 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting 3D Motion from 2D Video for Behavior-Based VR Biometrics
Feb 05, 2025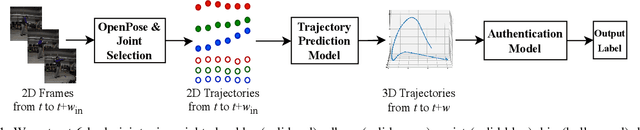

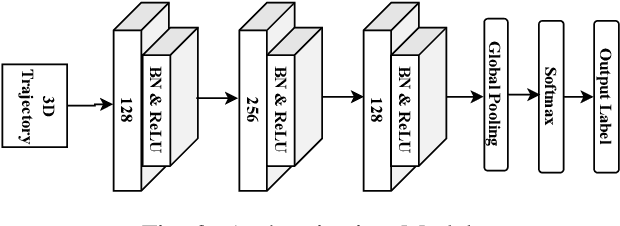

Critical VR applications in domains such as healthcare, education, and finance that use traditional credentials, such as PIN, password, or multi-factor authentication, stand the chance of being compromised if a malicious person acquires the user credentials or if the user hands over their credentials to an ally. Recently, a number of approaches on user authentication have emerged that use motions of VR head-mounted displays (HMDs) and hand controllers during user interactions in VR to represent the user's behavior as a VR biometric signature. One of the fundamental limitations of behavior-based approaches is that current on-device tracking for HMDs and controllers lacks capability to perform tracking of full-body joint articulation, losing key signature data encapsulated by the user articulation. In this paper, we propose an approach that uses 2D body joints, namely shoulder, elbow, wrist, hip, knee, and ankle, acquired from the right side of the participants using an external 2D camera. Using a Transformer-based deep neural network, our method uses the 2D data of body joints that are not tracked by the VR device to predict past and future 3D tracks of the right controller, providing the benefit of augmenting 3D knowledge in authentication. Our approach provides a minimum equal error rate (EER) of 0.025, and a maximum EER drop of 0.040 over prior work that uses single-unit 3D trajectory as the input.
Knowledge Transfer from Simple to Complex: A Safe and Efficient Reinforcement Learning Framework for Autonomous Driving Decision-Making
Oct 21, 2024



A safe and efficient decision-making system is crucial for autonomous vehicles. However, the complexity and variability of driving environments limit the effectiveness of many rule-based and machine learning-based decision-making approaches. Reinforcement Learning in autonomous driving offers a promising solution to these challenges. Nevertheless, concerns regarding safety and efficiency during training remain major obstacles to its widespread application. To address these concerns, we propose a novel RL framework named Simple to Complex Collaborative Decision. First, we rapidly train the teacher model using the Proximal Policy Optimization algorithm in a lightweight simulation environment. In the more intricate simulation environment, the teacher model intervenes when the student agent exhibits suboptimal behavior by assessing the value of actions to avert dangerous situations. We also introduce an innovative RL algorithm called Adaptive Clipping PPO, which is trained using a combination of samples generated by both teacher and student policies, and employs dynamic clipping strategies based on sample importance. Additionally, we employ the KL divergence as a constraint on policy optimization, transforming it into an unconstrained problem to accelerate the student's learning of the teacher's policy. Finally, a gradual weaning strategy is employed to ensure that, over time, the student agent learns to explore independently. Simulation experiments in highway lane-change scenarios demonstrate that the S2CD framework enhances learning efficiency, reduces training costs, and significantly improves safety during training when compared with state-of-the-art baseline algorithms. This approach also ensures effective knowledge transfer between teacher and student models, and even when the teacher model is suboptimal.
