 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Longitudinal Performance Degradation in Child Face Recognition Using Synthetic Data
Jan 04, 2026Longitudinal face recognition in children remains challenging due to rapid and nonlinear facial growth, which causes template drift and increasing verification errors over time. This work investigates whether synthetic face data can act as a longitudinal stabilizer by improving temporal robustness of child face recognition models. Using an identity disjoint protocol on the Young Face Aging (YFA) dataset, we evaluate three settings: (i) pretrained MagFace embeddings without dataset specific fine-tuning, (ii) MagFace fine-tuned using authentic training faces only, and (iii) MagFace fine-tuned using a combination of authentic and synthetically generated training faces. Synthetic data is generated using StyleGAN2 ADA and incorporated exclusively within the training identities; a post generation filtering step is applied to mitigate identity leakage and remove artifact affected samples. Experimental results across enrollment verification gaps from 6 to 36 months show that synthetic-augmented fine tuning substantially reduces error rates relative to both the pretrained baseline and real only fine tuning. These findings provide a risk aware assessment of synthetic augmentation for improving identity persistence in pediatric face recognition.
Evaluating Deep Learning-Based Face Recognition for Infants and Toddlers: Impact of Age Across Developmental Stages
Jan 04, 2026Face recognition for infants and toddlers presents unique challenges due to rapid facial morphology changes, high inter-class similarity, and limited dataset availability. This study evaluates the performance of four deep learning-based face recognition models FaceNet, ArcFace, MagFace, and CosFace on a newly developed longitudinal dataset collected over a 24 month period in seven sessions involving children aged 0 to 3 years. Our analysis examines recognition accuracy across developmental stages, showing that the True Accept Rate (TAR) is only 30.7% at 0.1% False Accept Rate (FAR) for infants aged 0 to 6 months, due to unstable facial features. Performance improves significantly in older children, reaching 64.7% TAR at 0.1% FAR in the 2.5 to 3 year age group. We also evaluate verification performance over different time intervals, revealing that shorter time gaps result in higher accuracy due to reduced embedding drift. To mitigate this drift, we apply a Domain Adversarial Neural Network (DANN) approach that improves TAR by over 12%, yielding features that are more temporally stable and generalizable. These findings are critical for building biometric systems that function reliably over time in smart city applications such as public healthcare, child safety, and digital identity services. The challenges observed in early age groups highlight the importance of future research on privacy preserving biometric authentication systems that can address temporal variability, particularly in secure and regulated urban environments where child verification is essential.
An Open-Source Framework for Quality-Assured Smartphone-Based Visible Light Iris Recognition
Dec 17, 2025
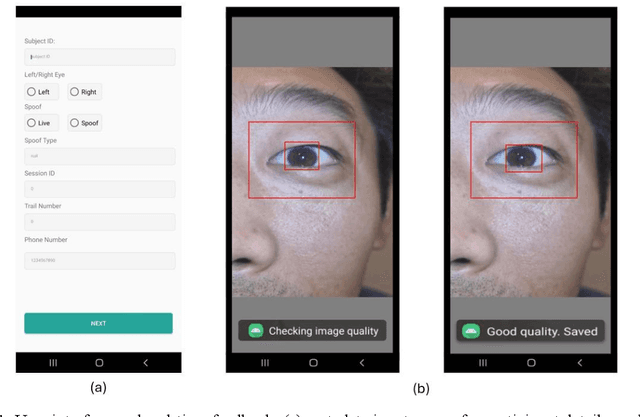
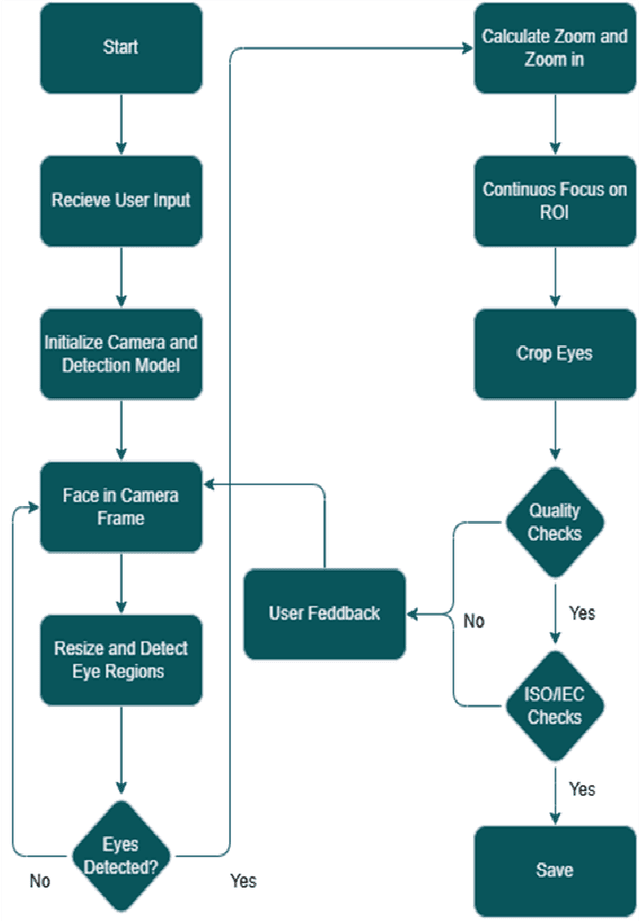

