 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Fluid Antenna Arrays: Continuous Position Design Beyond Classical DOF Limits
May 19, 2026Fluid antenna system (FAS), which continuously repositions a single physical element across a deployment region $[0, D]$, breaks this limit by freeing antenna positions from the discrete grid entirely. This paper establishes the theoretical foundations of sparse FAS design for direction-of-arrival (DOA) estimation and shows that continuous position freedom unlocks three compounding advantages over the classical designs. \emph{First}, we derive a universal dual DOF bound and prove that FAS-optimized positions can approach it, growing the DOF linearly with $D/λ$ , where $λ$ is the signal wavelength, rather than saturating at $O(N^2)$. \emph{Second}, the CRB scales as $O(1/D^{2L})$ for $L$ sources, a $(D/(N^2 d_0))^{2L}$ improvement over the best grid design, with $d_0 = λ/2$ and D-optimal positions admitting closed-form solution for single sources and efficient Frank-Wolfe algorithm for multiple sources. \emph{Third}, we propose a two-stage FAS-MUSIC approach that combines coarray MUSIC disambiguation with full-aperture local maximum likelihood (ML) refinement to track the CRB, overcoming the grating-lobe ambiguity inherent in large-aperture non-uniform arrays. Robustness to minimum spacing constraints, mutual coupling, and finite position accuracy is also analyzed. Extensive simulations show that FAS-MUSIC achieves $17.5\times$ lower root mean squared error (RMSE) than uniform linear array (ULA) MUSIC and that FAS with $4$ antennas outperforms MRA with $8$ antennas, gains that are unattainable by any grid-constrained design.
Hybrid Architecture Gets Fluid: A New Paradigm for Direction-of-arrival Estimation in 6G Networks
Apr 15, 2026High-precision direction-of-arrival (DOA) estimation, as a key sensing capability for 6G-enabled applications such as autonomous driving and extended reality, is increasingly dependent on the effective exploitation of spatial degrees of freedom (DOFs). This paper integrates two frontier DOFs-oriented paradigms and proposes a fluid antenna-enabled hybrid analog-digital (FA-HAD) architecture, which features an extremely lightweight front-end configuration mechanism and efficient spatial DOFs exploitation. Within this architecture, a collaborative spatial-phase sampling strategy is first developed to enable real-time 2-D DOA estimation under compressive observations, and a single-source CRLB analysis is provided to quantify the achievable performance limit, offering quantitative guidance for accuracy-overhead trade-offs. Furthermore, an efficient virtual-array spatial covariance matrix reconstruction method is proposed to recover a physically meaningful covariance representation, thereby providing a covariance-domain interface that is directly reusable by a broad class of existing covariance-based array processing and array design techniques, which strengthens the scalability and transferability of the proposed architecture. Building upon the reconstructed SCM, a Jacobi-Anger expansion based dimension-reduced MUSIC estimator is further derived for arbitrary planar arrays with a favorable computational cost. Simulation results demonstrate that the proposed FA-HAD framework attains DOA accuracy close to fully digital systems while substantially reducing RF hardware complexity and training overhead.
Fundamental Analysis of Scalable Fluid Antenna Systems: Identifiability Limits, Information Theory, and Joint Processing
Apr 01, 2026Unlike fixed-position arrays with static observation entropy, the scalable fluid antenna system (S-FAS) can dynamically adjust its aperture to form different observation spaces with configuration-dependent entropy budgets. This reconfigurability requires an information-theoretic framework beyond traditional algebraic identifiability analysis. This paper establishes an observation entropy framework for S-FAS, which unifies the derivation of identifiability limits, the diagnosis of processing bottlenecks, and system design optimization. For an S-FAS with mutual coupling suppression, we derive a complete capacity hierarchy among compressed, extended, and jointly stacked configurations. The entropy framework reveals that sequential two-stage processing suffers from an information bottleneck that restricts achievable capacity, while the noise entropy ratio can be used to distinguish fundamental performance limits from algorithmic deficiencies. A joint MUSIC algorithm is proposed to approach the theoretical joint capacity bound. Extensive Monte Carlo simulations, validated by both algebraic and information-theoretic criteria, verify the derived capacity hierarchy and identifiability boundaries.
