 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Flow Analysis Using Deep Neural Networks in Three-Phase Unbalanced Smart Distribution Grids
Jan 15, 2024



Most power systems' approaches are currently tending towards stochastic and probabilistic methods due to the high variability of renewable sources and the stochastic nature of loads. Conventional power flow (PF) approaches such as forward-backward sweep (FBS) and Newton-Raphson require a high number of iterations to solve non-linear PF equations making them computationally very intensive. PF is the most important study performed by utility, required in all stages of the power system, especially in operations and planning. This paper discusses the applications of deep learning (DL) to predict PF solutions for three-phase unbalanced power distribution grids. Three deep neural networks (DNNs); Radial Basis Function Network (RBFnet), Multi-Layer Perceptron (MLP), and Convolutional Neural Network (CNN), are proposed in this paper to predict PF solutions. The PF problem is formulated as a multi-output regression model where two or more output values are predicted based on the inputs. The training and testing data are generated through the OpenDSS-MATLAB COM interface. These methods are completely data-driven where the training relies on reducing the mismatch at each node without the need for the knowledge of the system. The novelty of the proposed methodology is that the models can accurately predict the PF solutions for the unbalanced distribution grids with mutual coupling and are robust to different R/X ratios, topology changes as well as generation and load variability introduced by the integration of distributed energy resources (DERs) and electric vehicles (EVs). To test the efficacy of the DNN models, they are applied to IEEE 4-node and 123-node test cases, and the American Electric Power (AEP) feeder model. The PF results for RBFnet, MLP, and CNN models are discussed in this paper demonstrating that all three DNN models provide highly accurate results in predicting PF solutions.
Empirical Assessment of End-to-End Iris Recognition System Capacity
Mar 20, 2023
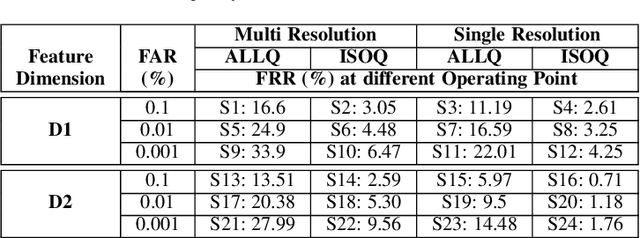

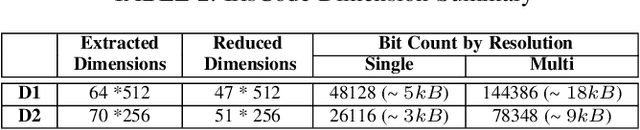
Iris is an established modality in biometric recognition applications including consumer electronics, e-commerce, border security, forensics, and de-duplication of identity at a national scale. In light of the expanding usage of biometric recognition, identity clash (when templates from two different people match) is an imperative factor of consideration for a system's deployment. This study explores system capacity estimation by empirically estimating the constrained capacity of an end-to-end iris recognition system (NIR systems with Daugman-based feature extraction) operating at an acceptable error rate i.e. the number of subjects a system can resolve before encountering an error. We study the impact of six system parameters on an iris recognition system's constrained capacity -- number of enrolled identities, image quality, template dimension, random feature elimination, filter resolution, and system operating point. In our assessment, we analyzed 13.2 million comparisons from 5158 unique identities for each of 24 different system configurations. This work provides a framework to better understand iris recognition system capacity as a function of biometric system configurations beyond the operating point, for large-scale applications.
