 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quality Aware Sample-to-Sample Comparison for Face Recognition
Jun 06, 2023Currently available face datasets mainly consist of a large number of high-quality and a small number of low-quality samples. As a result, a Face Recognition (FR) network fails to learn the distribution of low-quality samples since they are less frequent during training (underrepresented). Moreover, current state-of-the-art FR training paradigms are based on the sample-to-center comparison (i.e., Softmax-based classifier), which results in a lack of uniformity between train and test metrics. This work integrates a quality-aware learning process at the sample level into the classification training paradigm (QAFace). In this regard, Softmax centers are adaptively guided to pay more attention to low-quality samples by using a quality-aware function. Accordingly, QAFace adds a quality-based adjustment to the updating procedure of the Softmax-based classifier to improve the performance on the underrepresented low-quality samples. Our method adaptively finds and assigns more attention to the recognizable low-quality samples in the training datasets. In addition, QAFace ignores the unrecognizable low-quality samples using the feature magnitude as a proxy for quality. As a result, QAFace prevents class centers from getting distracted from the optimal direction. The proposed method is superior to the state-of-the-art algorithms in extensive experimental results on the CFP-FP, LFW, CPLFW, CALFW, AgeDB, IJB-B, and IJB-C datasets.
Pose Attention-Guided Profile-to-Frontal Face Recognition
Sep 15, 2022
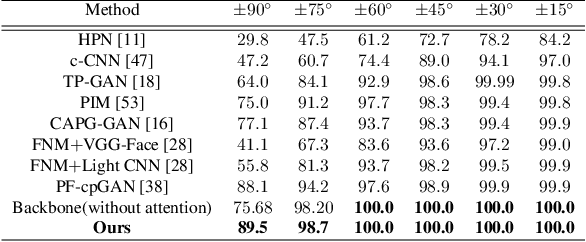
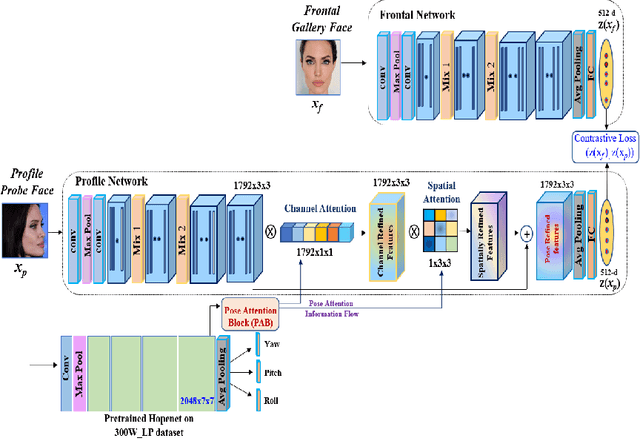
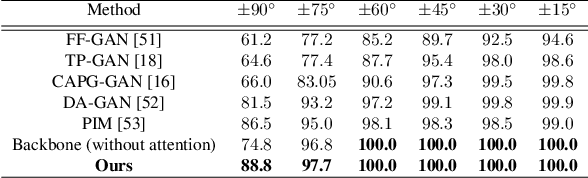
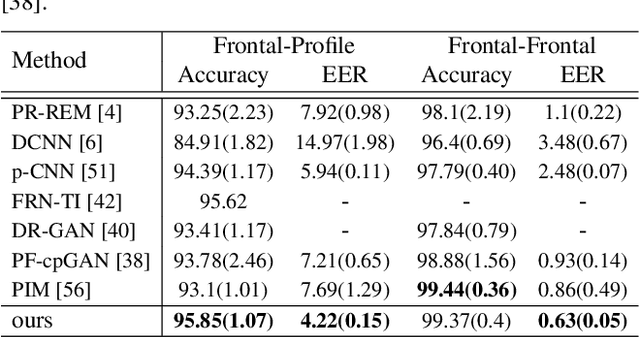
In recent years, face recognition systems have achieved exceptional success due to promising advances in deep learning architectures. However, they still fail to achieve expected accuracy when matching profile images against a gallery of frontal images. Current approaches either perform pose normalization (i.e., frontalization) or disentangle pose information for face recognition. We instead propose a new approach to utilize pose as an auxiliary information via an attention mechanism. In this paper, we hypothesize that pose attended information using an attention mechanism can guide contextual and distinctive feature extraction from profile faces, which further benefits a better representation learning in an embedded domain. To achieve this, first, we design a unified coupled profile-to-frontal face recognition network. It learns the mapping from faces to a compact embedding subspace via a class-specific contrastive loss. Second, we develop a novel pose attention block (PAB) to specially guide the pose-agnostic feature extraction from profile faces. To be more specific, PAB is designed to explicitly help the network to focus on important features along both channel and spatial dimension while learning discriminative yet pose invariant features in an embedding subspace. To validate the effectiveness of our proposed method, we conduct experiments on both controlled and in the wild benchmarks including Multi-PIE, CFP, IJBC, and show superiority over the state of the arts.