Beyond $λ/2$: Can Arbitrary EMVS Arrays Achieve Unambiguous NLOS Localization?
Feb 07, 2026Conventional radar array design mandates interelement spacing not exceeding half a wavelength ($λ/2$) to avoid spatial ambiguity, fundamentally limiting array aperture and angular resolution. This paper addresses the fundamental question: Can arbitrary electromagnetic vector sensor (EMVS) arrays achieve unambiguous reconfigurable intelligent surface (RIS)-aided localization when element spacing exceeds $λ/2$? We provide an affirmative answer by exploiting the multi-component structure of EMVS measurements and developing a synergistic estimation and optimization framework for non-line-of-sight (NLOS) bistatic multiple input multiple output (MIMO) radar. A third-order parallel factor (PARAFAC) model is constructed from EMVS observations, enabling natural separation of spatial, polarimetric, and propagation effects via the trilinear alternating least squares (TALS) algorithm. A novel phase-disambiguation procedure leverages rotational invariance across the six electromagnetic components of EMVSs to resolve $2π$ phase wrapping in arbitrary array geometries, allowing unambiguous joint estimation of two-dimensional (2-D) direction of departure (DOD), two-dimensional direction of arrival (DOA), and polarization parameters with automatic pairing. To support localization in NLOS environments and enhance estimation robustness, a reconfigurable intelligent surface (RIS) is incorporated and its phase shifts are optimized via semidefinite programming (SDP) relaxation to maximize received signal power, improving signal-to-noise ratio (SNR) and further suppressing spatial ambiguities through iterative refinement.
FAS-RIS for V2X: Unlocking Realistic Performance Analysis with Finite Elements
Dec 22, 2025The synergy of fluid antenna systems (FAS) and reconfigurable intelligent surfaces (RIS) is poised to unlock robust Vehicle-to-Everything (V2X) communications. However, a critical gap persists between theoretical predictions and real-world performance. Existing analyses predominantly rely on the Central Limit Theorem (CLT), an assumption valid only for a large number of RIS elements, which fails to represent practical, finite-sized deployments constrained by cost and urban infrastructure. This paper bridges this gap by presenting a novel framework that unlocks a realistic performance analysis for FAS-RIS systems with finite elements. Leveraging a Gamma distribution approximation, we derive a new, tractable closed-form expression for the outage probability. Numerical results validate our approach, demonstrating that it offers a significantly more accurate performance characterization than conventional CLT-based methods, particularly in the practical regime of small-scale RIS. This work provides a crucial foundation for the design and deployment of reliable FAS-RIS-aided vehicular networks.
Reimagining Wireless Connectivity: The FAS-RIS Synergy for 6G Smart Cities
Dec 22, 2025Fluid antenna system (FAS) represents the concept of treating antenna as a reconfigurable physical-layer resource to broaden system design and network optimization and inspire next-generation reconfigurable antennas. FAS can unleash new degree of freedom (DoF) via antenna reconfigurations for novel spatial diversity. Reconfigurable intelligent surfaces (RISs) on the other hand can reshape wireless propagation environments but often face limitations from double path-loss and minimal signal processing capability when operating independently. This article envisions a transformative FAS-RIS integrated architecture for future smart city networks, uniting the adaptability of FAS with the environmental control of RIS. The proposed framework has five key applications: FAS-enabled base stations (BSs) for large-scale beamforming, FAS-equipped user devices with finest spatial diversity, and three novel RIS paradigms -- fluid RIS (FRIS) with reconfigurable elements, FAS-embedded RIS as active relays, and enormous FAS (E-FAS) exploiting surface waves on facades to re-establish line-of-sight (LoS) communication. A two-timescale control mechanism coordinates network-level beamforming with rapid, device-level adaptation. Applications spanning from simultaneous wireless information and power transfer (SWIPT) to integrated sensing and communications (ISAC), with challenges in co-design, channel modeling, and optimization, are discussed. This article concludes with simulation results demonstrating the robustness and effectiveness of the FAS-RIS system.
