 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposed Distribution Matching in Dataset Condensation
Dec 06, 2024
Dataset Condensation (DC) aims to reduce deep neural networks training efforts by synthesizing a small dataset such that it will be as effective as the original large dataset. Conventionally, DC relies on a costly bi-level optimization which prohibits its practicality. Recent research formulates DC as a distribution matching problem which circumvents the costly bi-level optimization. However, this efficiency sacrifices the DC performance. To investigate this performance degradation, we decomposed the dataset distribution into content and style. Our observations indicate two major shortcomings of: 1) style discrepancy between original and condensed data, and 2) limited intra-class diversity of condensed dataset. We present a simple yet effective method to match the style information between original and condensed data, employing statistical moments of feature maps as well-established style indicators. Moreover, we enhance the intra-class diversity by maximizing the Kullback-Leibler divergence within each synthetic class, i.e., content. We demonstrate the efficacy of our method through experiments on diverse datasets of varying size and resolution, achieving improvements of up to 4.1% on CIFAR10, 4.2% on CIFAR100, 4.3% on TinyImageNet, 2.0% on ImageNet-1K, 3.3% on ImageWoof, 2.5% on ImageNette, and 5.5% in continual learning accuracy.
Boosting Unconstrained Face Recognition with Targeted Style Adversary
Aug 14, 2024



While deep face recognition models have demonstrated remarkable performance, they often struggle on the inputs from domains beyond their training data. Recent attempts aim to expand the training set by relying on computationally expensive and inherently challenging image-space augmentation of image generation modules. In an orthogonal direction, we present a simple yet effective method to expand the training data by interpolating between instance-level feature statistics across labeled and unlabeled sets. Our method, dubbed Targeted Style Adversary (TSA), is motivated by two observations: (i) the input domain is reflected in feature statistics, and (ii) face recognition model performance is influenced by style information. Shifting towards an unlabeled style implicitly synthesizes challenging training instances. We devise a recognizability metric to constraint our framework to preserve the inherent identity-related information of labeled instances. The efficacy of our method is demonstrated through evaluations on unconstrained benchmarks, outperforming or being on par with its competitors while offering nearly a 70\% improvement in training speed and 40\% less memory consumption.
ARoFace: Alignment Robustness to Improve Low-Quality Face Recognition
Jul 20, 2024



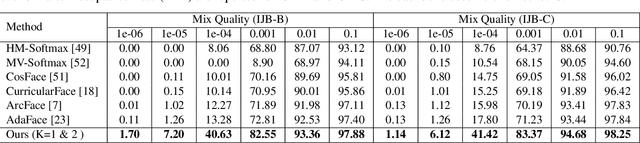
Aiming to enhance Face Recognition (FR) on Low-Quality (LQ) inputs, recent studies suggest incorporating synthetic LQ samples into training. Although promising, the quality factors that are considered in these works are general rather than FR-specific, \eg, atmospheric turbulence, resolution, \etc. Motivated by the observation of the vulnerability of current FR models to even small Face Alignment Errors (FAE) in LQ images, we present a simple yet effective method that considers FAE as another quality factor that is tailored to FR. We seek to improve LQ FR by enhancing FR models' robustness to FAE. To this aim, we formalize the problem as a combination of differentiable spatial transformations and adversarial data augmentation in FR. We perturb the alignment of the training samples using a controllable spatial transformation and enrich the training with samples expressing FAE. We demonstrate the benefits of the proposed method by conducting evaluations on IJB-B, IJB-C, IJB-S (+4.3\% Rank1), and TinyFace (+2.63\%). \href{https://github.com/msed-Ebrahimi/ARoFace}{https://github.com/msed-Ebrahimi/ARoFace}
Hyperspherical Classification with Dynamic Label-to-Prototype Assignment
Mar 25, 2024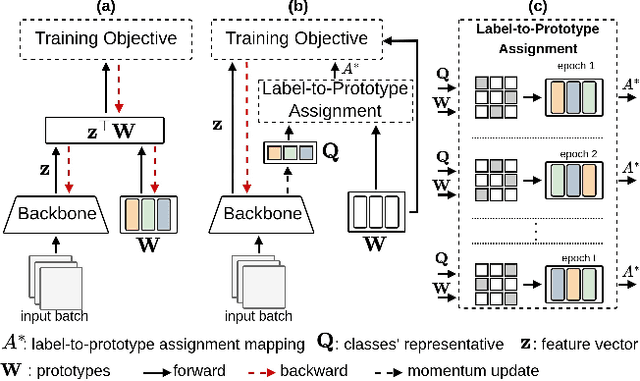

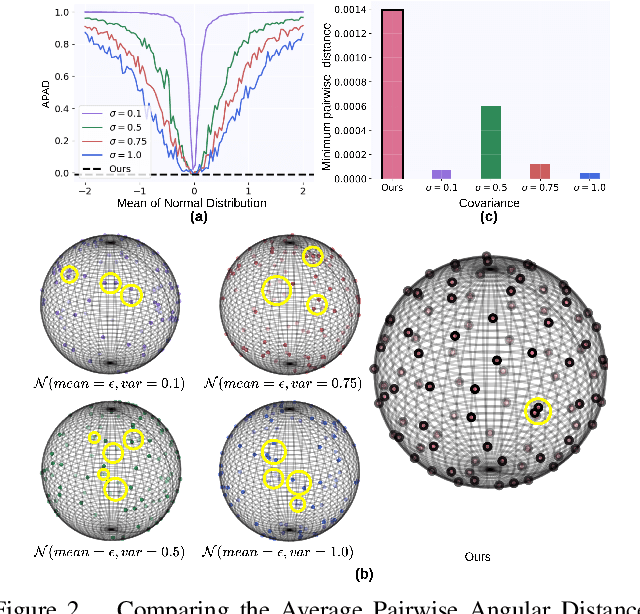
