 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-Source Framework for Quality-Assured Smartphone-Based Visible Light Iris Recognition
Dec 17, 2025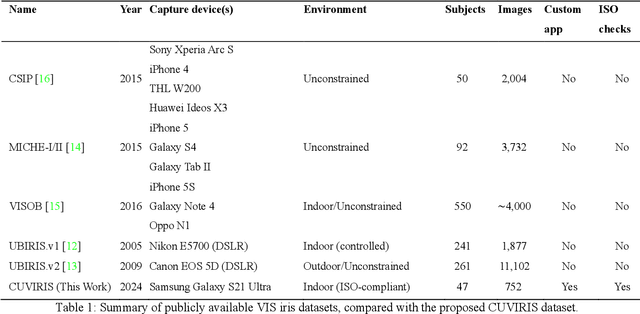
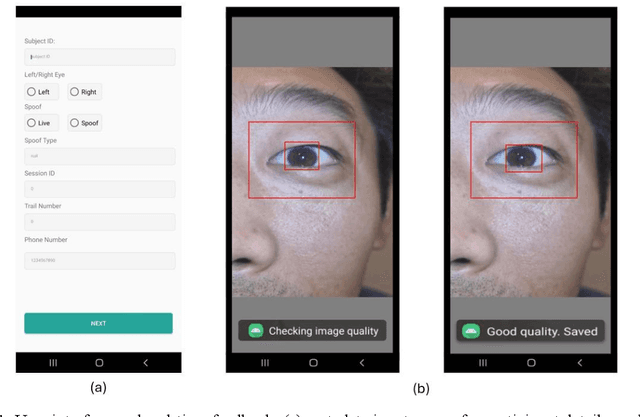
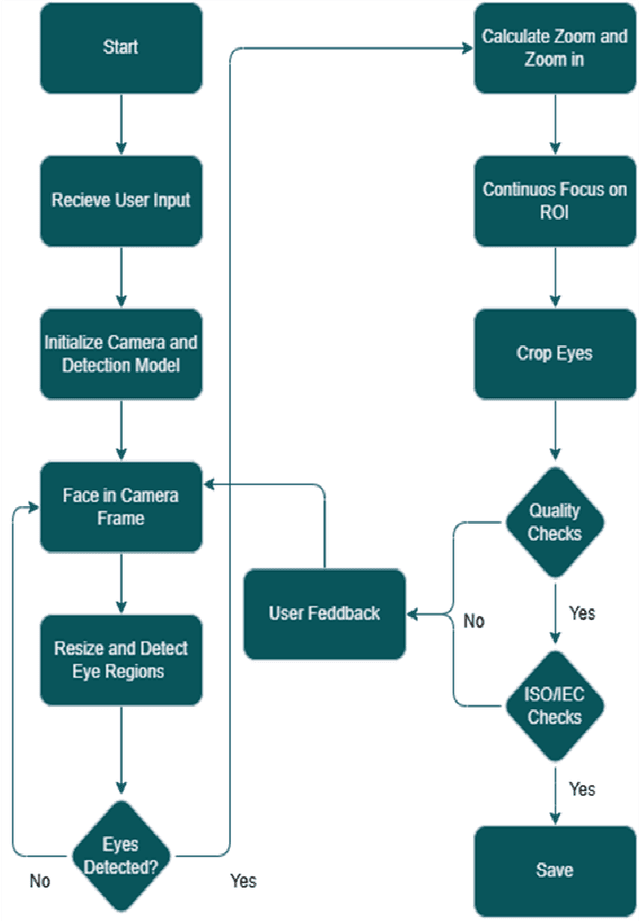

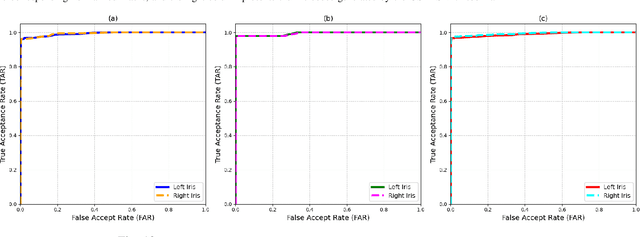
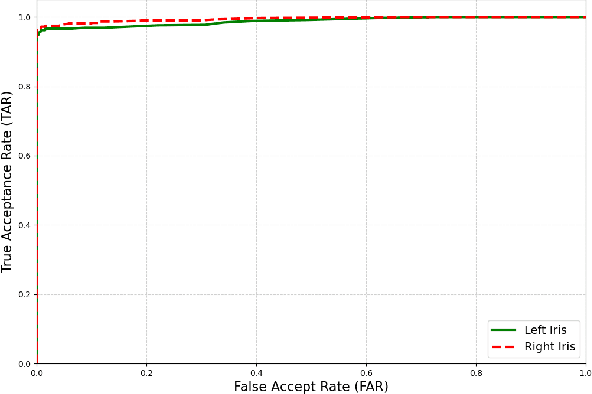
Smartphone-based iris recognition in the visible spectrum (VIS) offers a low-cost and accessible biometric alternative but remains a challenge due to lighting variability, pigmentation effects, and the limited adoption of standardized capture protocols. In this work, we present CUVIRIS, a dataset of 752 ISO/IEC 29794-6 compliant iris images from 47 subjects, collected with a custom Android application that enforces real-time framing, sharpness assessment, and quality feedback. We further introduce LightIrisNet, a MobileNetV3-based multi-task segmentation model optimized for on-device deployment. In addition, we adapt IrisFormer, a transformer-based matcher, to the VIS domain. We evaluate OSIRIS and IrisFormer under a standardized protocol and benchmark against published CNN baselines reported in prior work. On CUVIRIS, the open-source OSIRIS system achieves a TAR of 97.9% at FAR = 0.01 (EER = 0.76%), while IrisFormer, trained only on the UBIRIS.v2 dataset, achieves an EER of 0.057\%. To support reproducibility, we release the Android application, LightIrisNet, trained IrisFormer weights, and a subset of the CUVIRIS dataset. These results show that, with standardized acquisition and VIS-adapted lightweight models, accurate iris recognition on commodity smartphones is feasible under controlled conditions, bringing this modality closer to practical deployment.
Fighter Jet Navigation and Combat using Deep Reinforcement Learning with Explainable AI
Feb 19, 2025This paper presents the development of an Artificial Intelligence (AI) based fighter jet agent within a customized Pygame simulation environment, designed to solve multi-objective tasks via deep reinforcement learning (DRL). The jet's primary objectives include efficiently navigating the environment, reaching a target, and selectively engaging