Attribute-Based Deep Periocular Recognition: Leveraging Soft Biometrics to Improve Periocular Recognition
Nov 02, 2021


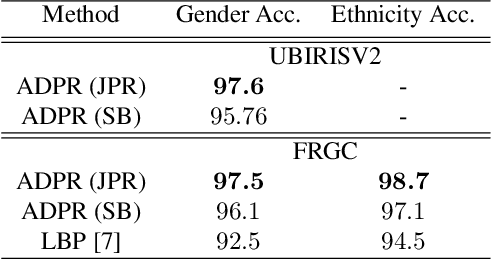
In recent years, periocular recognition has been developed as a valuable biometric identification approach, especially in wild environments (for example, masked faces due to COVID-19 pandemic) where facial recognition may not be applicable. This paper presents a new deep periocular recognition framework called attribute-based deep periocular recognition (ADPR), which predicts soft biometrics and incorporates the prediction into a periocular recognition algorithm to determine identity from periocular images with high accuracy. We propose an end-to-end framework, which uses several shared convolutional neural network (CNN)layers (a common network) whose output feeds two separate dedicated branches (modality dedicated layers); the first branch classifies periocular images while the second branch predicts softn biometrics. Next, the features from these two branches are fused together for a final periocular recognition. The proposed method is different from existing methods as it not only uses a shared CNN feature space to train these two tasks jointly, but it also fuses predicted soft biometric features with the periocular features in the training step to improve the overall periocular recognition performance. Our proposed model is extensively evaluated using four different publicly available datasets. Experimental results indicate that our soft biometric based periocular recognition approach outperforms other state-of-the-art methods for periocular recognition in wild environments.
Profile to Frontal Face Recognition in the Wild Using Coupled Conditional GAN
Jul 29, 2021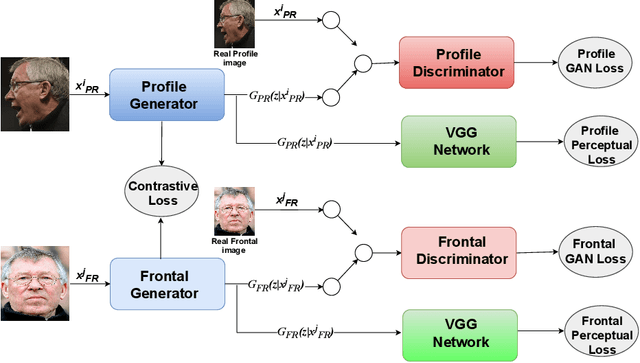
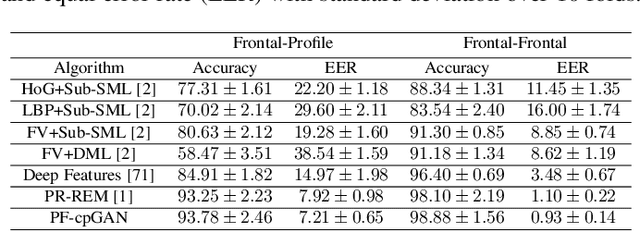
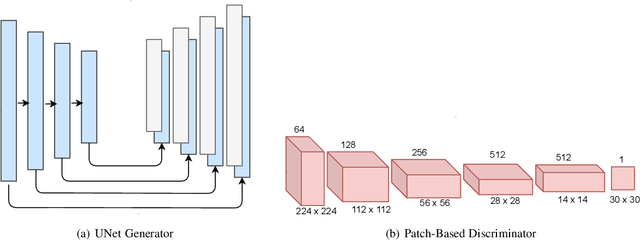
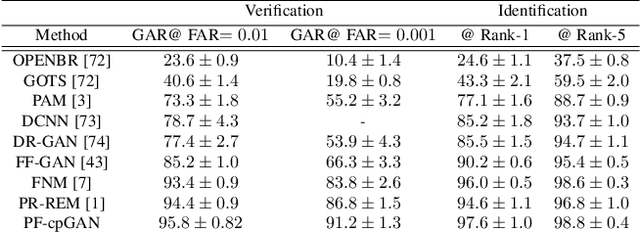
In recent years, with the advent of deep-learning, face recognition has achieved exceptional success. However, many of these deep face recognition models perform much better in handling frontal faces compared to profile faces. The major reason for poor performance in handling of profile faces is that it is inherently difficult to learn pose-invariant deep representations that are useful for profile face recognition. In this paper, we hypothesize that the profile face domain possesses a latent connection with the frontal face domain in a latent feature subspace. We look to exploit this latent connection by projecting the profile faces and frontal faces into a common latent subspace and perform verification or retrieval in the latent domain. We leverage a coupled conditional generative adversarial network (cpGAN) structure to find the hidden relationship between the profile and frontal images in a latent common embedding subspace. Specifically, the cpGAN framework consists of two conditional GAN-based sub-networks, one dedicated to the frontal domain and the other dedicated to the profile domain. Each sub-network tends to find a projection that maximizes the pair-wise correlation between the two feature domains in a common embedding feature subspace. The efficacy of our approach compared with the state-of-the-art is demonstrated using the CFP, CMU Multi-PIE, IJB-A, and IJB-C datasets. Additionally, we have also implemented a coupled convolutional neural network (cpCNN) and an adversarial discriminative domain adaptation network (ADDA) for profile to frontal face recognition. We have evaluated the performance of cpCNN and ADDA and compared it with the proposed cpGAN. Finally, we have also evaluated our cpGAN for reconstruction of frontal faces from input profile faces contained in the VGGFace2 dataset.