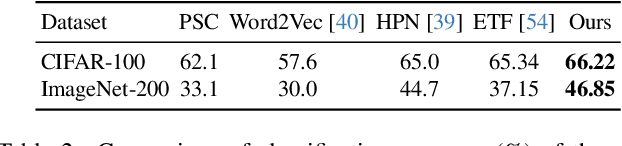
Aiming to enhance the utilization of metric space by the parametric softmax classifier, recent studies suggest replacing it with a non-parametric alternative. Although a non-parametric classifier may provide better metric space utilization, it introduces the challenge of capturing inter-class relationships. A shared characteristic among prior non-parametric classifiers is the static assignment of labels to prototypes during the training, ie, each prototype consistently represents a class throughout the training course. Orthogonal to previous works, we present a simple yet effective method to optimize the category assigned to each prototype (label-to-prototype assignment) during the training. To this aim, we formalize the problem as a two-step optimization objective over network parameters and label-to-prototype assignment mapping. We solve this optimization using a sequential combination of gradient descent and Bipartide matching. We demonstrate the benefits of the proposed approach by conducting experiments on balanced and long-tail classification problems using different backbone network architectures. In particular, our method outperforms its competitors by 1.22\% accuracy on CIFAR-100, and 2.15\% on ImageNet-200 using a metric space dimension half of the size of its competitors. Code: https://github.com/msed-Ebrahimi/DL2PA_CVPR24
Deep Boosting Multi-Modal Ensemble Face Recognition with Sample-Level Weighting
Aug 18, 2023


Deep convolutional neural networks have achieved remarkable success in face recognition (FR), partly due to the abundant data availability. However, the current training benchmarks exhibit an imbalanced quality distribution; most images are of high quality. This poses issues for generalization on hard samples since they are underrepresented during training. In this work, we employ the multi-model boosting technique to deal with this issue. Inspired by the well-known AdaBoost, we propose a sample-level weighting approach to incorporate the importance of different samples into the FR loss. Individual models of the proposed framework are experts at distinct levels of sample hardness. Therefore, the combination of models leads to a robust feature extractor without losing the discriminability on the easy samples. Also, for incorporating the sample hardness into the training criterion, we analytically show the effect of sample mining on the important aspects of current angular margin loss functions, i.e., margin and scale. The proposed method shows superior performance in comparison with the state-of-the-art algorithms in extensive experiments on the CFP-FP, LFW, CPLFW, CALFW, AgeDB, TinyFace, IJB-B, and IJB-C evaluation datasets.
CCFace: Classification Consistency for Low-Resolution Face Recognition
Aug 18, 2023In recent years, deep face recognition methods have demonstrated impressive results on in-the-wild datasets. However, these methods have shown a significant decline in performance when applied to real-world low-resolution benchmarks like TinyFace or SCFace. To address this challenge, we propose a novel classification consistency knowledge distillation approach that transfers the learned classifier from a high-resolution model to a low-resolution network. This approach helps in finding discriminative representations for low-resolution instances. To further improve the performance, we designed a knowledge distillation loss using the adaptive angular penalty inspired by the success of the popular angular margin loss function. The adaptive penalty reduces overfitting on low-resolution samples and alleviates the convergence issue of the model integrated with data augmentation. Additionally, we utilize an asymmetric cross-resolution learning approach based on the state-of-the-art semi-supervised representation learning paradigm to improve discriminability on low-resolution instances and prevent them from forming a cluster. Our proposed method outperforms state-of-the-art approaches on low-resolution benchmarks, with a three percent improvement on TinyFace while maintaining performance on high-resolution benchmarks.
