 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark Reference for ESP32-CAM Module
May 29, 2025The ESP32-CAM is one of the most widely adopted open-source modules for prototyping embedded vision applications. Since its release in 2019, it has gained popularity among both hobbyists and professional developers due to its affordability, versatility, and integrated wireless capabilities. Despite its widespread use, comprehensive documentation of the performance metrics remains limited. This study addresses this gap by collecting and analyzing over six hours of real-time video streaming logs across all supported resolutions of the OV2640 image sensor, tested under five distinct voltage conditions via an HTTP-based WiFi connection. A long standing bug in the official Arduino ESP32 driver, responsible for inaccurate frame rate logging, was fixed. The resulting analysis includes key performance metrics such as instantaneous and average frame rate, total streamed data, transmission count, and internal chip temperature. The influence of varying power levels was evaluated to assess the reliability of the module.
Predicting 3D Motion from 2D Video for Behavior-Based VR Biometrics
Feb 05, 2025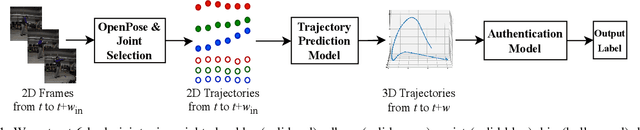

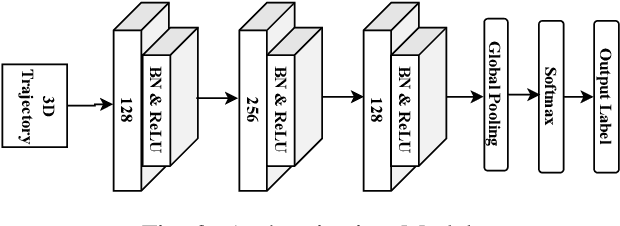

Critical VR applications in domains such as healthcare, education, and finance that use traditional credentials, such as PIN, password, or multi-factor authentication, stand the chance of being compromised if a malicious person acquires the user credentials or if the user hands over their credentials to an ally. Recently, a number of approaches on user authentication have emerged that use motions of VR head-mounted displays (HMDs) and hand controllers during user interactions in VR to represent the user's behavior as a VR biometric signature. One of the fundamental limitations of behavior-based approaches is that current on-device tracking for HMDs and controllers lacks capability to perform tracking of full-body joint articulation, losing key signature data encapsulated by the user articulation. In this paper, we propose an approach that uses 2D body joints, namely shoulder, elbow, wrist, hip, knee, and ankle, acquired from the right side of the participants using an external 2D camera. Using a Transformer-based deep neural network, our method uses the 2D data of body joints that are not tracked by the VR device to predict past and future 3D tracks of the right controller, providing the benefit of augmenting 3D knowledge in authentication. Our approach provides a minimum equal error rate (EER) of 0.025, and a maximum EER drop of 0.040 over prior work that uses single-unit 3D trajectory as the input.
Using Motion Forecasting for Behavior-Based Virtual Reality (VR) Authentication
Jan 30, 2024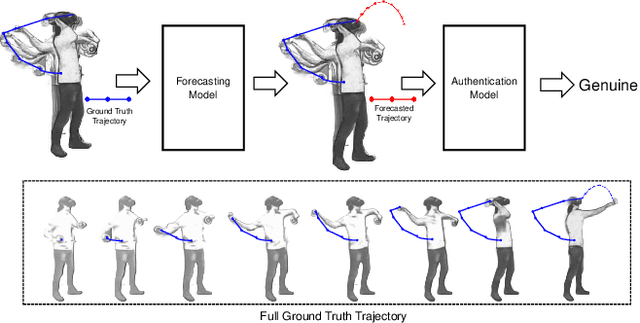
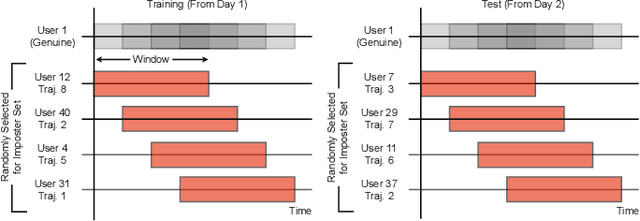