Deep Hashing for Secure Multimodal Biometrics
Dec 29, 2020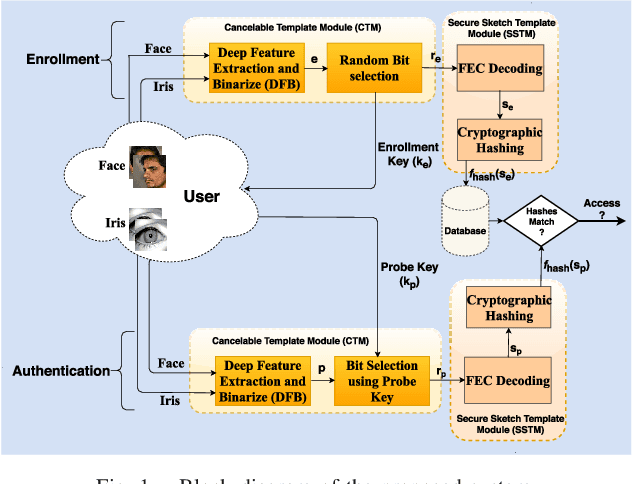
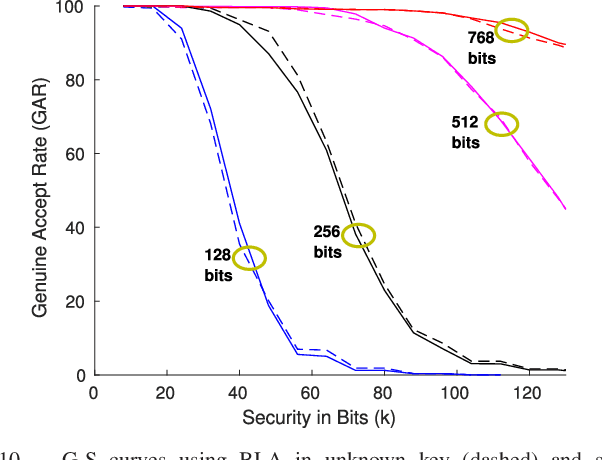
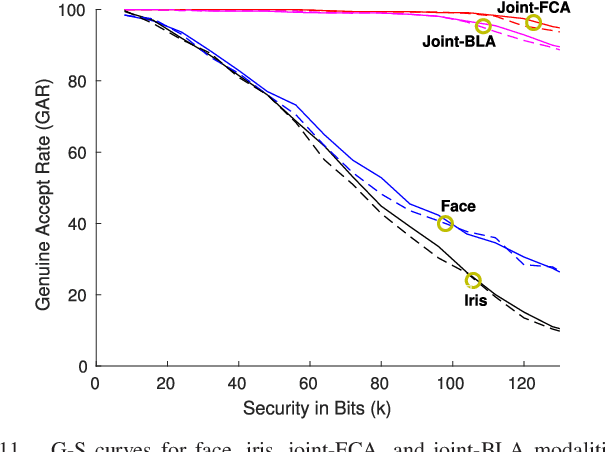
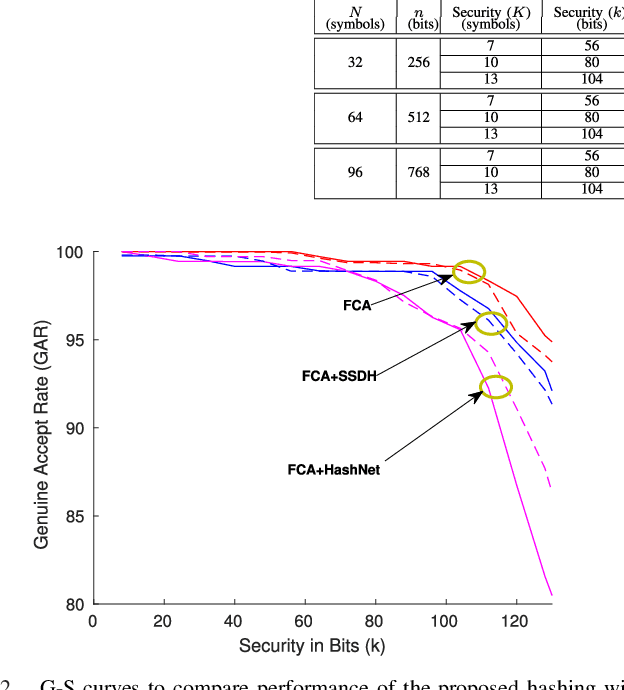
When compared to unimodal systems, multimodal biometric systems have several advantages, including lower error rate, higher accuracy, and larger population coverage. However, multimodal systems have an increased demand for integrity and privacy because they must store multiple biometric traits associated with each user. In this paper, we present a deep learning framework for feature-level fusion that generates a secure multimodal template from each user's face and iris biometrics. We integrate a deep hashing (binarization) technique into the fusion architecture to generate a robust binary multimodal shared latent representation. Further, we employ a hybrid secure architecture by combining cancelable biometrics with secure sketch techniques and integrate it with a deep hashing framework, which makes it computationally prohibitive to forge a combination of multiple biometrics that pass the authentication. The efficacy of the proposed approach is shown using a multimodal database of face and iris and it is observed that the matching performance is improved due to the fusion of multiple biometrics. Furthermore, the proposed approach also provides cancelability and unlinkability of the templates along with improved privacy of the biometric data. Additionally, we also test the proposed hashing function for an image retrieval application using a benchmark dataset. The main goal of this paper is to develop a method for integrating multimodal fusion, deep hashing, and biometric security, with an emphasis on structural data from modalities like face and iris. The proposed approach is in no way a general biometric security framework that can be applied to all biometric modalities, as further research is needed to extend the proposed framework to other unconstrained biometric modalities.