A Hybrid Dynamic Subarray Architecture for Efficient DOA Estimation in THz Ultra-Massive Hybrid MIMO Systems
Jan 30, 2025Terahertz (THz) communication combined with ultra-massive multiple-input multiple-output (UM-MIMO) technology is promising for 6G wireless systems, where fast and precise direction-of-arrival (DOA) estimation is crucial for effective beamforming. However, finding DOAs in THz UM-MIMO systems faces significant challenges: while reducing hardware complexity, the hybrid analog-digital (HAD) architecture introduces inherent difficulties in spatial information acquisition the large-scale antenna array causes significant deviations in eigenvalue decomposition results; and conventional two-dimensional DOA estimation methods incur prohibitively high computational overhead, hindering fast and accurate realization. To address these challenges, we propose a hybrid dynamic subarray (HDS) architecture that strategically divides antenna elements into subarrays, ensuring phase differences between subarrays correlate exclusively with single-dimensional DOAs. Leveraging this architectural innovation, we develop two efficient algorithms for DOA estimation: a reduced-dimension MUSIC (RD-MUSIC) algorithm that enables fast processing by correcting large-scale array estimation bias, and an improved version that further accelerates estimation by exploiting THz channel sparsity to obtain initial closed-form solutions through specialized two-RF-chain configuration. Furthermore, we develop a theoretical framework through Cram\'{e}r-Rao lower bound analysis, providing fundamental insights for different HDS configurations. Extensive simulations demonstrate that our solution achieves both superior estimation accuracy and computational efficiency, making it particularly suitable for practical THz UM-MIMO systems.
Uniqueness of Iris Pattern Based on AR Model
Jun 21, 2023



The assessment of iris uniqueness plays a crucial role in analyzing the capabilities and limitations of iris recognition systems. Among the various methodologies proposed, Daugman's approach to iris uniqueness stands out as one of the most widely accepted. According to Daugman, uniqueness refers to the iris recognition system's ability to enroll an increasing number of classes while maintaining a near-zero probability of collision between new and enrolled classes. Daugman's approach involves creating distinct IrisCode templates for each iris class within the system and evaluating the sustainable population under a fixed Hamming distance between codewords. In our previous work [23], we utilized Rate-Distortion Theory (as it pertains to the limits of error-correction codes) to establish boundaries for the maximum possible population of iris classes supported by Daugman's IrisCode, given the constraint of a fixed Hamming distance between codewords. Building upon that research, we propose a novel methodology to evaluate the scalability of an iris recognition system, while also measuring iris quality. We achieve this by employing a sphere-packing bound for Gaussian codewords and adopting a approach similar to Daugman's, which utilizes relative entropy as a distance measure between iris classes. To demonstrate the efficacy of our methodology, we illustrate its application on two small datasets of iris images. We determine the sustainable maximum population for each dataset based on the quality of the images. By providing these illustrations, we aim to assist researchers in comprehending the limitations inherent in their recognition systems, depending on the quality of their iris databases.
