 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAM4D: Fast 4D World Action Model via Spatial Register Tokens
Jun 12, 2026World action models (WAMs) have recently shown promise in jointly modeling future observations and executable robot actions. However, most existing WAMs still operate in 2D video or latent spaces, where visually plausible rollouts miss the 3D spatial constraints and occluded contact geometry required for precise manipulation. While geometric foundation models offer strong priors for recovering dense 3D structure and motion from visual observations, forcing WAMs to predict the dense 4D representation introduces costly geometric decoding and slows down causal action generation. To address the trade-off, we present WAM4D, a fast 4D world action model that uses lightweight spatial register tokens as training-time future-depth readouts to transfer pretrained geometric priors into a causal video-action transformer, then removes the register branch for lightweight action inference. To prevent non-causal shortcuts, we further design causal mixture attention for the Mixture-of-Transformers (MoT) WAM backbone, defining modality-specific visibility among video, action, and geometry tokens. Comprehensive experiments on RoboTwin 2.0 and challenging real-world manipulation tasks show that WAM4D improves spatial consistency and achieves competitive action prediction while maintaining efficient inference.
Mask World Model: Predicting What Matters for Robust Robot Policy Learning
Apr 22, 2026World models derived from large-scale video generative pre-training have emerged as a promising paradigm for generalist robot policy learning. However, standard approaches often focus on high-fidelity RGB video prediction, this can result in overfitting to irrelevant factors, such as dynamic backgrounds and illumination changes. These distractions reduce the model's ability to generalize, ultimately leading to unreliable and fragile control policies. To address this, we introduce the Mask World Model (MWM), which leverages video diffusion architectures to predict the evolution of semantic masks instead of pixels. This shift imposes a geometric information bottleneck, forcing the model to capture essential physical dynamics and contact relations while filtering out visual noise. We seamlessly integrate this mask dynamics backbone with a diffusion-based policy head to enable robust end-to-end control. Extensive evaluations demonstrate the superiority of MWM on the LIBERO and RLBench simulation benchmarks, significantly outperforming the state-of-the-art RGB-based world models. Furthermore, real-world experiments and robustness evaluation (via random token pruning) reveal that MWM exhibits superior generalization capabilities and robust resilience to texture information loss.
Reasoning Meets Personalization: Unleashing the Potential of Large Reasoning Model for Personalized Generation
May 23, 2025Personalization is a critical task in modern intelligent systems, with applications spanning diverse domains, including interactions with large language models (LLMs). Recent advances in reasoning capabilities have significantly enhanced LLMs, enabling unprecedented performance in tasks such as mathematics and coding. However, their potential for personalization tasks remains underexplored. In this paper, we present the first systematic evaluation of large reasoning models (LRMs) for personalization tasks. Surprisingly, despite generating more tokens, LRMs do not consistently outperform general-purpose LLMs, especially in retrieval-intensive scenarios where their advantages diminish. Our analysis identifies three key limitations: divergent thinking, misalignment of response formats, and ineffective use of retrieved information. To address these challenges, we propose Reinforced Reasoning for Personalization (\model), a novel framework that incorporates a hierarchical reasoning thought template to guide LRMs in generating structured outputs. Additionally, we introduce a reasoning process intervention method to enforce adherence to designed reasoning patterns, enhancing alignment. We also propose a cross-referencing mechanism to ensure consistency. Extensive experiments demonstrate that our approach significantly outperforms existing techniques.
RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning
Mar 26, 2025



Large Language Models (LLMs) have been integrated into recommender systems to enhance user behavior comprehension. The Retrieval Augmented Generation (RAG) technique is further incorporated into these systems to retrieve more relevant items and improve system performance. However, existing RAG methods have two shortcomings. \textit{(i)} In the \textit{retrieval} stage, they rely primarily on textual semantics and often fail to incorporate the most relevant items, thus constraining system effectiveness. \textit{(ii)} In the \textit{generation} stage, they lack explicit chain-of-thought reasoning, further limiting their potential. In this paper, we propose Representation learning and \textbf{R}easoning empowered retrieval-\textbf{A}ugmented \textbf{L}arge \textbf{L}anguage model \textbf{Rec}ommendation (RALLRec+). Specifically, for the retrieval stage, we prompt LLMs to generate detailed item descriptions and perform joint representation learning, combining textual and collaborative signals extracted from the LLM and recommendation models, respectively. To account for the time-varying nature of user interests, we propose a simple yet effective reranking method to capture preference dynamics. For the generation phase, we first evaluate reasoning LLMs on recommendation tasks, uncovering valuable insights. Then we introduce knowledge-injected prompting and consistency-based merging approach to integrate reasoning LLMs with general-purpose LLMs, enhancing overall performance. Extensive experiments on three real world datasets validate our method's effectiveness.