PF-cpGAN: Profile to Frontal Coupled GAN for Face Recognition in the Wild
Apr 25, 2020
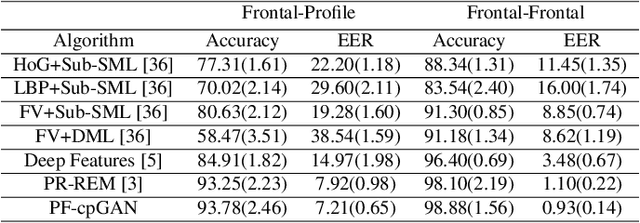
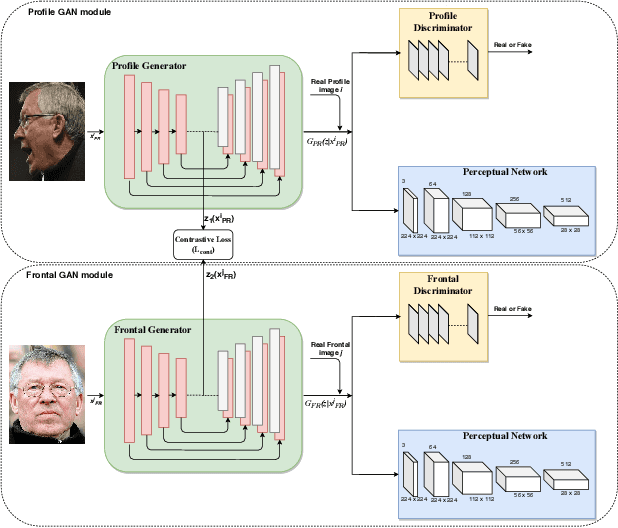
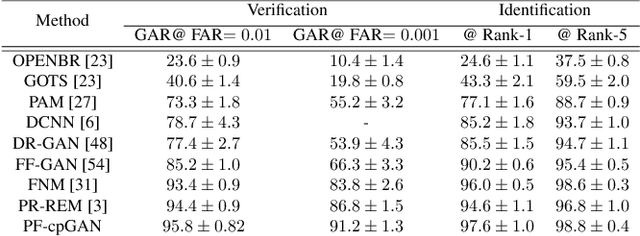
In recent years, due to the emergence of deep learning, face recognition has achieved exceptional success. However, many of these deep face recognition models perform relatively poorly in handling profile faces compared to frontal faces. The major reason for this poor performance is that it is inherently difficult to learn large pose invariant deep representations that are useful for profile face recognition. In this paper, we hypothesize that the profile face domain possesses a gradual connection with the frontal face domain in the deep feature space. We look to exploit this connection by projecting the profile faces and frontal faces into a common latent space and perform verification or retrieval in the latent domain. We leverage a coupled generative adversarial network (cpGAN) structure to find the hidden relationship between the profile and frontal images in a latent common embedding subspace. Specifically, the cpGAN framework consists of two GAN-based sub-networks, one dedicated to the frontal domain and the other dedicated to the profile domain. Each sub-network tends to find a projection that maximizes the pair-wise correlation between two feature domains in a common embedding feature subspace. The efficacy of our approach compared with the state-of-the-art is demonstrated using the CFP, CMU MultiPIE, IJB-A, and IJB-C datasets.
Error-Corrected Margin-Based Deep Cross-Modal Hashing for Facial Image Retrieval
