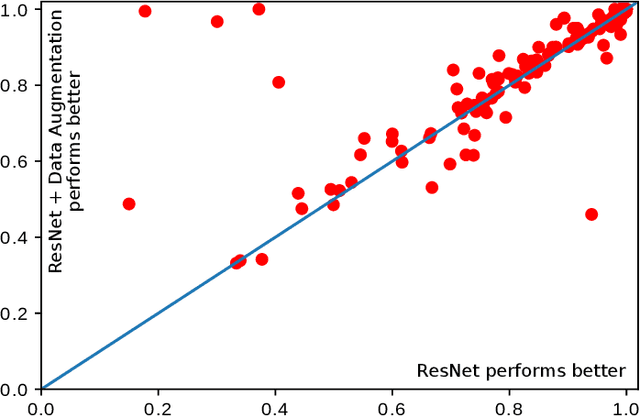
In recent years, neural networks achieved much success in various applications. The main challenge in training deep neural networks is the lack of sufficient data to improve the model's generalization and avoid overfitting. One of the solutions is to generate new training samples. This paper proposes a novel data augmentation method for time series based on Dynamic Time Warping. This method is inspired by the concept that warped parts of two time series have the same temporal properties. Exploiting the proposed approach with recently-introduced ResNet reveals the improvement of results on the 2018 UCR Time Series Classification Archive.