or evading an enemy. A reward function balances these goals while optimized hyperparameters enhance learning efficiency. Results show more than 80\% task completion rate, demonstrating effective decision-making. To enhance transparency, the jet's action choices are analyzed by comparing the rewards of the actual chosen action (factual action) with those of alternate actions (counterfactual actions), providing insights into the decision-making rationale. This study illustrates DRL's potential for multi-objective problem-solving with explainable AI. Project page is available at: \href{https://github.com/swatikar95/Autonomous-Fighter-Jet-Navigation-and-Combat}{Project GitHub Link}.
Smartphone-based Iris Recognition through High-Quality Visible Spectrum Iris Capture
Dec 17, 2024
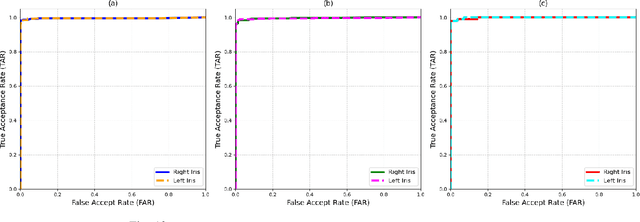
Iris recognition is widely acknowledged for its exceptional accuracy in biometric authentication, traditionally relying on near-infrared (NIR) imaging. Recently, visible spectrum (VIS) imaging via accessible smartphone cameras has been explored for biometric capture. However, a thorough study of iris recognition using smartphone-captured 'High-Quality' VIS images and cross-spectral matching with previously enrolled NIR images has not been conducted. The primary challenge lies in capturing high-quality biometrics, a known limitation of smartphone cameras. This study introduces a novel Android application designed to consistently capture high-quality VIS iris images through automated focus and zoom adjustments. The application integrates a YOLOv3-tiny model for precise eye and iris detection and a lightweight Ghost-Attention U-Net (G-ATTU-Net) for segmentation, while adhering to ISO/IEC 29794-6 standards for image quality. The approach was validated using smartphone-captured VIS and NIR iris images from 47 subjects, achieving a True Acceptance Rate (TAR) of 96.57% for VIS images and 97.95% for NIR images, with consistent performance across various capture distances and iris colors. This robust solution is expected to significantly advance the field of iris biometrics, with important implications for enhancing smartphone security.