Smartphone-based iris recognition in the visible spectrum (VIS) offers a low-cost and accessible biometric alternative but remains a challenge due to lighting variability, pigmentation effects, and the limited adoption of standardized capture protocols. In this work, we present CUVIRIS, a dataset of 752 ISO/IEC 29794-6 compliant iris images from 47 subjects, collected with a custom Android application that enforces real-time framing, sharpness assessment, and quality feedback. We further introduce LightIrisNet, a MobileNetV3-based multi-task segmentation model optimized for on-device deployment. In addition, we adapt IrisFormer, a transformer-based matcher, to the VIS domain. We evaluate OSIRIS and IrisFormer under a standardized protocol and benchmark against published CNN baselines reported in prior work. On CUVIRIS, the open-source OSIRIS system achieves a TAR of 97.9% at FAR = 0.01 (EER = 0.76%), while IrisFormer, trained only on the UBIRIS.v2 dataset, achieves an EER of 0.057\%. To support reproducibility, we release the Android application, LightIrisNet, trained IrisFormer weights, and a subset of the CUVIRIS dataset. These results show that, with standardized acquisition and VIS-adapted lightweight models, accurate iris recognition on commodity smartphones is feasible under controlled conditions, bringing this modality closer to practical deployment.
Nine Years of Pediatric Iris Recognition: Evidence for Biometric Permanence
Dec 17, 2025Biometric permanence in pediatric populations remains poorly understood despite widespread deployment of iris recognition for children in national identity programs such as India's Aadhaar and trusted traveler programs like Canada's NEXUS. This study presents a comprehensive longitudinal evaluation of pediatric iris recognition, analyzing 276 subjects enrolled between ages 4-12 and followed up to nine years through adolescence. Using 18,318 near-infrared iris images acquired semi-annually, we evaluated commercial (VeriEye) and open-source (OpenIris) systems through linear mixed-effects models that disentangle enrollment age, developmental maturation, and elapsed time while controlling for image quality and physiological factors. False non-match rates remained below 0.5% across the nine-year period for both matchers using pediatric-calibrated thresholds, approaching adult-level performance. However, we reveal significant algorithm-dependent temporal behaviors: VeriEye's apparent decline reflects developmental confounding across enrollment cohorts rather than genuine template aging, while OpenIris exhibits modest but genuine temporal aging (0.5 standard deviations over eight years). Image quality and pupil dilation constancy dominated longitudinal performance, with dilation effects reaching 3.0-3.5 standard deviations, substantially exceeding temporal factors. Failures concentrated in 9.4% of subjects with persistent acquisition challenges rather than accumulating with elapsed time, confirming acquisition conditions as the primary limitation. These findings justify extending conservative re-enrollment policies, potentially to 10-12 year validity periods for high-quality enrollments at ages 7+, and demonstrate iris recognition remains viable throughout childhood and adolescence with proper imaging control.