Information Maximization for Extreme Pose Face Recognition
Sep 07, 2022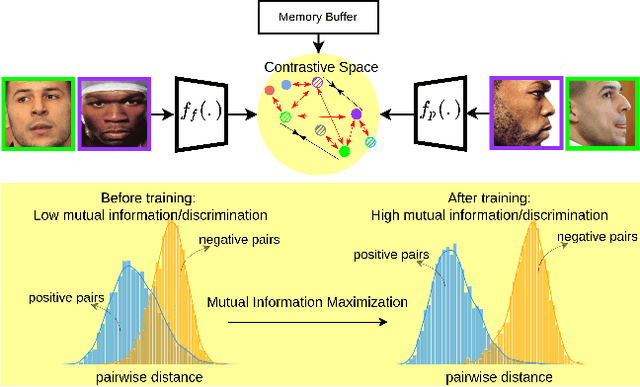
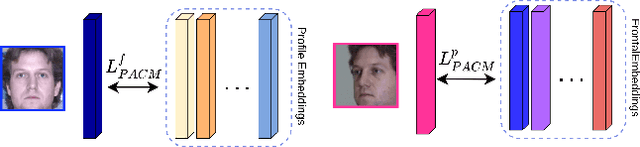
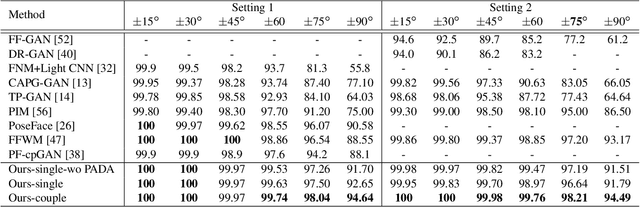
In this paper, we seek to draw connections between the frontal and profile face images in an abstract embedding space. We exploit this connection using a coupled-encoder network to project frontal/profile face images into a common latent embedding space. The proposed model forces the similarity of representations in the embedding space by maximizing the mutual information between two views of the face. The proposed coupled-encoder benefits from three contributions for matching faces with extreme pose disparities. First, we leverage our pose-aware contrastive learning to maximize the mutual information between frontal and profile representations of identities. Second, a memory buffer, which consists of latent representations accumulated over past iterations, is integrated into the model so it can refer to relatively much more instances than the mini-batch size. Third, a novel pose-aware adversarial domain adaptation method forces the model to learn an asymmetric mapping from profile to frontal representation. In our framework, the coupled-encoder learns to enlarge the margin between the distribution of genuine and imposter faces, which results in high mutual information between different views of the same identity. The effectiveness of the proposed model is investigated through extensive experiments, evaluations, and ablation studies on four benchmark datasets, and comparison with the compelling state-of-the-art algorithms.