Liveness Detection Competition -- Noncontact-based Fingerprint Algorithms and Systems (LivDet-2023 Noncontact Fingerprint)
Oct 01, 2023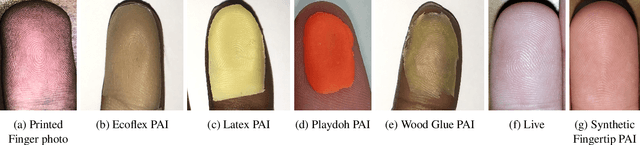


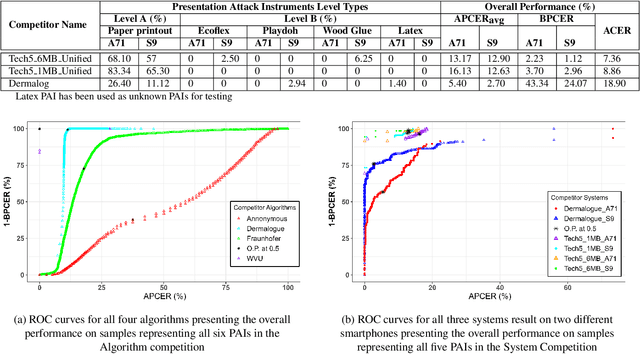
Liveness Detection (LivDet) is an international competition series open to academia and industry with the objec-tive to assess and report state-of-the-art in Presentation Attack Detection (PAD). LivDet-2023 Noncontact Fingerprint is the first edition of the noncontact fingerprint-based PAD competition for algorithms and systems. The competition serves as an important benchmark in noncontact-based fingerprint PAD, offering (a) independent assessment of the state-of-the-art in noncontact-based fingerprint PAD for algorithms and systems, and (b) common evaluation protocol, which includes finger photos of a variety of Presentation Attack Instruments (PAIs) and live fingers to the biometric research community (c) provides standard algorithm and system evaluation protocols, along with the comparative analysis of state-of-the-art algorithms from academia and industry with both old and new android smartphones. The winning algorithm achieved an APCER of 11.35% averaged overall PAIs and a BPCER of 0.62%. The winning system achieved an APCER of 13.0.4%, averaged over all PAIs tested over all the smartphones, and a BPCER of 1.68% over all smartphones tested. Four-finger systems that make individual finger-based PAD decisions were also tested. The dataset used for competition will be available 1 to all researchers as per data share protocol
Exploiting the Brain's Network Structure for Automatic Identification of ADHD Subjects
Jun 15, 2023

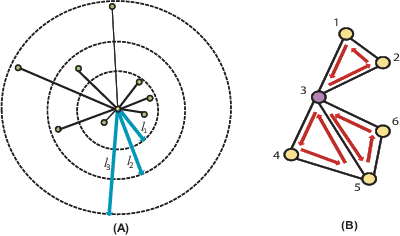
Attention Deficit Hyperactive Disorder (ADHD) is a common behavioral problem affecting children. In this work, we investigate the automatic classification of ADHD subjects using the resting state Functional Magnetic Resonance Imaging (fMRI) sequences of the brain. We show that the brain can be modeled as a functional network, and certain properties of the networks differ in ADHD subjects from control subjects. We compute the pairwise correlation of brain voxels' activity over the time frame of the experimental protocol which helps to model the function of a brain as a network. Different network features are computed for each of the voxels constructing the network. The concatenation of the network features of all the voxels in a brain serves as the feature vector. Feature vectors from a set of subjects are then used to train a PCA-LDA (principal component analysis-linear discriminant analysis) based classifier. We hypothesized that ADHD-related differences lie in some specific regions of the brain and using features only from those regions is sufficient to discriminate ADHD and control subjects. We propose a method to create a brain mask that includes the useful regions only and demonstrate that using the feature from the masked regions improves classification accuracy on the test data set. We train our classifier with 776 subjects and test on 171 subjects provided by The Neuro Bureau for the ADHD-200 challenge. We demonstrate the utility of graph-motif features, specifically the maps that represent the frequency of participation of voxels in network cycles of length 3. The best classification performance (69.59%) is achieved using 3-cycle map features with masking. Our proposed approach holds promise in being able to diagnose and understand the disorder.