A Comparative Evaluation of Deep Learning Models for Speech Enhancement in Real-World Noisy Environments
Jun 17, 2025
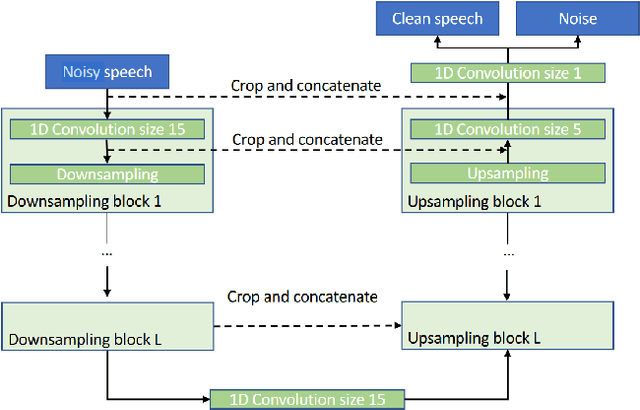

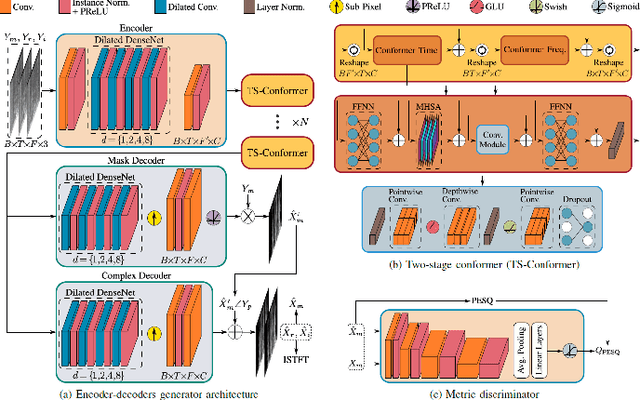
Speech enhancement, particularly denoising, is vital in improving the intelligibility and quality of speech signals for real-world applications, especially in noisy environments. While prior research has introduced various deep learning models for this purpose, many struggle to balance noise suppression, perceptual quality, and speaker-specific feature preservation, leaving a critical research gap in their comparative performance evaluation. This study benchmarks three state-of-the-art models Wave-U-Net, CMGAN, and U-Net, on diverse datasets such as SpEAR, VPQAD, and Clarkson datasets. These models were chosen due to their relevance in the literature and code accessibility. The evaluation reveals that U-Net achieves high noise suppression with SNR improvements of +71.96% on SpEAR, +64.83% on VPQAD, and +364.2% on the Clarkson dataset. CMGAN outperforms in perceptual quality, attaining the highest PESQ scores of 4.04 on SpEAR and 1.46 on VPQAD, making it well-suited for applications prioritizing natural and intelligible speech. Wave-U-Net balances these attributes with improvements in speaker-specific feature retention, evidenced by VeriSpeak score gains of +10.84% on SpEAR and +27.38% on VPQAD. This research indicates how advanced methods can optimize trade-offs between noise suppression, perceptual quality, and speaker recognition. The findings may contribute to advancing voice biometrics, forensic audio analysis, telecommunication, and speaker verification in challenging acoustic conditions.