Apr 03, 2020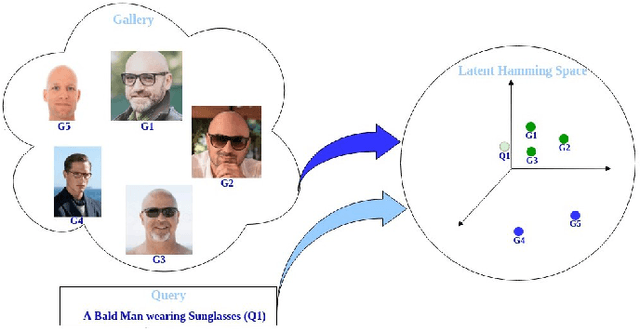
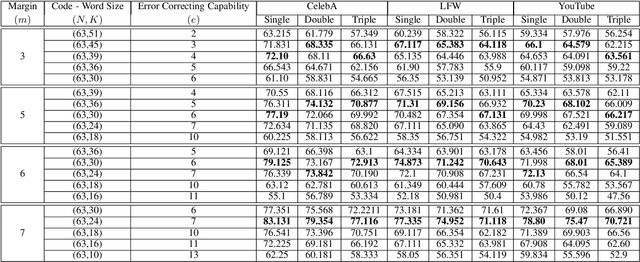
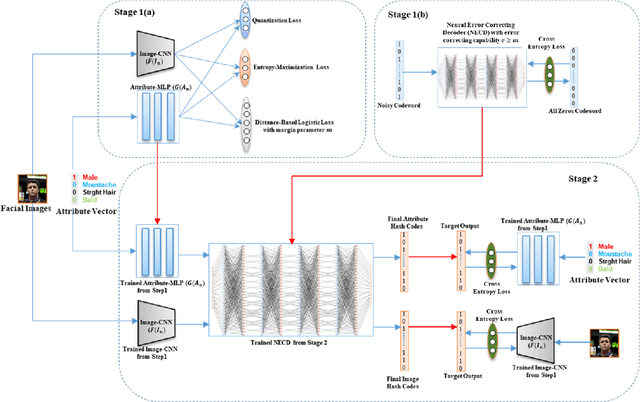
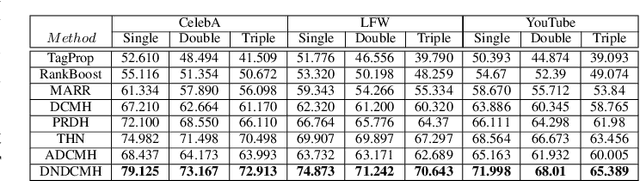
Cross-modal hashing facilitates mapping of heterogeneous multimedia data into a common Hamming space, which can beutilized for fast and flexible retrieval across different modalities. In this paper, we propose a novel cross-modal hashingarchitecture-deep neural decoder cross-modal hashing (DNDCMH), which uses a binary vector specifying the presence of certainfacial attributes as an input query to retrieve relevant face images from a database. The DNDCMH network consists of two separatecomponents: an attribute-based deep cross-modal hashing (ADCMH) module, which uses a margin (m)-based loss function toefficiently learn compact binary codes to preserve similarity between modalities in the Hamming space, and a neural error correctingdecoder (NECD), which is an error correcting decoder implemented with a neural network. The goal of NECD network in DNDCMH isto error correct the hash codes generated by ADCMH to improve the retrieval efficiency. The NECD network is trained such that it hasan error correcting capability greater than or equal to the margin (m) of the margin-based loss function. This results in NECD cancorrect the corrupted hash codes generated by ADCMH up to the Hamming distance of m. We have evaluated and comparedDNDCMH with state-of-the-art cross-modal hashing methods on standard datasets to demonstrate the superiority of our method.
Zero-Shot Deep Hashing and Neural Network Based Error Correction for Face Template Protection