AAFACE: Attribute-aware Attentional Network for Face Recognition
Aug 14, 2023



In this paper, we present a new multi-branch neural network that simultaneously performs soft biometric (SB) prediction as an auxiliary modality and face recognition (FR) as the main task. Our proposed network named AAFace utilizes SB attributes to enhance the discriminative ability of FR representation. To achieve this goal, we propose an attribute-aware attentional integration (AAI) module to perform weighted integration of FR with SB feature maps. Our proposed AAI module is not only fully context-aware but also capable of learning complex relationships between input features by means of the sequential multi-scale channel and spatial sub-modules. Experimental results verify the superiority of our proposed network compared with the state-of-the-art (SoTA) SB prediction and FR methods.
A Quality Aware Sample-to-Sample Comparison for Face Recognition
Jun 06, 2023Currently available face datasets mainly consist of a large number of high-quality and a small number of low-quality samples. As a result, a Face Recognition (FR) network fails to learn the distribution of low-quality samples since they are less frequent during training (underrepresented). Moreover, current state-of-the-art FR training paradigms are based on the sample-to-center comparison (i.e., Softmax-based classifier), which results in a lack of uniformity between train and test metrics. This work integrates a quality-aware learning process at the sample level into the classification training paradigm (QAFace). In this regard, Softmax centers are adaptively guided to pay more attention to low-quality samples by using a quality-aware function. Accordingly, QAFace adds a quality-based adjustment to the updating procedure of the Softmax-based classifier to improve the performance on the underrepresented low-quality samples. Our method adaptively finds and assigns more attention to the recognizable low-quality samples in the training datasets. In addition, QAFace ignores the unrecognizable low-quality samples using the feature magnitude as a proxy for quality. As a result, QAFace prevents class centers from getting distracted from the optimal direction. The proposed method is superior to the state-of-the-art algorithms in extensive experimental results on the CFP-FP, LFW, CPLFW, CALFW, AgeDB, IJB-B, and IJB-C datasets.
Pose Attention-Guided Profile-to-Frontal Face Recognition
Sep 15, 2022
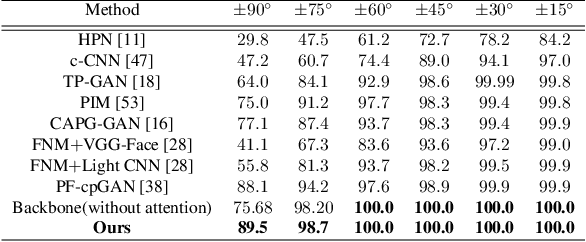
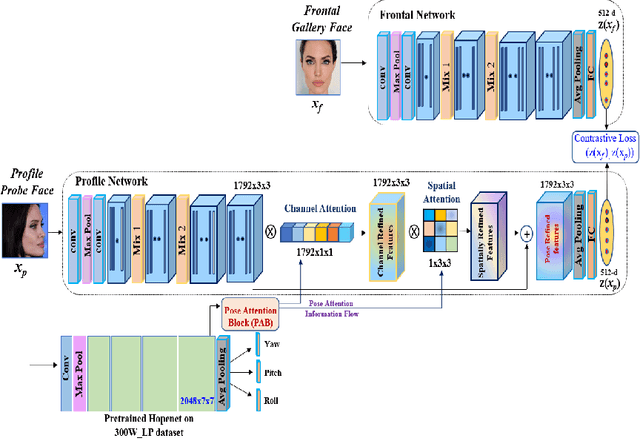
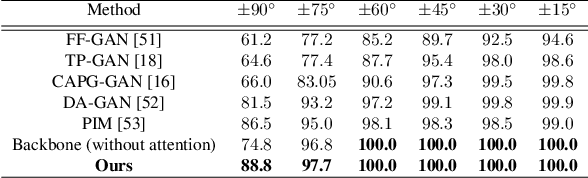
In recent years, face recognition systems have achieved exceptional success due to promising advances in deep learning architectures. However, they still fail to achieve expected accuracy when matching profile images against a gallery of frontal images. Current approaches either perform pose normalization (i.e., frontalization) or disentangle pose information for face recognition. We instead propose a new approach to utilize pose as an auxiliary information via an attention mechanism. In this paper, we hypothesize that pose attended information using an attention mechanism can guide contextual and distinctive feature extraction from profile faces, which further benefits a better representation learning in an embedded domain. To achieve this, first, we design a unified coupled profile-to-frontal face recognition network. It learns the mapping from faces to a compact embedding subspace via a class-specific contrastive loss. Second, we develop a novel pose attention block (PAB) to specially guide the pose-agnostic feature extraction from profile faces. To be more specific, PAB is designed to explicitly help the network to focus on important features along both channel and spatial dimension while learning discriminative yet pose invariant features in an embedding subspace. To validate the effectiveness of our proposed method, we conduct experiments on both controlled and in the wild benchmarks including Multi-PIE, CFP, IJBC, and show superiority over the state of the arts.