OcularAge: A Comparative Study of Iris and Periocular Images for Pediatric Age Estimation
May 08, 2025


Estimating a child's age from ocular biometric images is challenging due to subtle physiological changes and the limited availability of longitudinal datasets. Although most biometric age estimation studies have focused on facial features and adult subjects, pediatric-specific analysis, particularly of the iris and periocular regions, remains relatively unexplored. This study presents a comparative evaluation of iris and periocular images for estimating the ages of children aged between 4 and 16 years. We utilized a longitudinal dataset comprising more than 21,000 near-infrared (NIR) images, collected from 288 pediatric subjects over eight years using two different imaging sensors. A multi-task deep learning framework was employed to jointly perform age prediction and age-group classification, enabling a systematic exploration of how different convolutional neural network (CNN) architectures, particularly those adapted for non-square ocular inputs, capture the complex variability inherent in pediatric eye images. The results show that periocular models consistently outperform iris-based models, achieving a mean absolute error (MAE) of 1.33 years and an age-group classification accuracy of 83.82%. These results mark the first demonstration that reliable age estimation is feasible from children's ocular images, enabling privacy-preserving age checks in child-centric applications. This work establishes the first longitudinal benchmark for pediatric ocular age estimation, providing a foundation for designing robust, child-focused biometric systems. The developed models proved resilient across different imaging sensors, confirming their potential for real-world deployment. They also achieved inference speeds of less than 10 milliseconds per image on resource-constrained VR headsets, demonstrating their suitability for real-time applications.
Smartphone-based Iris Recognition through High-Quality Visible Spectrum Iris Capture
Dec 17, 2024
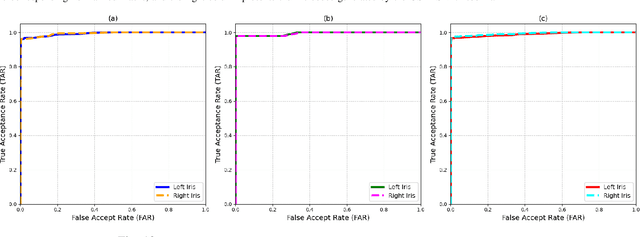
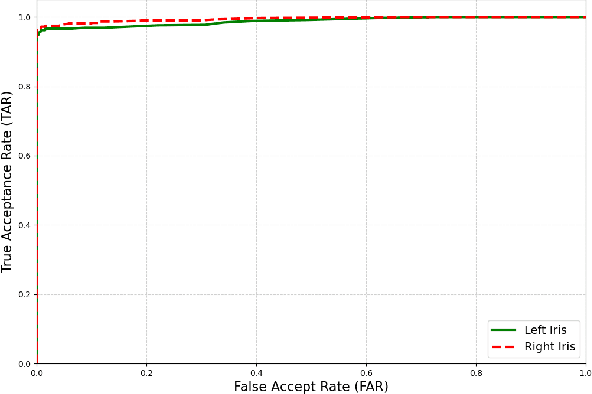
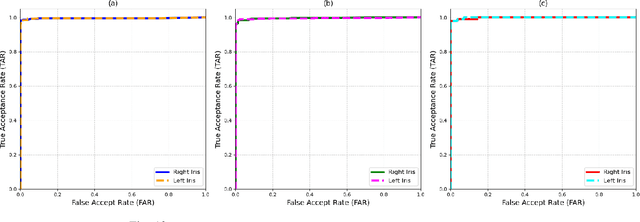
Iris recognition is widely acknowledged for its exceptional accuracy in biometric authentication, traditionally relying on near-infrared (NIR) imaging. Recently, visible spectrum (VIS) imaging via accessible smartphone cameras has been explored for biometric capture. However, a thorough study of iris recognition using smartphone-captured 'High-Quality' VIS images and cross-spectral matching with previously enrolled NIR images has not been conducted. The primary challenge lies in capturing high-quality biometrics, a known limitation of smartphone cameras. This study introduces a novel Android application designed to consistently capture high-quality VIS iris images through automated focus and zoom adjustments. The application integrates a YOLOv3-tiny model for precise eye and iris detection and a lightweight Ghost-Attention U-Net (G-ATTU-Net) for segmentation, while adhering to ISO/IEC 29794-6 standards for image quality. The approach was validated using smartphone-captured VIS and NIR iris images from 47 subjects, achieving a True Acceptance Rate (TAR) of 96.57% for VIS images and 97.95% for NIR images, with consistent performance across various capture distances and iris colors. This robust solution is expected to significantly advance the field of iris biometrics, with important implications for enhancing smartphone security.
