 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Ensemble Person Re-Identification via Orthogonal Fusion with Occlusion Handling
Mar 29, 2024



Occlusion remains one of the major challenges in person reidentification (ReID) as a result of the diversity of poses and the variation of appearances. Developing novel architectures to improve the robustness of occlusion-aware person Re-ID requires new insights, especially on low-resolution edge cameras. We propose a deep ensemble model that harnesses both CNN and Transformer architectures to generate robust feature representations. To achieve robust Re-ID without the need to manually label occluded regions, we propose to take an ensemble learning-based approach derived from the analogy between arbitrarily shaped occluded regions and robust feature representation. Using the orthogonality principle, our developed deep CNN model makes use of masked autoencoder (MAE) and global-local feature fusion for robust person identification. Furthermore, we present a part occlusion-aware transformer capable of learning feature space that is robust to occluded regions. Experimental results are reported on several Re-ID datasets to show the effectiveness of our developed ensemble model named orthogonal fusion with occlusion handling (OFOH). Compared to competing methods, the proposed OFOH approach has achieved competent rank-1 and mAP performance.
Analysis of Biomass Sustainability Indicators from a Machine Learning Perspective
Feb 02, 2023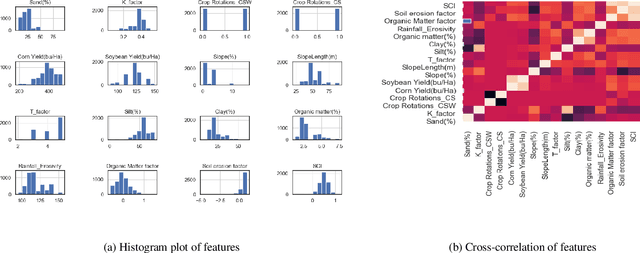
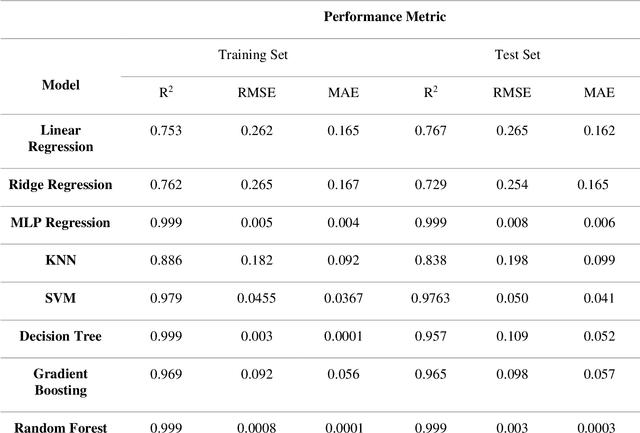
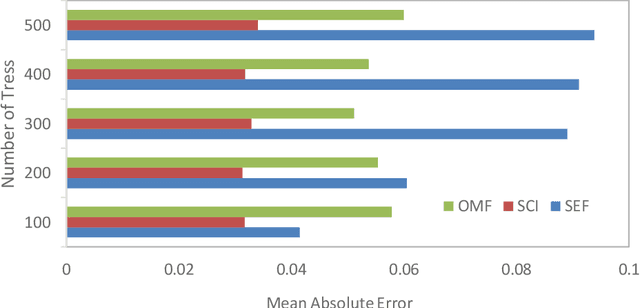
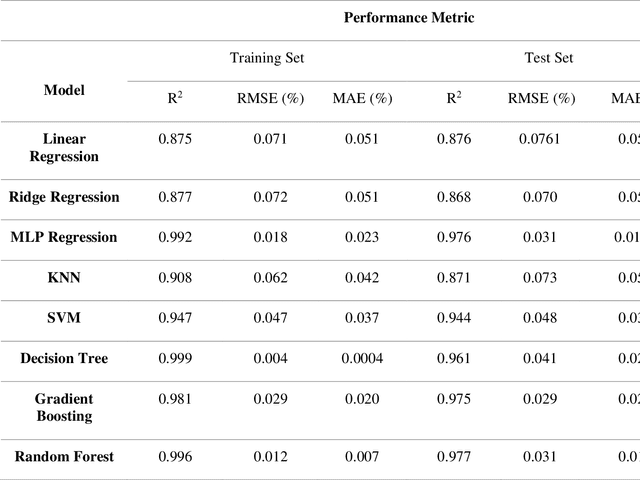
Plant biomass estimation is critical due to the variability of different environmental factors and crop management practices associated with it. The assessment is largely impacted by the accurate prediction of different environmental sustainability indicators. A robust model to predict sustainability indicators is a must for the biomass community. This study proposes a robust model for biomass sustainability prediction by analyzing sustainability indicators using machine learning models. The prospect of ensemble learning was also investigated to analyze the regression problem. All experiments were carried out on a crop residue data from the Ohio state. Ten machine learning models, namely, linear regression, ridge regression, multilayer perceptron, k-nearest neighbors, support vector machine, decision tree, gradient boosting, random forest, stacking and voting, were analyzed to estimate three biomass sustainability indicators, namely soil erosion factor, soil conditioning index, and organic matter factor. The performance of the model was assessed using cross-correlation (R2), root mean squared error and mean absolute error metrics. The results showed that Random Forest was the best performing model to assess sustainability indicators. The analyzed model can now serve as a guide for assessing sustainability indicators in real time.