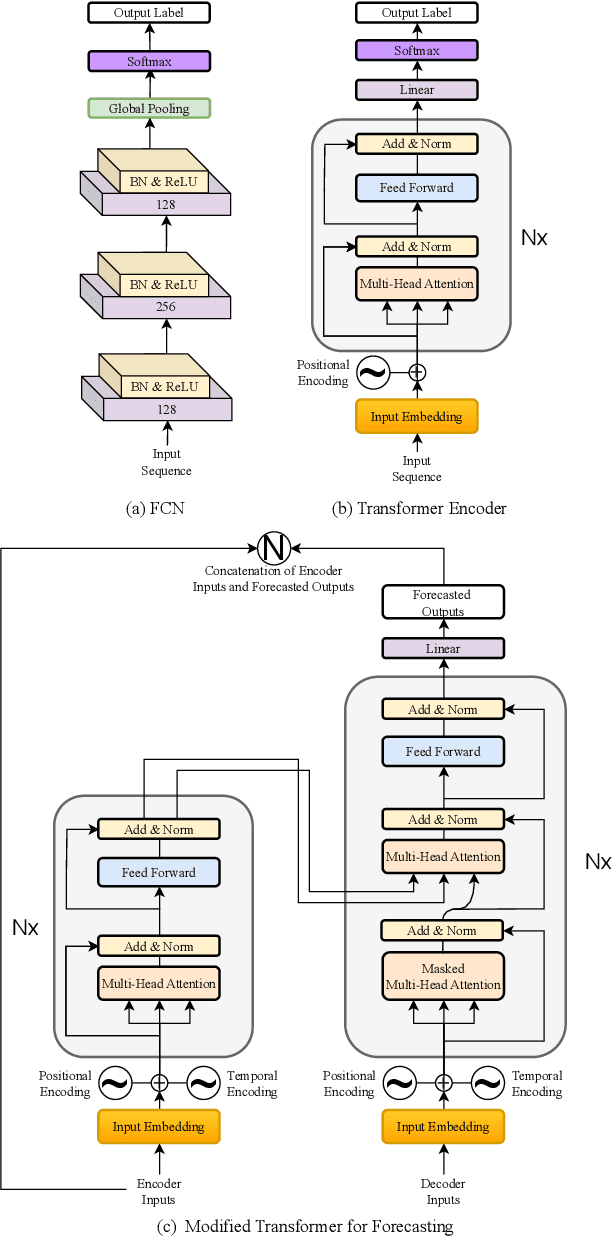
Task-based behavioral biometric authentication of users interacting in virtual reality (VR) environments enables seamless continuous authentication by using only the motion trajectories of the person's body as a unique signature. Deep learning-based approaches for behavioral biometrics show high accuracy when using complete or near complete portions of the user trajectory, but show lower performance when using smaller segments from the start of the task. Thus, any systems designed with existing techniques are vulnerable while waiting for future segments of motion trajectories to become available. In this work, we present the first approach that predicts future user behavior using Transformer-based forecasting and using the forecasted trajectory to perform user authentication. Our work leverages the notion that given the current trajectory of a user in a task-based environment we can predict the future trajectory of the user as they are unlikely to dramatically shift their behavior since it would preclude the user from successfully completing their task goal. Using the publicly available 41-subject ball throwing dataset of Miller et al. we show improvement in user authentication when using forecasted data. When compared to no forecasting, our approach reduces the authentication equal error rate (EER) by an average of 23.85% and a maximum reduction of 36.14%.
Evaluating Deep Networks for Detecting User Familiarity with VR from Hand Interactions
Jan 27, 2024
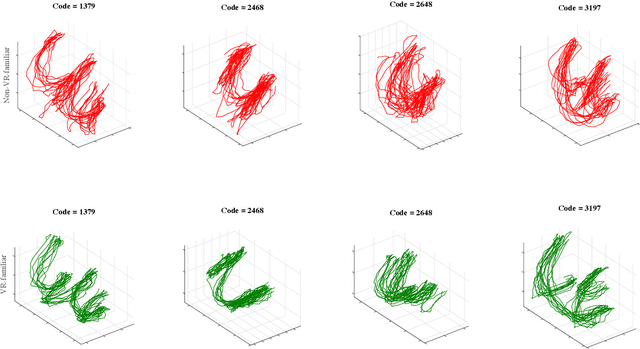
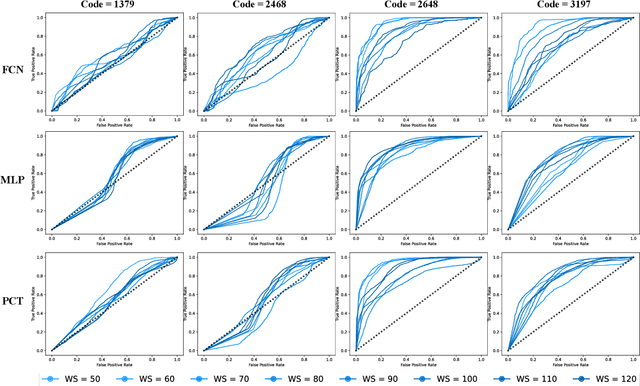
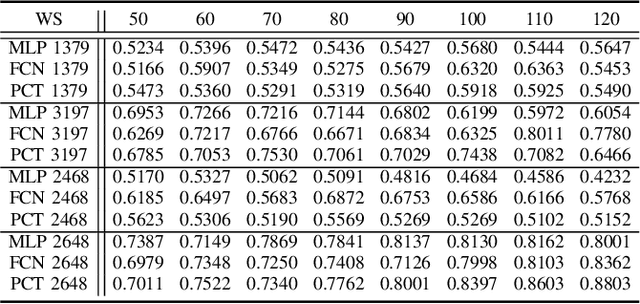
As VR devices become more prevalent in the consumer space, VR applications are likely to be increasingly used by users unfamiliar with VR. Detecting the familiarity level of a user with VR as an interaction medium provides the potential of providing on-demand training for acclimatization and prevents the user from being burdened by the VR environment in accomplishing their tasks. In this work, we present preliminary results of using deep classifiers to conduct automatic detection of familiarity with VR by using hand tracking of the user as they interact with a numeric passcode entry panel to unlock a VR door. We use a VR door as we envision it to the first point of entry to collaborative virtual spaces, such as meeting rooms, offices, or clinics. Users who are unfamiliar with VR will have used their hands to open doors with passcode entry panels in the real world. Thus, while the user may not be familiar with VR, they would be familiar with the task of opening the door. Using a pilot dataset consisting of 7 users familiar with VR, and 7 not familiar with VR, we acquire highest accuracy of 88.03\% when 6 test users, 3 familiar and 3 not familiar, are evaluated with classifiers trained using data from the remaining 8 users. Our results indicate potential for using user movement data to detect familiarity for the simple yet important task of secure passcode-based access.
HOH: Markerless Multimodal Human-Object-Human Handover Dataset with Large Object Count
Oct 01, 2023