Post-Mortem Human Iris Segmentation Analysis with Deep Learning
Aug 06, 2024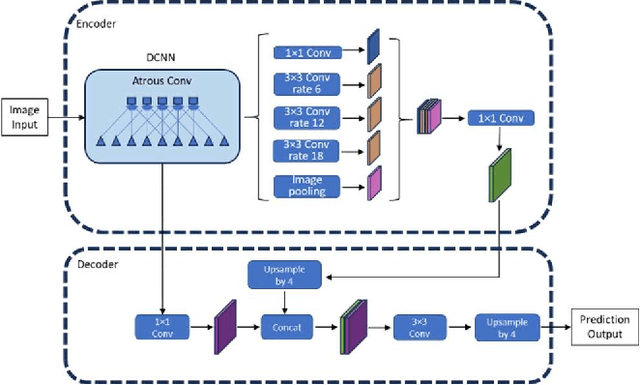
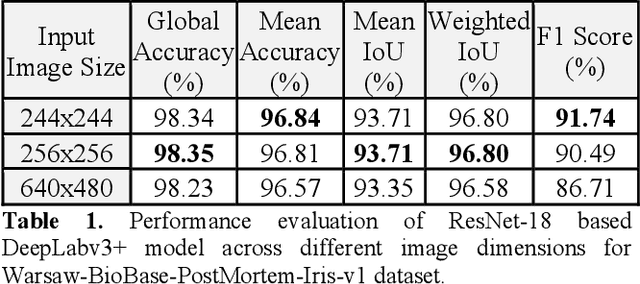
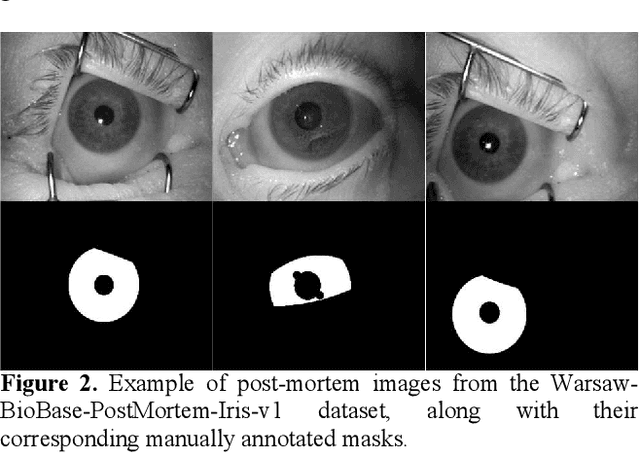
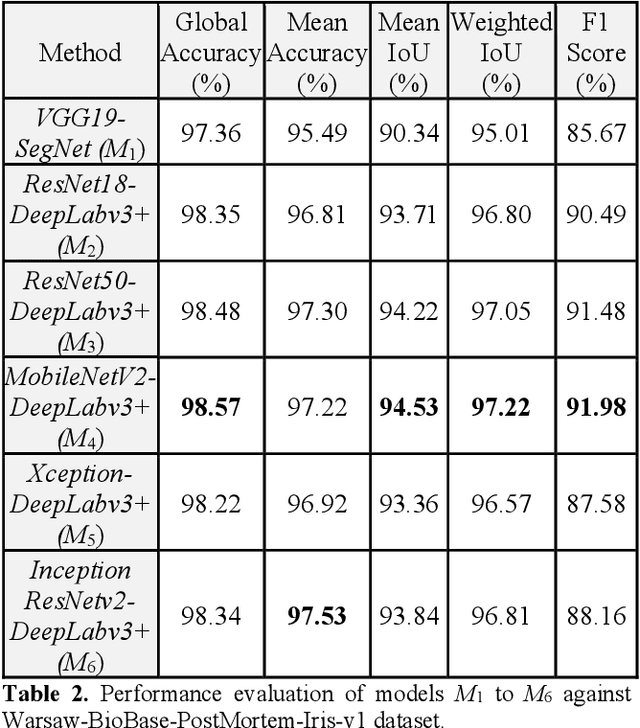
Iris recognition is widely used in several fields such as mobile phones, financial transactions, identification cards, airport security, international border control, voter registration for living persons. However, the possibility of identifying deceased individuals based on their iris patterns has emerged recently as a supplementary or alternative method valuable in forensic analysis. Simultaneously, it poses numerous new technological challenges and one of the most challenging among them is the image segmentation stage as conventional iris recognition approaches have struggled to reliably execute it. This paper presents and compares Deep Learning (DL) models designed for segmenting iris images collected from the deceased subjects, by training SegNet and DeepLabV3+ semantic segmentation methods where using VGG19, ResNet18, ResNet50, MobileNetv2, Xception, or InceptionResNetv2 as backbones. In this study, our experiments demonstrate that our proposed method effectively learns and identifies specific deformations inherent in post-mortem samples and providing a significant improvement in accuracy. By employing our novel method MobileNetv2 as the backbone of DeepLabV3+ and replacing the final layer with a hybrid loss function combining Boundary and Dice loss, we achieve Mean Intersection over Union of 95.54% on the Warsaw-BioBase-PostMortem-Iris-v1 dataset. To the best of our knowledge, this study provides the most extensive evaluation of DL models for post-mortem iris segmentation.