Uncertainty Aware Multitask Pyramid Vision Transformer For UAV-Based Object Re-Identification
Sep 19, 2022
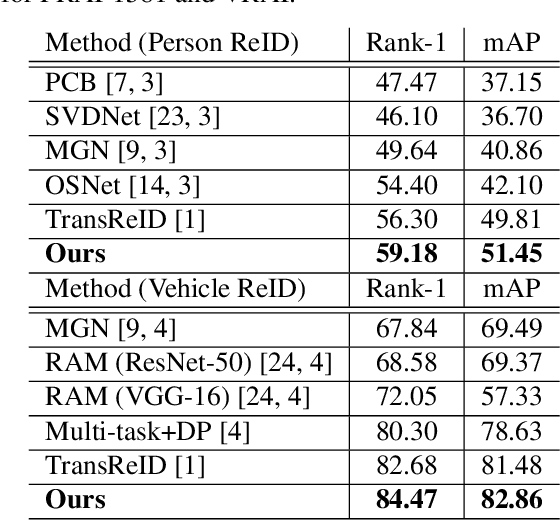
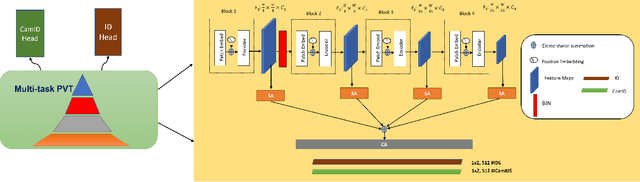
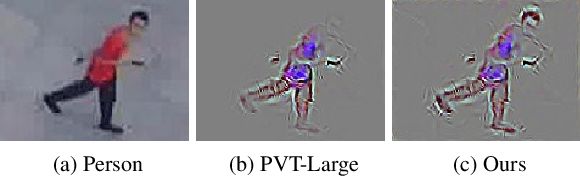
Object Re-IDentification (ReID), one of the most significant problems in biometrics and surveillance systems, has been extensively studied by image processing and computer vision communities in the past decades. Learning a robust and discriminative feature representation is a crucial challenge for object ReID. The problem is even more challenging in ReID based on Unmanned Aerial Vehicle (UAV) as the images are characterized by continuously varying camera parameters (e.g., view angle, altitude, etc.) of a flying drone. To address this challenge, multiscale feature representation has been considered to characterize images captured from UAV flying at different altitudes. In this work, we propose a multitask learning approach, which employs a new multiscale architecture without convolution, Pyramid Vision Transformer (PVT), as the backbone for UAV-based object ReID. By uncertainty modeling of intraclass variations, our proposed model can be jointly optimized using both uncertainty-aware object ID and camera ID information. Experimental results are reported on PRAI and VRAI, two ReID data sets from aerial surveillance, to verify the effectiveness of our proposed approach
Super-resolution Guided Pore Detection for Fingerprint Recognition
Dec 10, 2020



Performance of fingerprint recognition algorithms substantially rely on fine features extracted from fingerprints. Apart from minutiae and ridge patterns, pore features have proven to be usable for fingerprint recognition. Although features from minutiae and ridge patterns are quite attainable from low-resolution images, using pore features is practical only if the fingerprint image is of high resolution which necessitates a model that enhances the image quality of the conventional 500 ppi legacy fingerprints preserving the fine details. To find a solution for recovering pore information from low-resolution fingerprints, we adopt a joint learning-based approach that combines both super-resolution and pore detection networks. Our modified single image