Deep GAN-Based Cross-Spectral Cross-Resolution Iris Recognition
Aug 03, 2021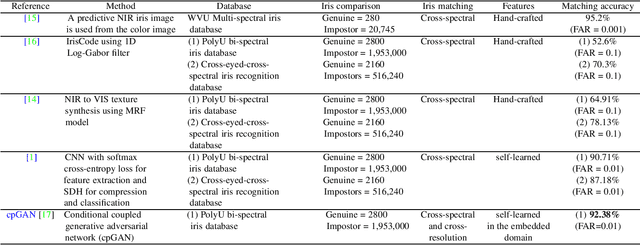
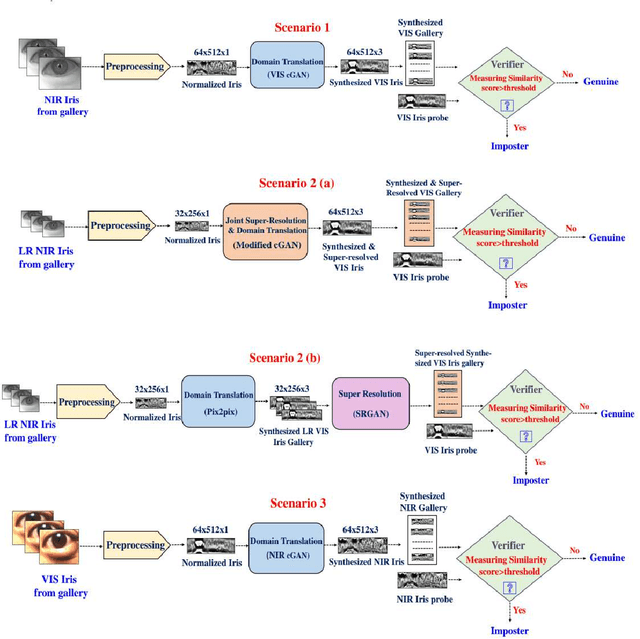
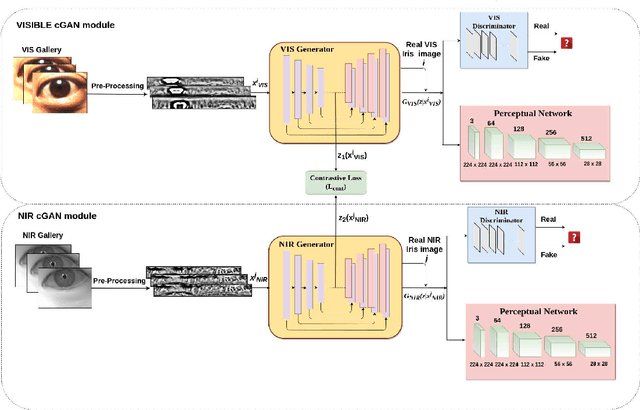
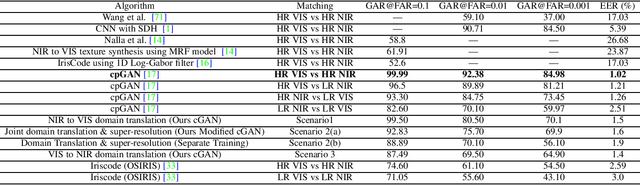
In recent years, cross-spectral iris recognition has emerged as a promising biometric approach to establish the identity of individuals. However, matching iris images acquired at different spectral bands (i.e., matching a visible (VIS) iris probe to a gallery of near-infrared (NIR) iris images or vice versa) shows a significant performance degradation when compared to intraband NIR matching. Hence, in this paper, we have investigated a range of deep convolutional generative adversarial network (DCGAN) architectures to further improve the accuracy of cross-spectral iris recognition methods. Moreover, unlike the existing works in the literature, we introduce a resolution difference into the classical cross-spectral matching problem domain. We have developed two different techniques using the conditional generative adversarial network (cGAN) as a backbone architecture for cross-spectral iris matching. In the first approach, we simultaneously address the cross-resolution and cross-spectral matching problem by training a cGAN that jointly translates cross-resolution as well as cross-spectral tasks to the same resolution and within the same spectrum. In the second approach, we design a coupled generative adversarial network (cpGAN) architecture consisting of a pair of cGAN modules that project the VIS and NIR iris images into a low-dimensional embedding domain to ensure maximum pairwise similarity between the feature vectors from the two iris modalities of the same subject.
