 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing material property prediction with ensemble deep graph convolutional networks
Jul 26, 2024



Machine learning (ML) models have emerged as powerful tools for accelerating materials discovery and design by enabling accurate predictions of properties from compositional and structural data. These capabilities are vital for developing advanced technologies across fields such as energy, electronics, and biomedicine, potentially reducing the time and resources needed for new material exploration and promoting rapid innovation cycles. Recent efforts have focused on employing advanced ML algorithms, including deep learning - based graph neural network, for property prediction. Additionally, ensemble models have proven to enhance the generalizability and robustness of ML and DL. However, the use of such ensemble strategies in deep graph networks for material property prediction remains underexplored. Our research provides an in-depth evaluation of ensemble strategies in deep learning - based graph neural network, specifically targeting material property prediction tasks. By testing the Crystal Graph Convolutional Neural Network (CGCNN) and its multitask version, MT-CGCNN, we demonstrated that ensemble techniques, especially prediction averaging, substantially improve precision beyond traditional metrics for key properties like formation energy per atom ($\Delta E^{f}$), band gap ($E_{g}$) and density ($\rho$) in 33,990 stable inorganic materials. These findings support the broader application of ensemble methods to enhance predictive accuracy in the field.
Super-resolution Guided Pore Detection for Fingerprint Recognition
Dec 10, 2020



Performance of fingerprint recognition algorithms substantially rely on fine features extracted from fingerprints. Apart from minutiae and ridge patterns, pore features have proven to be usable for fingerprint recognition. Although features from minutiae and ridge patterns are quite attainable from low-resolution images, using pore features is practical only if the fingerprint image is of high resolution which necessitates a model that enhances the image quality of the conventional 500 ppi legacy fingerprints preserving the fine details. To find a solution for recovering pore information from low-resolution fingerprints, we adopt a joint learning-based approach that combines both super-resolution and pore detection networks. Our modified single image Super-Resolution Generative Adversarial Network (SRGAN) framework helps to reliably reconstruct high-resolution fingerprint samples from low-resolution ones assisting the pore detection network to identify pores with a high accuracy. The network jointly learns a distinctive feature representation from a real low-resolution fingerprint sample and successfully synthesizes a high-resolution sample from it. To add discriminative information and uniqueness for all the subjects, we have integrated features extracted from a deep fingerprint verifier with the SRGAN quality discriminator. We also add ridge reconstruction loss, utilizing ridge patterns to make the best use of extracted features. Our proposed method solves the recognition problem by improving the quality of fingerprint images. High recognition accuracy of the synthesized samples that is close to the accuracy achieved using the original high-resolution images validate the effectiveness of our proposed model.
Efficient OCT Image Segmentation Using Neural Architecture Search
Jul 28, 2020



In this work, we propose a Neural Architecture Search (NAS) for retinal layer segmentation in Optical Coherence Tomography (OCT) scans. We incorporate the Unet architecture in the NAS framework as its backbone for the segmentation of the retinal layers in our collected and pre-processed OCT image dataset. At the pre-processing stage, we conduct super resolution and image processing techniques on the raw OCT scans to improve the quality of the raw images. For our search strategy, different primitive operations are suggested to find the down- & up-sampling cell blocks, and the binary gate method is applied to make the search strategy practical for the task in hand. We empirically evaluated our method on our in-house OCT dataset. The experimental results demonstrate that the self-adapting NAS-Unet architecture substantially outperformed the competitive human-designed architecture by achieving 95.4% in mean Intersection over Union metric and 78.7% in Dice similarity coefficient.
Attribute-Guided Coupled GAN for Cross-Resolution Face Recognition
Aug 05, 2019
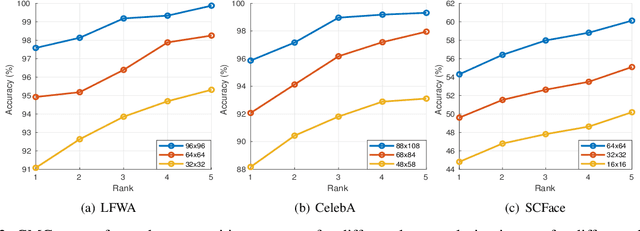

In this paper, we propose a novel attribute-guided cross-resolution (low-resolution to high-resolution) face recognition framework that leverages a coupled generative adversarial network (GAN) structure with adversarial training to find the hidden relationship between the low-resolution and high-resolution images in a latent common embedding subspace. The coupled GAN framework consists of two sub-networks, one dedicated to the low-resolution domain and the other dedicated to the high-resolution domain. Each sub-network aims to find a projection that maximizes the pair-wise correlation between the two feature domains in a common embedding subspace. In addition to projecting the images into a common subspace, the coupled network also predicts facial attributes to improve the cross-resolution face recognition. Specifically, our proposed coupled framework exploits facial attributes to further maximize the pair-wise correlation by implicitly matching facial attributes of the low and high-resolution images during the training, which leads to a more discriminative embedding subspace resulting in performance enhancement for cross-resolution face recognition. The efficacy of our approach compared with the state-of-the-art is demonstrated using the LFWA, Celeb-A, SCFace and UCCS datasets.