Dynamic User Segmentation and Usage Profiling
May 27, 2023Usage data of a group of users distributed across a number of categories, such as songs, movies, webpages, links, regular household products, mobile apps, games, etc. can be ultra-high dimensional and massive in size. More often this kind of data is categorical and sparse in nature making it even more difficult to interpret any underlying hidden patterns such as clusters of users. However, if this information can be estimated accurately, it will have huge impacts in different business areas such as user recommendations for apps, songs, movies, and other similar products, health analytics using electronic health record (EHR) data, and driver profiling for insurance premium estimation or fleet management. In this work, we propose a clustering strategy of such categorical big data, utilizing the hidden sparsity of the dataset. Most traditional clustering methods fail to give proper clusters for such data and end up giving one big cluster with small clusters around it irrespective of the true structure of the data clusters. We propose a feature transformation, which maps the binary-valued usage vector to a lower dimensional continuous feature space in terms of groups of usage categories, termed as covariate classes. The lower dimensional feature representations in terms of covariate classes can be used for clustering. We implemented the proposed strategy and applied it to a large sized very high-dimensional song playlist dataset for the performance validation. The results are impressive as we achieved similar-sized user clusters with minimal between-cluster overlap in the feature space (8%) on average). As the proposed strategy has a very generic framework, it can be utilized as the analytic engine of many of the above-mentioned business use cases allowing an intelligent and dynamic personal recommendation system or a support system for smart business decision-making.
PIKS: A Technique to Identify Actionable Trends for Policy-Makers Through Open Healthcare Data
Apr 05, 2023With calls for increasing transparency, governments are releasing greater amounts of data in multiple domains including finance, education and healthcare. The efficient exploratory analysis of healthcare data constitutes a significant challenge. Key concerns in public health include the quick identification and analysis of trends, and the detection of outliers. This allows policies to be rapidly adapted to changing circumstances. We present an efficient outlier detection technique, termed PIKS (Pruned iterative-k means searchlight), which combines an iterative k-means algorithm with a pruned searchlight based scan. We apply this technique to identify outliers in two publicly available healthcare datasets from the New York Statewide Planning and Research Cooperative System, and California's Office of Statewide Health Planning and Development. We provide a comparison of our technique with three other existing outlier detection techniques, consisting of auto-encoders, isolation forests and feature bagging. We identified outliers in conditions including suicide rates, immunity disorders, social admissions, cardiomyopathies, and pregnancy in the third trimester. We demonstrate that the PIKS technique produces results consistent with other techniques such as the auto-encoder. However, the auto-encoder needs to be trained, which requires several parameters to be tuned. In comparison, the PIKS technique has far fewer parameters to tune. This makes it advantageous for fast, "out-of-the-box" data exploration. The PIKS technique is scalable and can readily ingest new datasets. Hence, it can provide valuable, up-to-date insights to citizens, patients and policy-makers. We have made our code open source, and with the availability of open data, other researchers can easily reproduce and extend our work. This will help promote a deeper understanding of healthcare policies and public health issues.
A system for exploring big data: an iterative k-means searchlight for outlier detection on open health data
Apr 05, 2023



The interactive exploration of large and evolving datasets is challenging as relationships between underlying variables may not be fully understood. There may be hidden trends and patterns in the data that are worthy of further exploration and analysis. We present a system that methodically explores multiple combinations of variables using a searchlight technique and identifies outliers. An iterative k-means clustering algorithm is applied to features derived through a split-apply-combine paradigm used in the database literature. Outliers are identified as singleton or small clusters. This algorithm is swept across the dataset in a searchlight manner. The dimensions that contain outliers are combined in pairs with other dimensions using a susbset scan technique to gain further insight into the outliers. We illustrate this system by anaylzing open health care data released by New York State. We apply our iterative k-means searchlight followed by subset scanning. Several anomalous trends in the data are identified, including cost overruns at specific hospitals, and increases in diagnoses such as suicides. These constitute novel findings in the literature, and are of potential use to regulatory agencies, policy makers and concerned citizens.
Building predictive models of healthcare costs with open healthcare data
Apr 05, 2023Due to rapidly rising healthcare costs worldwide, there is significant interest in controlling them. An important aspect concerns price transparency, as preliminary efforts have demonstrated that patients will shop for lower costs, driving efficiency. This requires the data to be made available, and models that can predict healthcare costs for a wide range of patient demographics and conditions. We present an approach to this problem by developing a predictive model using machine-learning techniques. We analyzed de-identified patient data from New York State SPARCS (statewide planning and research cooperative system), consisting of 2.3 million records in 2016. We built models to predict costs from patient diagnoses and demographics. We investigated two model classes consisting of sparse regression and decision trees. We obtained the best performance by using a decision tree with depth 10. We obtained an R-square value of 0.76 which is better than the values reported in the literature for similar problems.