Deep Learning Approach for Ear Recognition and Longitudinal Evaluation in Children
Aug 02, 2024



Ear recognition as a biometric modality is becoming increasingly popular, with promising broader application areas. While current applications involve adults, one of the challenges in ear recognition for children is the rapid structural changes in the ear as they age. This work introduces a foundational longitudinal dataset collected from children aged 4 to 14 years over a 2.5-year period and evaluates ear recognition performance in this demographic. We present a deep learning based approach for ear recognition, using an ensemble of VGG16 and MobileNet, focusing on both adult and child datasets, with an emphasis on longitudinal evaluation for children.
Longitudinal Evaluation of Child Face Recognition and the Impact of Underlying Age
Aug 01, 2024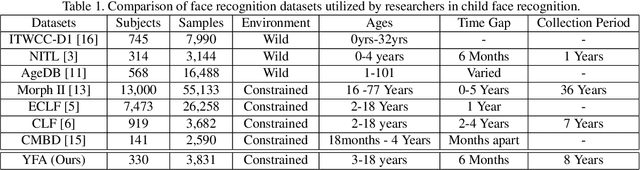
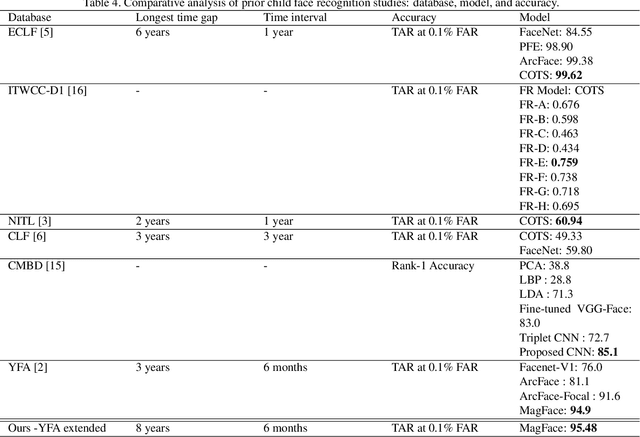
The need for reliable identification of children in various emerging applications has sparked interest in leveraging child face recognition technology. This study introduces a longitudinal approach to enrollment and verification accuracy for child face recognition, focusing on the YFA database collected by Clarkson University CITeR research group over an 8 year period, at 6 month intervals.