Aug 05, 2019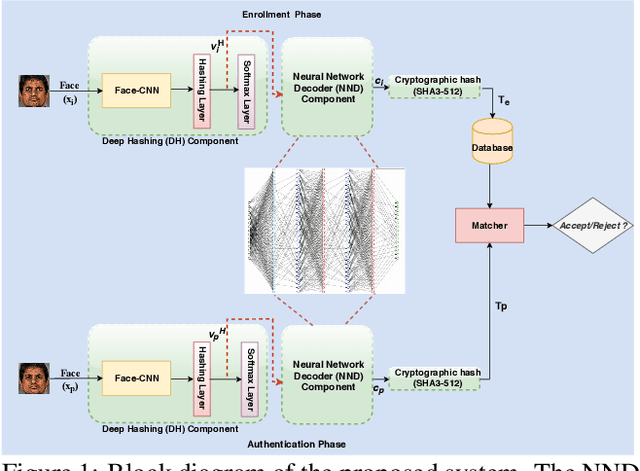


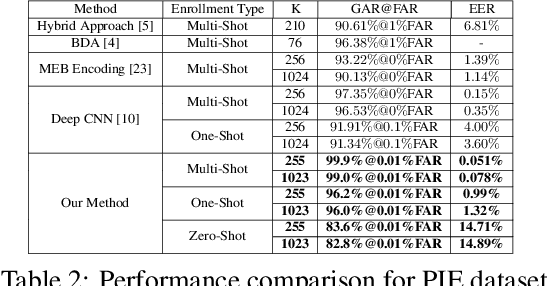
In this paper, we present a novel architecture that integrates a deep hashing framework with a neural network decoder (NND) for application to face template protection. It improves upon existing face template protection techniques to provide better matching performance with one-shot and multi-shot enrollment. A key novelty of our proposed architecture is that the framework can also be used with zero-shot enrollment. This implies that our architecture does not need to be re-trained even if a new subject is to be enrolled into the system. The proposed architecture consists of two major components: a deep hashing (DH) component, which is used for robust mapping of face images to their corresponding intermediate binary codes, and a NND component, which corrects errors in the intermediate binary codes that are caused by differences in the enrollment and probe biometrics due to factors such as variation in pose, illumination, and other factors. The final binary code generated by the NND is then cryptographically hashed and stored as a secure face template in the database. The efficacy of our approach with zero-shot, one-shot, and multi-shot enrollments is shown for CMU-PIE, Extended Yale B, WVU multimodal and Multi-PIE face databases. With zero-shot enrollment, the system achieves approximately 85% genuine accept rates (GAR) at 0.01% false accept rate (FAR), and with one-shot and multi-shot enrollments, it achieves approximately 99.95% GAR at 0.01% FAR, while providing a high level of template security.