EdgeRL: Reinforcement Learning-driven Deep Learning Model Inference Optimization at Edge
Oct 16, 2024Balancing mutually diverging performance metrics, such as, processing latency, outcome accuracy, and end device energy consumption is a challenging undertaking for deep learning model inference in ad-hoc edge environments. In this paper, we propose EdgeRL framework that seeks to strike such balance by using an Advantage Actor-Critic (A2C) Reinforcement Learning (RL) approach that can choose optimal run-time DNN inference parameters and aligns the performance metrics based on the application requirements. Using real world deep learning model and a hardware testbed, we evaluate the benefits of EdgeRL framework in terms of end device energy savings, inference accuracy improvement, and end-to-end inference latency reduction.
UniDoorManip: Learning Universal Door Manipulation Policy Over Large-scale and Diverse Door Manipulation Environments
Mar 12, 2024Learning a universal manipulation policy encompassing doors with diverse categories, geometries and mechanisms, is crucial for future embodied agents to effectively work in complex and broad real-world scenarios. Due to the limited datasets and unrealistic simulation environments, previous works fail to achieve good performance across various doors. In this work, we build a novel door manipulation environment reflecting different realistic door manipulation mechanisms, and further equip this environment with a large-scale door dataset covering 6 door categories with hundreds of door bodies and handles, making up thousands of different door instances. Additionally, to better emulate real-world scenarios, we introduce a mobile robot as the agent and use the partial and occluded point cloud as the observation, which are not considered in previous works while possessing significance for real-world implementations. To learn a universal policy over diverse doors, we propose a novel framework disentangling the whole manipulation process into three stages, and integrating them by training in the reversed order of inference. Extensive experiments validate the effectiveness of our designs and demonstrate our framework's strong performance. Code, data and videos are avaible on https://unidoormanip.github.io/.
End-to-End Latency Optimization of Multi-view 3D Reconstruction for Disaster Response
Apr 04, 2023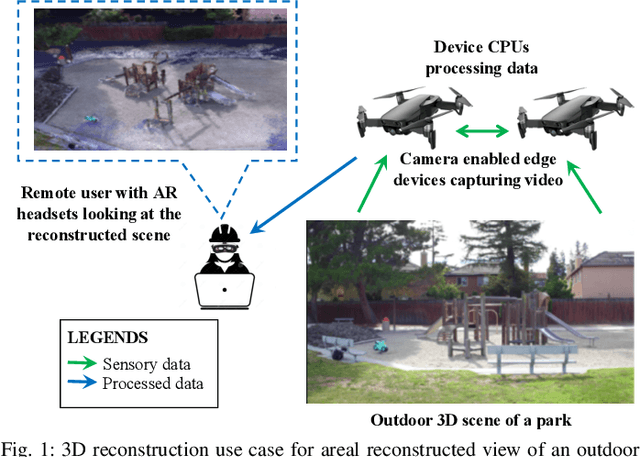
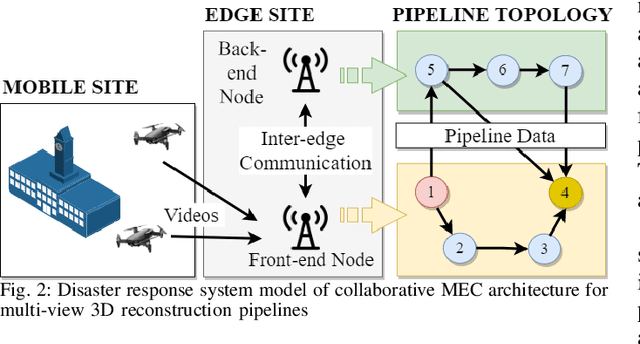

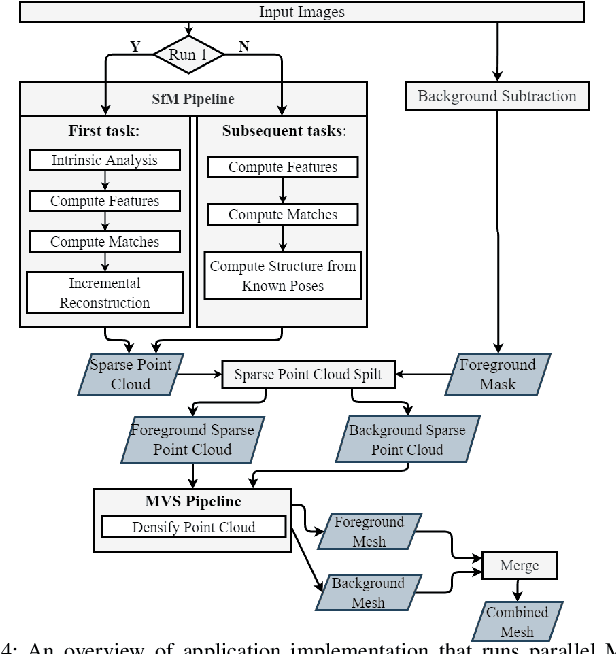