Super-Resolution Generative Adversarial Network (SRGAN) framework helps to reliably reconstruct high-resolution fingerprint samples from low-resolution ones assisting the pore detection network to identify pores with a high accuracy. The network jointly learns a distinctive feature representation from a real low-resolution fingerprint sample and successfully synthesizes a high-resolution sample from it. To add discriminative information and uniqueness for all the subjects, we have integrated features extracted from a deep fingerprint verifier with the SRGAN quality discriminator. We also add ridge reconstruction loss, utilizing ridge patterns to make the best use of extracted features. Our proposed method solves the recognition problem by improving the quality of fingerprint images. High recognition accuracy of the synthesized samples that is close to the accuracy achieved using the original high-resolution images validate the effectiveness of our proposed model.
Joint-SRVDNet: Joint Super Resolution and Vehicle Detection Network
May 03, 2020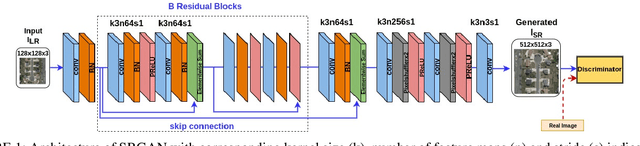

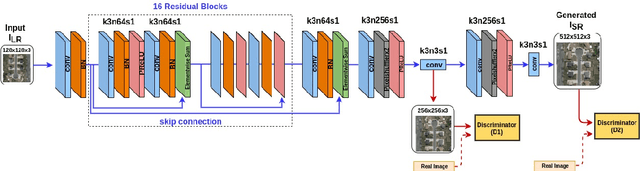
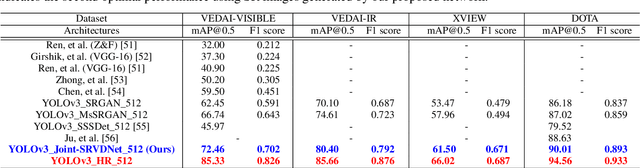
In many domestic and military applications, aerial vehicle detection and super-resolutionalgorithms are frequently developed and applied independently. However, aerial vehicle detection on super-resolved images remains a challenging task due to the lack of discriminative information in the super-resolved images. To address this problem, we propose a Joint Super-Resolution and Vehicle DetectionNetwork (Joint-SRVDNet) that tries to generate discriminative, high-resolution images of vehicles fromlow-resolution aerial images. First, aerial images are up-scaled by a factor of 4x using a Multi-scaleGenerative Adversarial Network (MsGAN), which has multiple intermediate outputs with increasingresolutions. Second, a detector is trained on super-resolved images that are upscaled by factor 4x usingMsGAN architecture and finally, the detection loss is minimized jointly with the super-resolution loss toencourage the target detector to be sensitive to the subsequent super-resolution training. The network jointlylearns hierarchical and discriminative features of targets and produces optimal super-resolution results. Weperform both quantitative and qualitative evaluation of our proposed network on VEDAI, xView and DOTAdatasets. The experimental results show that our proposed framework achieves better visual quality than thestate-of-the-art methods for aerial super-resolution with 4x up-scaling factor and improves the accuracy ofaerial vehicle detection.