Attribute-Guided Coupled GAN for Cross-Resolution Face Recognition
Aug 05, 2019
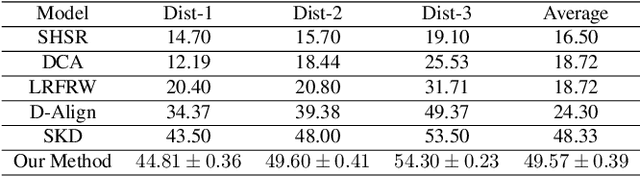
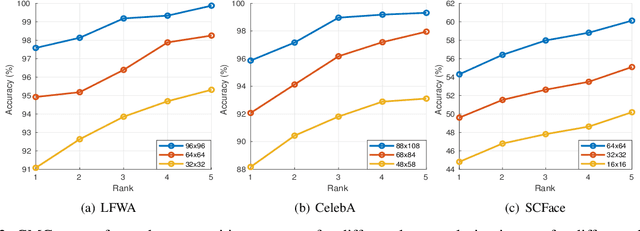

In this paper, we propose a novel attribute-guided cross-resolution (low-resolution to high-resolution) face recognition framework that leverages a coupled generative adversarial network (GAN) structure with adversarial training to find the hidden relationship between the low-resolution and high-resolution images in a latent common embedding subspace. The coupled GAN framework consists of two sub-networks, one dedicated to the low-resolution domain and the other dedicated to the high-resolution domain. Each sub-network aims to find a projection that maximizes the pair-wise correlation between the two feature domains in a common embedding subspace. In addition to projecting the images into a common subspace, the coupled network also predicts facial attributes to improve the cross-resolution face recognition. Specifically, our proposed coupled framework exploits facial attributes to further maximize the pair-wise correlation by implicitly matching facial attributes of the low and high-resolution images during the training, which leads to a more discriminative embedding subspace resulting in performance enhancement for cross-resolution face recognition. The efficacy of our approach compared with the state-of-the-art is demonstrated using the LFWA, Celeb-A, SCFace and UCCS datasets.