Using Motion Forecasting for Behavior-Based Virtual Reality (VR) Authentication
Jan 30, 2024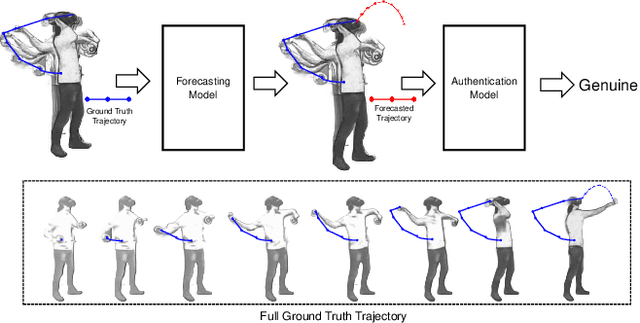
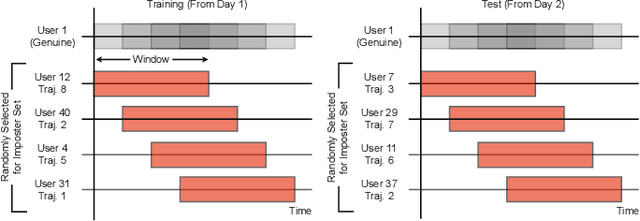

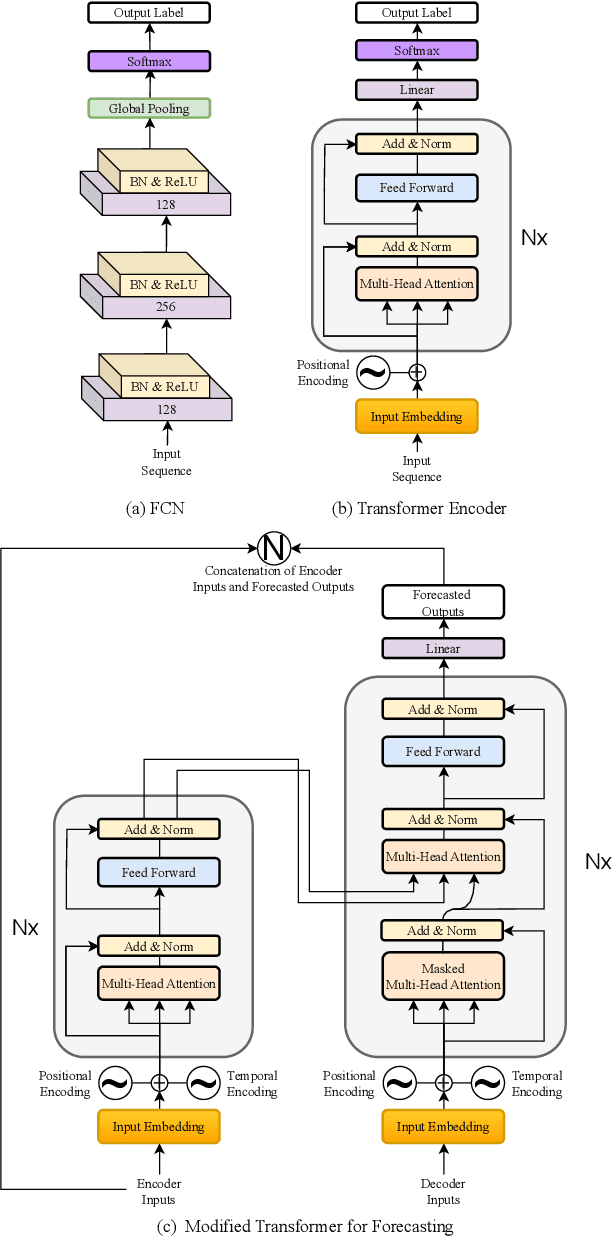
Task-based behavioral biometric authentication of users interacting in virtual reality (VR) environments enables seamless continuous authentication by using only the motion trajectories of the person's body as a unique signature. Deep learning-based approaches for behavioral biometrics show high accuracy when using complete or near complete portions of the user trajectory, but show lower performance when using smaller segments from the start of the task. Thus, any systems designed with existing techniques are vulnerable while waiting for future segments of motion trajectories to become available. In this work, we present the first approach that predicts future user behavior using Transformer-based forecasting and using the forecasted trajectory to perform user authentication. Our work leverages the notion that given the current trajectory of a user in a task-based environment we can predict the future trajectory of the user as they are unlikely to dramatically shift their behavior since it would preclude the user from successfully completing their task goal. Using the publicly available 41-subject ball throwing dataset of Miller et al. we show improvement in user authentication when using forecasted data. When compared to no forecasting, our approach reduces the authentication equal error rate (EER) by an average of 23.85% and a maximum reduction of 36.14%.