Information Maximization for Extreme Pose Face Recognition
Sep 07, 2022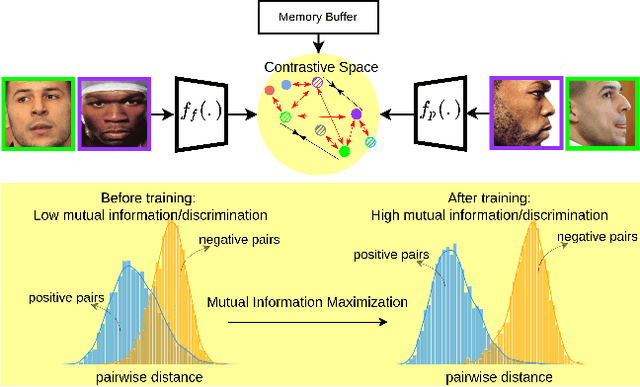
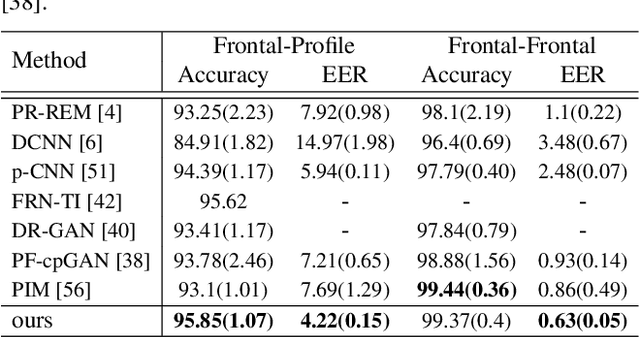
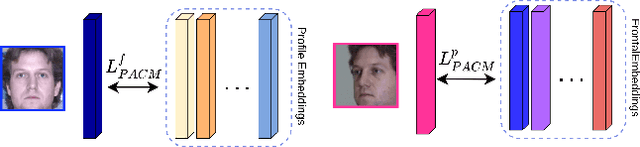
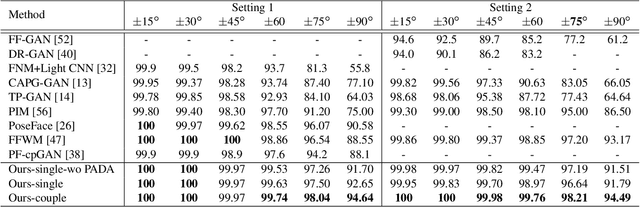
In this paper, we seek to draw connections between the frontal and profile face images in an abstract embedding space. We exploit this connection using a coupled-encoder network to project frontal/profile face images into a common latent embedding space. The proposed model forces the similarity of representations in the embedding space by maximizing the mutual information between two views of the face. The proposed coupled-encoder benefits from three contributions for matching faces with extreme pose disparities. First, we leverage our pose-aware contrastive learning to maximize the mutual information between frontal and profile representations of identities. Second, a memory buffer, which consists of latent representations accumulated over past iterations, is integrated into the model so it can refer to relatively much more instances than the mini-batch size. Third, a novel pose-aware adversarial domain adaptation method forces the model to learn an asymmetric mapping from profile to frontal representation. In our framework, the coupled-encoder learns to enlarge the margin between the distribution of genuine and imposter faces, which results in high mutual information between different views of the same identity. The effectiveness of the proposed model is investigated through extensive experiments, evaluations, and ablation studies on four benchmark datasets, and comparison with the compelling state-of-the-art algorithms.