We present the HOH (Human-Object-Human) Handover Dataset, a large object count dataset with 136 objects, to accelerate data-driven research on handover studies, human-robot handover implementation, and artificial intelligence (AI) on handover parameter estimation from 2D and 3D data of person interactions. HOH contains multi-view RGB and depth data, skeletons, fused point clouds, grasp type and handedness labels, object, giver hand, and receiver hand 2D and 3D segmentations, giver and receiver comfort ratings, and paired object metadata and aligned 3D models for 2,720 handover interactions spanning 136 objects and 20 giver-receiver pairs-40 with role-reversal-organized from 40 participants. We also show experimental results of neural networks trained using HOH to perform grasp, orientation, and trajectory prediction. As the only fully markerless handover capture dataset, HOH represents natural human-human handover interactions, overcoming challenges with markered datasets that require specific suiting for body tracking, and lack high-resolution hand tracking. To date, HOH is the largest handover dataset in number of objects, participants, pairs with role reversal accounted for, and total interactions captured.
Pix2Repair: Implicit Shape Restoration from Images
May 29, 2023We present Pix2Repair, an automated shape repair approach that generates restoration shapes from images to repair fractured objects. Prior repair approaches require a high-resolution watertight 3D mesh of the fractured object as input. Input 3D meshes must be obtained using expensive 3D scanners, and scanned meshes require manual cleanup, limiting accessibility and scalability. Pix2Repair takes an image of the fractured object as input and automatically generates a 3D printable restoration shape. We contribute a novel shape function that deconstructs a latent code representing the fractured object into a complete shape and a break surface. We show restorations for synthetic fractures from the Geometric Breaks and Breaking Bad datasets, and cultural heritage objects from the QP dataset, and for real fractures from the Fantastic Breaks dataset. We overcome challenges in restoring axially symmetric objects by predicting view-centered restorations. Our approach outperforms shape completion approaches adapted for shape repair in terms of chamfer distance, earth mover's distance, normal consistency, and percent restorations generated.
Fantastic Breaks: A Dataset of Paired 3D Scans of Real-World Broken Objects and Their Complete Counterparts
Mar 30, 2023
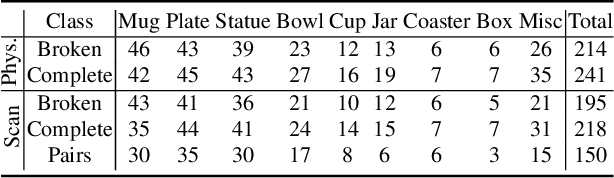