Evaluating Deep Networks for Detecting User Familiarity with VR from Hand Interactions
Jan 27, 2024
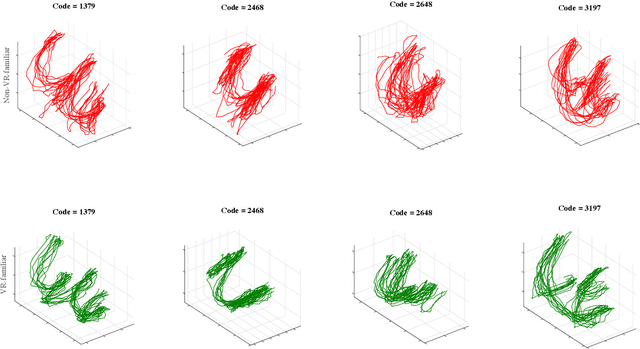
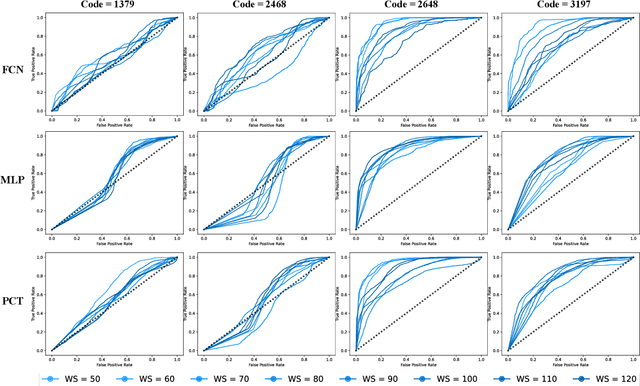
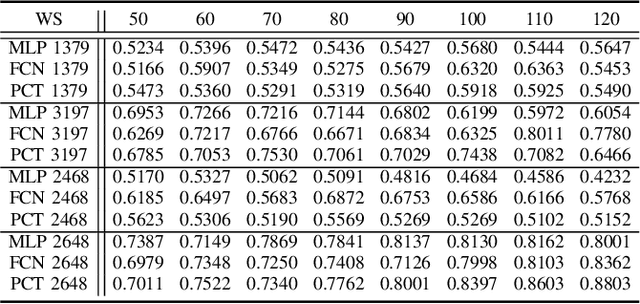
As VR devices become more prevalent in the consumer space, VR applications are likely to be increasingly used by users unfamiliar with VR. Detecting the familiarity level of a user with VR as an interaction medium provides the potential of providing on-demand training for acclimatization and prevents the user from being burdened by the VR environment in accomplishing their tasks. In this work, we present preliminary results of using deep classifiers to conduct automatic detection of familiarity with VR by using hand tracking of the user as they interact with a numeric passcode entry panel to unlock a VR door. We use a VR door as we envision it to the first point of entry to collaborative virtual spaces, such as meeting rooms, offices, or clinics. Users who are unfamiliar with VR will have used their hands to open doors with passcode entry panels in the real world. Thus, while the user may not be familiar with VR, they would be familiar with the task of opening the door. Using a pilot dataset consisting of 7 users familiar with VR, and 7 not familiar with VR, we acquire highest accuracy of 88.03\% when 6 test users, 3 familiar and 3 not familiar, are evaluated with classifiers trained using data from the remaining 8 users. Our results indicate potential for using user movement data to detect familiarity for the simple yet important task of secure passcode-based access.