Air-Aided Communication Between Ground Assets in a Poisson Forest
Nov 19, 2022
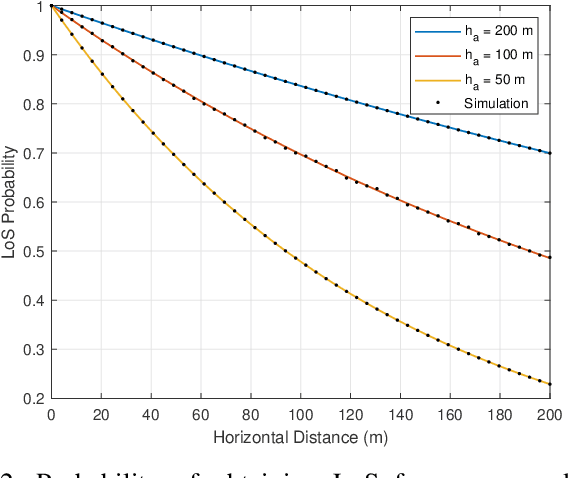
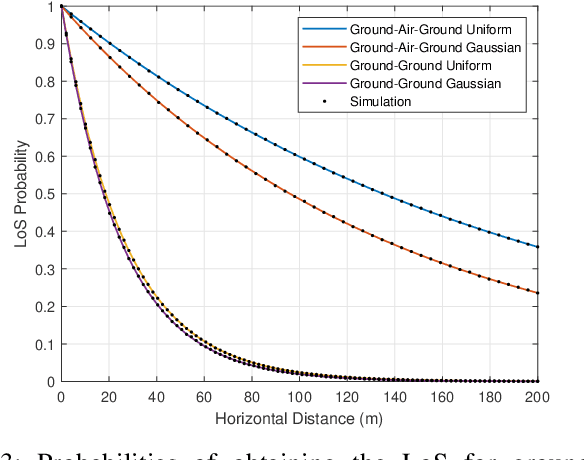
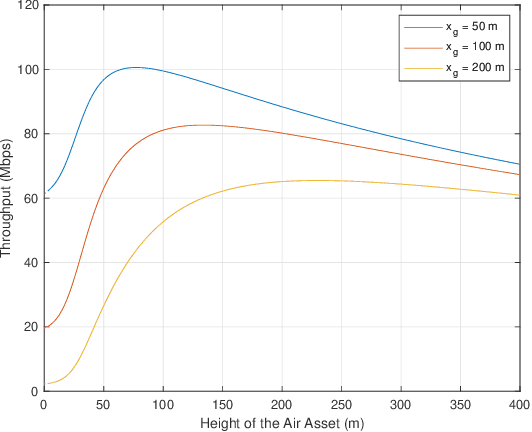
Ground assets deployed in a cluttered environment with randomized obstacles (e.g., a forest) may experience line of sight (LoS) obstruction due to those obstacles. Air assets can be deployed in the vicinity to aid the communication by establishing two-hop paths between the ground assets. Obstacles that are taller than a position-dependent critical height may still obstruct the LoS between a ground asset and an air asset. In this paper, we provide an analytical framework for computing the probability of obtaining a LoS path in a Poisson forest. Given the locations and heights of a ground asset and an air asset, we establish the critical height, which is a function of distance. To account for this dependence on distance, the blocking is modeled as an inhomogenous Poisson point process, and the LoS probability is its void probability. Examples and closed-form expressions are provided for two obstruction height distributions: uniform and truncated Gaussian. The examples are validated through simulation. Additionally, the end-to-end throughput is determined and shown to be a metric that balances communication distance with the impact of LoS blockage. Throughput is used to determine the range at which it is better to relay communications through the air asset, and, when the air asset is deployed, its optimal height.
Attribute-Based Deep Periocular Recognition: Leveraging Soft Biometrics to Improve Periocular Recognition
Nov 02, 2021


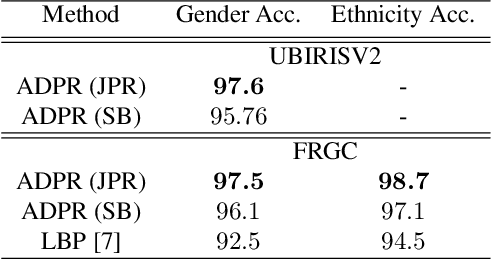
In recent years, periocular recognition has been developed as a valuable biometric identification approach, especially in wild environments (for example, masked faces due to COVID-19 pandemic) where facial recognition may not be applicable. This paper presents a new deep periocular recognition framework called attribute-based deep periocular recognition (ADPR), which predicts soft biometrics and incorporates the prediction into a periocular recognition algorithm to determine identity from periocular images with high accuracy. We propose an end-to-end framework, which uses several shared convolutional neural network (CNN)layers (a common network) whose output feeds two separate dedicated branches (modality dedicated layers); the first branch classifies periocular images while the second branch predicts softn biometrics. Next, the features from these two branches are fused together for a final periocular recognition. The proposed method is different from existing methods as it not only uses a shared CNN feature space to train these two tasks jointly, but it also fuses predicted soft biometric features with the periocular features in the training step to improve the overall periocular recognition performance. Our proposed model is extensively evaluated using four different publicly available datasets. Experimental results indicate that our soft biometric based periocular recognition approach outperforms other state-of-the-art methods for periocular recognition in wild environments.