Cross-Spectral Iris Matching Using Conditional Coupled GAN
Oct 09, 2020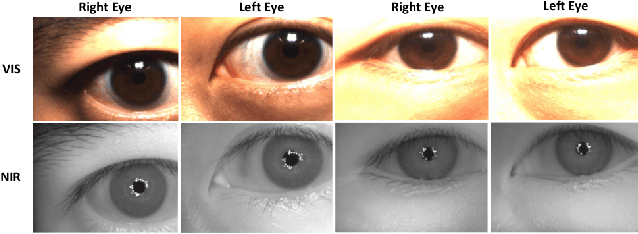
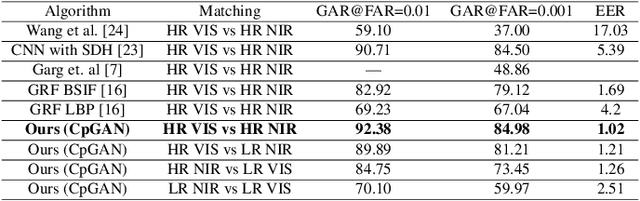
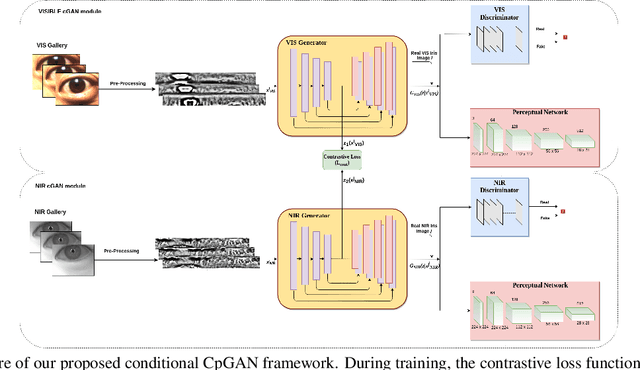

Cross-spectral iris recognition is emerging as a promising biometric approach to authenticating the identity of individuals. However, matching iris images acquired at different spectral bands shows significant performance degradation when compared to single-band near-infrared (NIR) matching due to the spectral gap between iris images obtained in the NIR and visual-light (VIS) spectra. Although researchers have recently focused on deep-learning-based approaches to recover invariant representative features for more accurate recognition performance, the existing methods cannot achieve the expected accuracy required for commercial applications. Hence, in this paper, we propose a conditional coupled generative adversarial network (CpGAN) architecture for cross-spectral iris recognition by projecting the VIS and NIR iris images into a low-dimensional embedding domain to explore the hidden relationship between them. The conditional CpGAN framework consists of a pair of GAN-based networks, one responsible for retrieving images in the visible domain and other responsible for retrieving images in the NIR domain. Both networks try to map the data into a common embedding subspace to ensure maximum pair-wise similarity between the feature vectors from the two iris modalities of the same subject. To prove the usefulness of our proposed approach, extensive experimental results obtained on the PolyU dataset are compared to existing state-of-the-art cross-spectral recognition methods.
Joint-SRVDNet: Joint Super Resolution and Vehicle Detection Network
May 03, 2020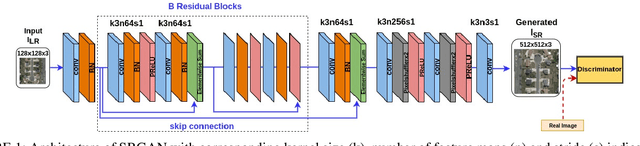

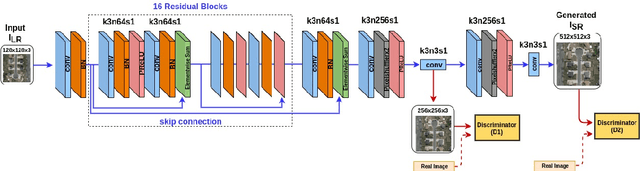
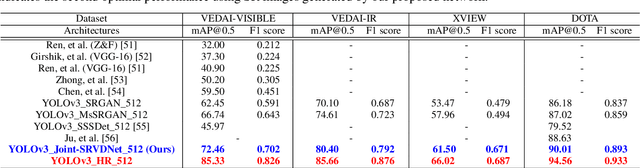
In many domestic and military applications, aerial vehicle detection and super-resolutionalgorithms are frequently developed and applied independently. However, aerial vehicle detection on super-resolved images remains a challenging task due to the lack of discriminative information in the super-resolved images. To address this problem, we propose a Joint Super-Resolution and Vehicle DetectionNetwork (Joint-SRVDNet) that tries to generate discriminative, high-resolution images of vehicles fromlow-resolution aerial images. First, aerial images are up-scaled by a factor of 4x using a Multi-scaleGenerative Adversarial Network (MsGAN), which has multiple intermediate outputs with increasingresolutions. Second, a detector is trained on super-resolved images that are upscaled by factor 4x usingMsGAN architecture and finally, the detection loss is minimized jointly with the super-resolution loss toencourage the target detector to be sensitive to the subsequent super-resolution training. The network jointlylearns hierarchical and discriminative features of targets and produces optimal super-resolution results. Weperform both quantitative and qualitative evaluation of our proposed network on VEDAI, xView and DOTAdatasets. The experimental results show that our proposed framework achieves better visual quality than thestate-of-the-art methods for aerial super-resolution with 4x up-scaling factor and improves the accuracy ofaerial vehicle detection.