End-to-End Latency Optimization of Multi-view 3D Reconstruction for Disaster Response
Apr 04, 2023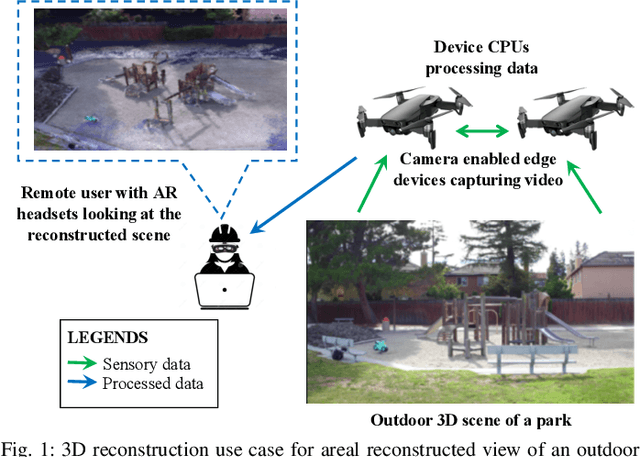
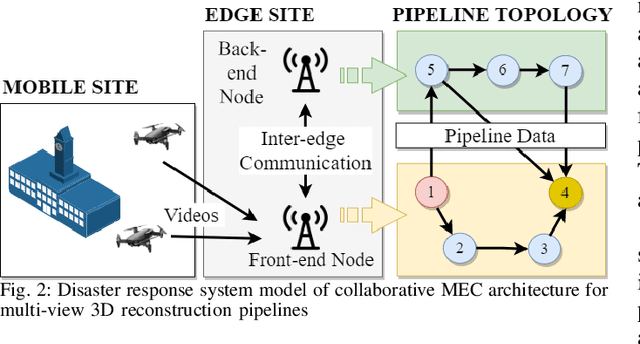

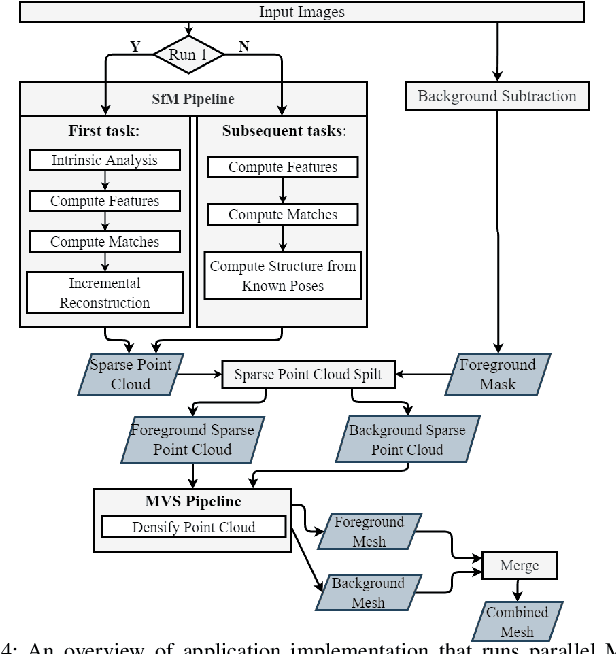
In order to plan rapid response during disasters, first responder agencies often adopt `bring your own device' (BYOD) model with inexpensive mobile edge devices (e.g., drones, robots, tablets) for complex video analytics applications, e.g., 3D reconstruction of a disaster scene. Unlike simpler video applications, widely used Multi-view Stereo (MVS) based 3D reconstruction applications (e.g., openMVG/openMVS) are exceedingly time consuming, especially when run on such computationally constrained mobile edge devices. Additionally, reducing the reconstruction latency of such inherently sequential algorithms is challenging as unintelligent, application-agnostic strategies can drastically degrade the reconstruction (i.e., application outcome) quality making them useless. In this paper, we aim to design a latency optimized MVS algorithm pipeline, with the objective to best balance the end-to-end latency and reconstruction quality by running the pipeline on a collaborative mobile edge environment. The overall optimization approach is two-pronged where: (a) application optimizations introduce data-level parallelism by splitting the pipeline into high frequency and low frequency reconstruction components and (b) system optimizations incorporate task-level parallelism to the pipelines by running them opportunistically on available resources with online quality control in order to balance both latency and quality. Our evaluation on a hardware testbed using publicly available datasets shows upto ~54% reduction in latency with negligible loss (~4-7%) in reconstruction quality.
FedRight: An Effective Model Copyright Protection for Federated Learning
Mar 18, 2023Federated learning (FL), an effective distributed machine learning framework, implements model training and meanwhile protects local data privacy. It has been applied to a broad variety of practice areas due to its great performance and appreciable profits. Who owns the model, and how to protect the copyright has become a real problem. Intuitively, the existing property rights protection methods in centralized scenarios (e.g., watermark embedding and model fingerprints) are possible solutions for FL. But they are still challenged by the distributed nature of FL in aspects of the no data sharing, parameter aggregation, and federated training settings. For the first time, we formalize the problem of copyright protection for FL, and propose FedRight to protect model copyright based on model fingerprints, i.e., extracting model features by generating adversarial examples as model fingerprints. FedRight outperforms previous works in four key aspects: (i) Validity: it extracts model features to generate transferable fingerprints to train a detector to verify the copyright of the model. (ii) Fidelity: it is with imperceptible impact on the federated training, thus promising good main task performance. (iii) Robustness: it is empirically robust against malicious attacks on copyright protection, i.e., fine-tuning, model pruning, and adaptive attacks. (iv) Black-box: it is valid in the black-box forensic scenario where only application programming interface calls to the model are available. Extensive evaluations across 3 datasets and 9 model structures demonstrate FedRight's superior fidelity, validity, and robustness.