In order to plan rapid response during disasters, first responder agencies often adopt `bring your own device' (BYOD) model with inexpensive mobile edge devices (e.g., drones, robots, tablets) for complex video analytics applications, e.g., 3D reconstruction of a disaster scene. Unlike simpler video applications, widely used Multi-view Stereo (MVS) based 3D reconstruction applications (e.g., openMVG/openMVS) are exceedingly time consuming, especially when run on such computationally constrained mobile edge devices. Additionally, reducing the reconstruction latency of such inherently sequential algorithms is challenging as unintelligent, application-agnostic strategies can drastically degrade the reconstruction (i.e., application outcome) quality making them useless. In this paper, we aim to design a latency optimized MVS algorithm pipeline, with the objective to best balance the end-to-end latency and reconstruction quality by running the pipeline on a collaborative mobile edge environment. The overall optimization approach is two-pronged where: (a) application optimizations introduce data-level parallelism by splitting the pipeline into high frequency and low frequency reconstruction components and (b) system optimizations incorporate task-level parallelism to the pipelines by running them opportunistically on available resources with online quality control in order to balance both latency and quality. Our evaluation on a hardware testbed using publicly available datasets shows upto ~54% reduction in latency with negligible loss (~4-7%) in reconstruction quality.
Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation
Apr 20, 2020
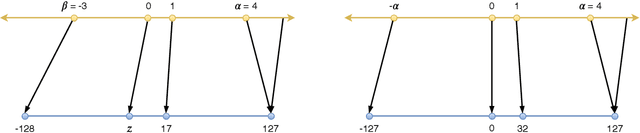
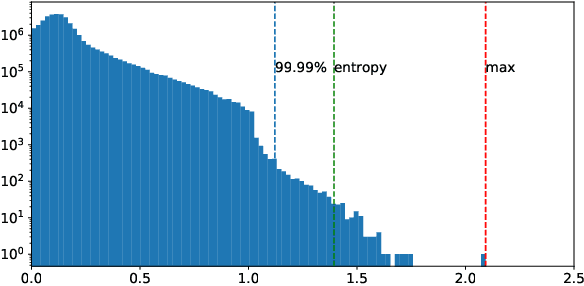
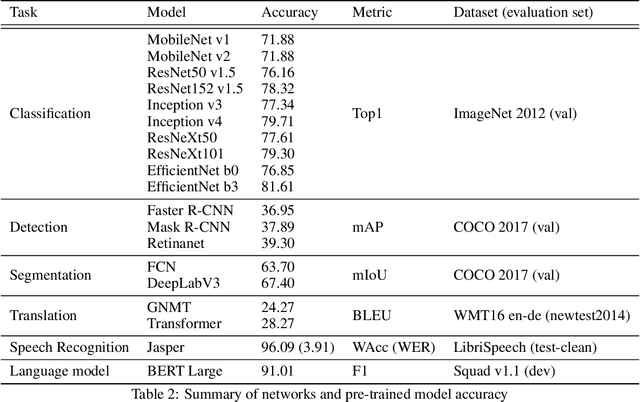
Quantization techniques can reduce the size of Deep Neural Networks and improve inference latency and throughput by taking advantage of high throughput integer instructions. In this paper we review the mathematical aspects of quantization parameters and evaluate their choices on a wide range of neural network models for different application domains, including vision, speech, and language. We focus on quantization techniques that are amenable to acceleration by processors with high-throughput integer math pipelines. We also present a workflow for 8-bit quantization that is able to maintain accuracy within 1% of the floating-point baseline on all networks studied, including models that are more difficult to quantize, such as MobileNets and BERT-large.