End-to-End Latency Optimization of Multi-view 3D Reconstruction for Disaster Response
Apr 04, 2023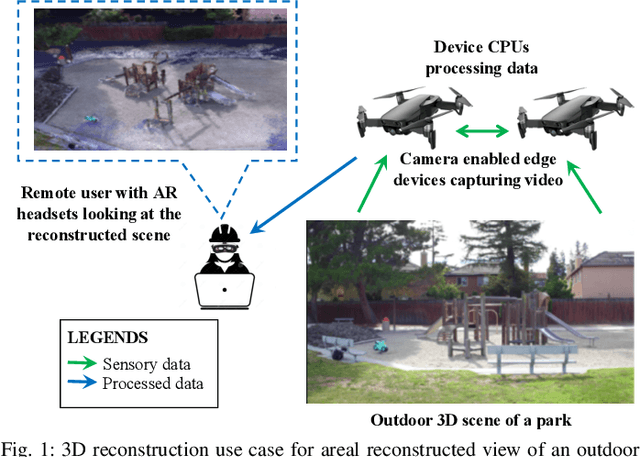
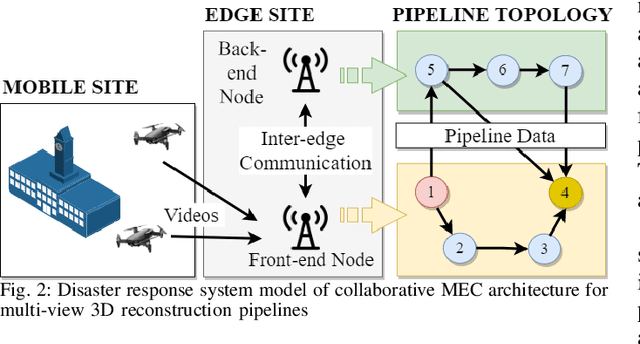

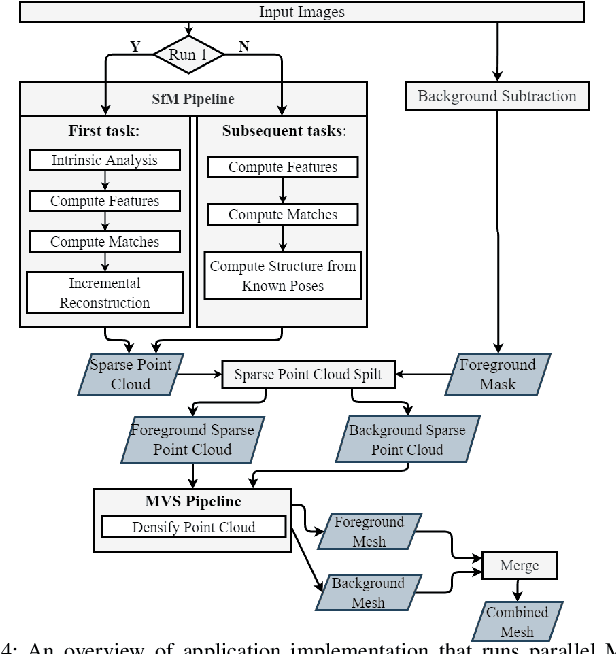
In order to plan rapid response during disasters, first responder agencies often adopt `bring your own device' (BYOD) model with inexpensive mobile edge devices (e.g., drones, robots, tablets) for complex video analytics applications, e.g., 3D reconstruction of a disaster scene. Unlike simpler video applications, widely used Multi-view Stereo (MVS) based 3D reconstruction applications (e.g., openMVG/openMVS) are exceedingly time consuming, especially when run on such computationally constrained mobile edge devices. Additionally, reducing the reconstruction latency of such inherently sequential algorithms is challenging as unintelligent, application-agnostic strategies can drastically degrade the reconstruction (i.e., application outcome) quality making them useless. In this paper, we aim to design a latency optimized MVS algorithm pipeline, with the objective to best balance the end-to-end latency and reconstruction quality by running the pipeline on a collaborative mobile edge environment. The overall optimization approach is two-pronged where: (a) application optimizations introduce data-level parallelism by splitting the pipeline into high frequency and low frequency reconstruction components and (b) system optimizations incorporate task-level parallelism to the pipelines by running them opportunistically on available resources with online quality control in order to balance both latency and quality. Our evaluation on a hardware testbed using publicly available datasets shows upto ~54% reduction in latency with negligible loss (~4-7%) in reconstruction quality.