Rethinking the Defense Against Free-rider Attack From the Perspective of Model Weight Evolving Frequency
Jun 11, 2022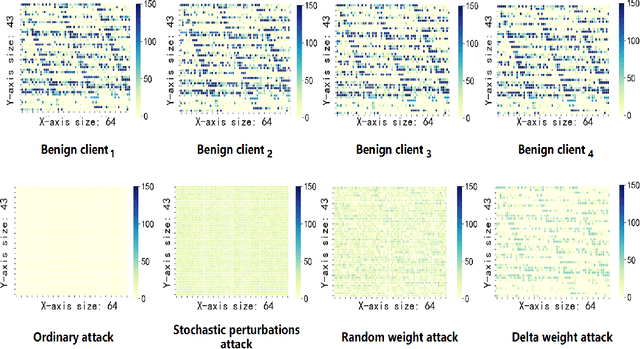
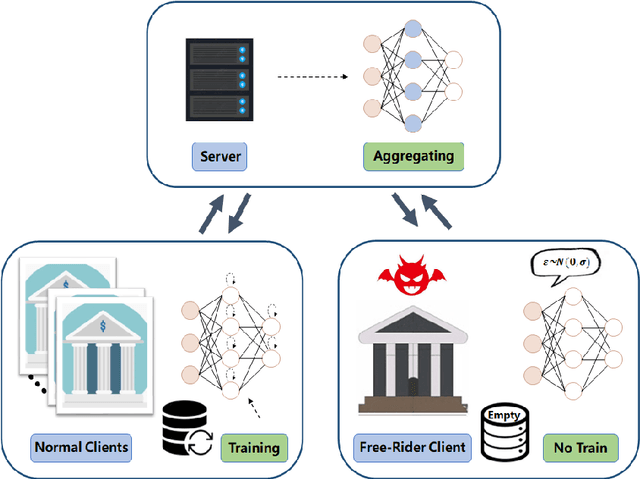
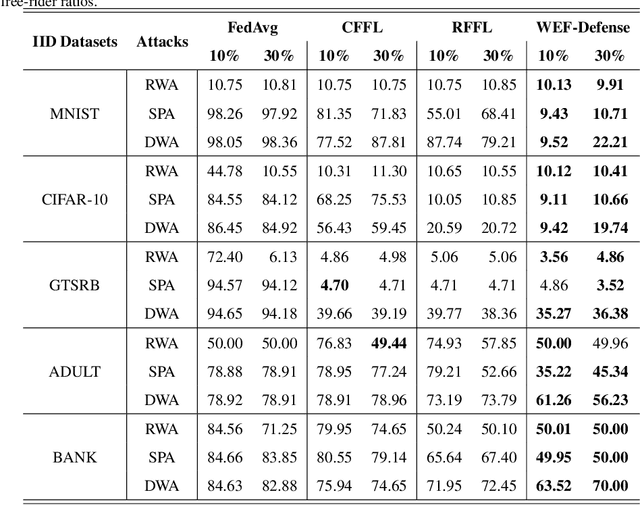
Federated learning (FL) is a distributed machine learning approach where multiple clients collaboratively train a joint model without exchanging their data. Despite FL's unprecedented success in data privacy-preserving, its vulnerability to free-rider attacks has attracted increasing attention. Existing defenses may be ineffective against highly camouflaged or high percentages of free riders. To address these challenges, we reconsider the defense from a novel perspective, i.e., model weight evolving frequency.Empirically, we gain a novel insight that during the FL's training, the model weight evolving frequency of free-riders and that of benign clients are significantly different. Inspired by this insight, we propose a novel defense method based on the model Weight Evolving Frequency, referred to as WEF-Defense.Specifically, we first collect the weight evolving frequency (defined as WEF-Matrix) during local training. For each client, it uploads the local model's WEF-Matrix to the server together with its model weight for each iteration. The server then separates free-riders from benign clients based on the difference in the WEF-Matrix. Finally, the server uses a personalized approach to provide different global models for corresponding clients. Comprehensive experiments conducted on five datasets and five models demonstrate that WEF-Defense achieves better defense effectiveness than the state-of-the-art baselines.