Learning to Authenticate with Deep Multibiometric Hashing and Neural Network Decoding
Mar 07, 2019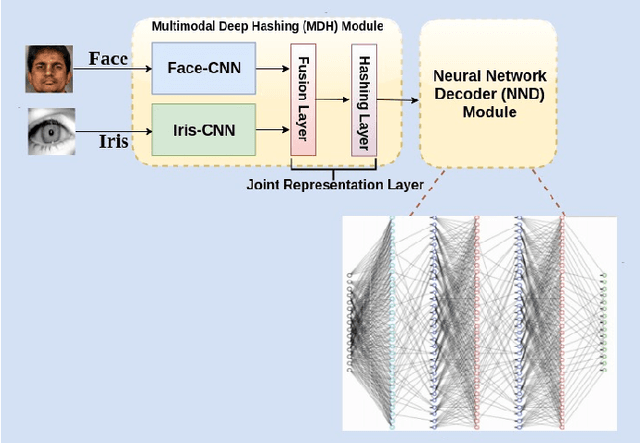
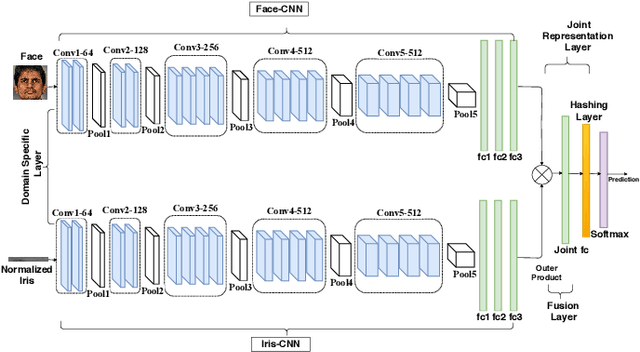
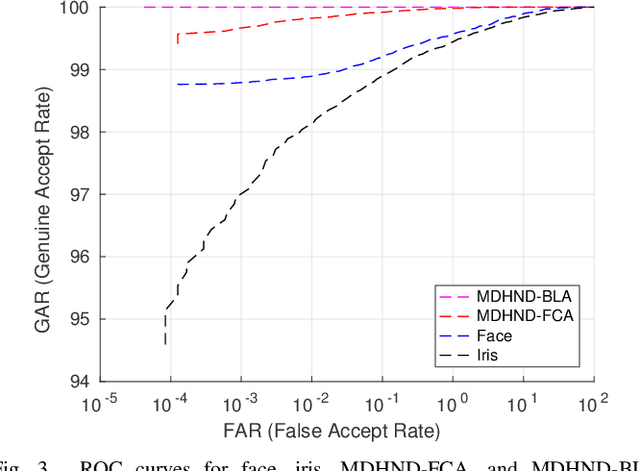
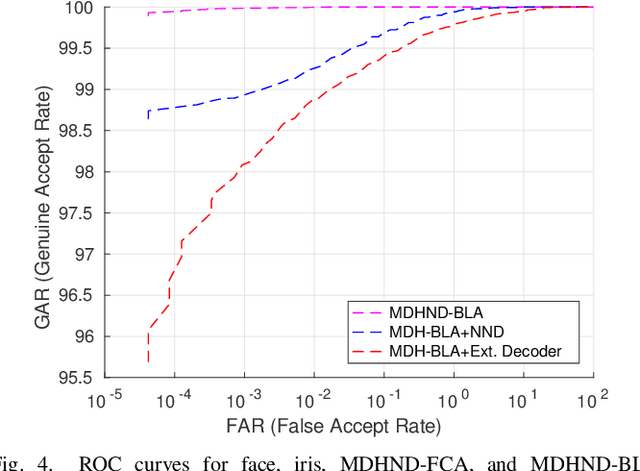
In this paper, we propose a novel multimodal deep hashing neural decoder (MDHND) architecture, which integrates a deep hashing framework with a neural network decoder (NND) to create an effective multibiometric authentication system. The MDHND consists of two separate modules: a multimodal deep hashing (MDH) module, which is used for feature-level fusion and binarization of multiple biometrics, and a neural network decoder (NND) module, which is used to refine the intermediate binary codes generated by the MDH and compensate for the difference between enrollment and probe biometrics (variations in pose, illumination, etc.). Use of NND helps to improve the performance of the overall multimodal authentication system. The MDHND framework is trained in 3 steps using joint optimization of the two modules. In Step 1, the MDH parameters are trained and learned to generate a shared multimodal latent code; in Step 2, the latent codes from Step 1 are passed through a conventional error-correcting code (ECC) decoder to generate the ground truth to train a neural network decoder (NND); in Step 3, the NND decoder is trained using the ground truth from Step 2 and the MDH and NND are jointly optimized. Experimental results on a standard multimodal dataset demonstrate the superiority of our method relative to other current multimodal authentication systems