Eventor: An Efficient Event-Based Monocular Multi-View Stereo Accelerator on FPGA Platform
Mar 29, 2022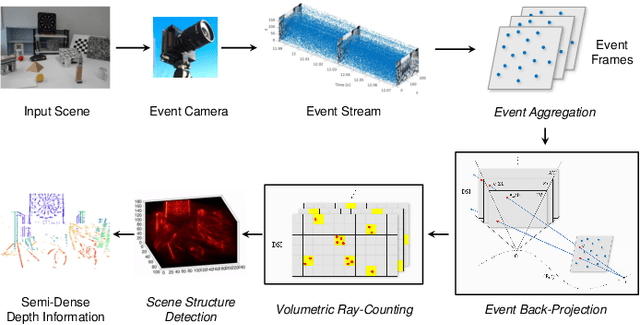
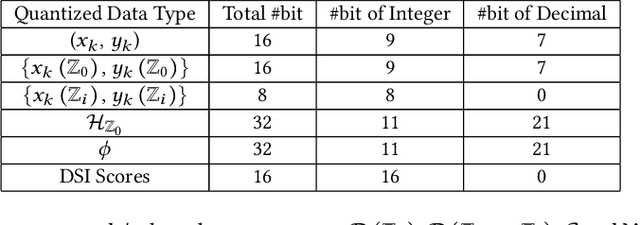
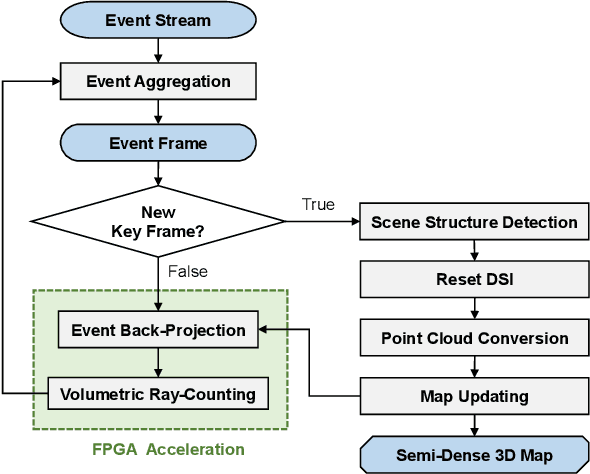
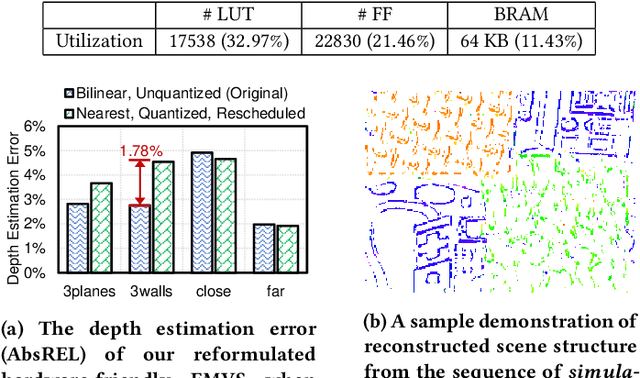
Event cameras are bio-inspired vision sensors that asynchronously represent pixel-level brightness changes as event streams. Event-based monocular multi-view stereo (EMVS) is a technique that exploits the event streams to estimate semi-dense 3D structure with known trajectory. It is a critical task for event-based monocular SLAM. However, the required intensive computation workloads make it challenging for real-time deployment on embedded platforms. In this paper, Eventor is proposed as a fast and efficient EMVS accelerator by realizing the most critical and time-consuming stages including event back-projection and volumetric ray-counting on FPGA. Highly paralleled and fully pipelined processing elements are specially designed via FPGA and integrated with the embedded ARM as a heterogeneous system to improve the throughput and reduce the memory footprint. Meanwhile, the EMVS algorithm is reformulated to a more hardware-friendly manner by rescheduling, approximate computing and hybrid data quantization. Evaluation results on DAVIS dataset show that Eventor achieves up to $24\times$ improvement in energy efficiency compared with Intel i5 CPU platform.