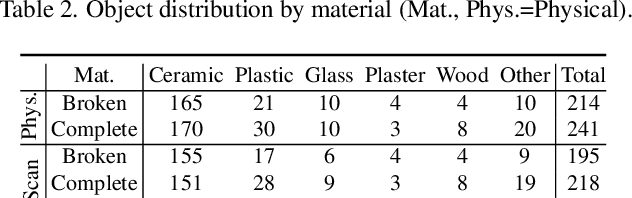
Automated shape repair approaches currently lack access to datasets that describe real-world damaged geometry. We present Fantastic Breaks (and Where to Find Them: https://terascale-all-sensing-research-studio.github.io/FantasticBreaks), a dataset containing scanned, waterproofed, and cleaned 3D meshes for 150 broken objects, paired and geometrically aligned with complete counterparts. Fantastic Breaks contains class and material labels, proxy repair parts that join to broken meshes to generate complete meshes, and manually annotated fracture boundaries. Through a detailed analysis of fracture geometry, we reveal differences between Fantastic Breaks and synthetic fracture datasets generated using geometric and physics-based methods. We show experimental shape repair evaluation with Fantastic Breaks using multiple learning-based approaches pre-trained with synthetic datasets and re-trained with subset of Fantastic Breaks.
Simultaneous prediction of hand gestures, handedness, and hand keypoints using thermal images
Mar 02, 2023



Hand gesture detection is a well-explored area in computer vision with applications in various forms of Human-Computer Interactions. In this work, we propose a technique for simultaneous hand gesture classification, handedness detection, and hand keypoints localization using thermal data captured by an infrared camera. Our method uses a novel deep multi-task learning architecture that includes shared encoderdecoder layers followed by three branches dedicated for each mentioned task. We performed extensive experimental validation of our model on an in-house dataset consisting of 24 users data. The results confirm higher than 98 percent accuracy for gesture classification, handedness detection, and fingertips localization, and more than 91 percent accuracy for wrist points localization.
DeepJoin: Learning a Joint Occupancy, Signed Distance, and Normal Field Function for Shape Repair
Nov 22, 2022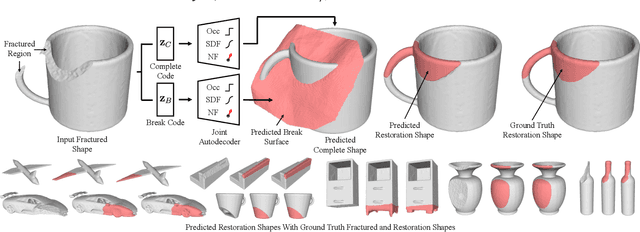
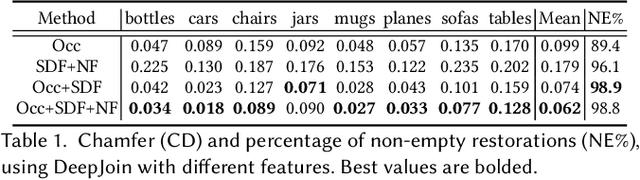

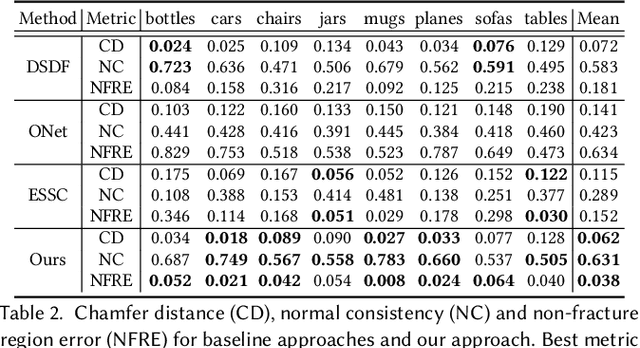
We introduce DeepJoin, an automated approach to generate high-resolution repairs for fractured shapes using deep neural networks. Existing approaches to perform automated shape repair operate exclusively on symmetric objects, require a complete proxy shape, or predict restoration shapes using low-resolution voxels which are too coarse for physical repair. We generate a high-resolution restoration shape by inferring a corresponding complete shape and a break surface from an input fractured shape. We present a novel implicit shape representation for fractured shape repair that combines the occupancy function, signed distance function, and normal field. We demonstrate repairs using our approach for synthetically fractured objects from ShapeNet, 3D scans from the Google Scanned Objects dataset, objects in the style of ancient Greek pottery from the QP Cultural Heritage dataset, and real fractured objects. We outperform three baseline approaches in terms of chamfer distance and normal consistency. Unlike existing approaches and restorations using subtraction, DeepJoin restorations do not exhibit surface artifacts and join closely to the fractured region of the fractured shape. Our code is available at: https://github.com/Terascale-All-sensing-Research-Studio/DeepJoin.
DeepMend: Learning Occupancy Functions to Represent Shape for Repair
Oct 11, 2022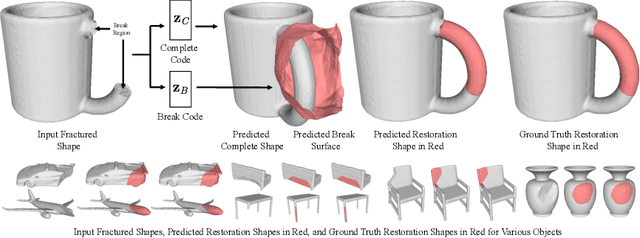
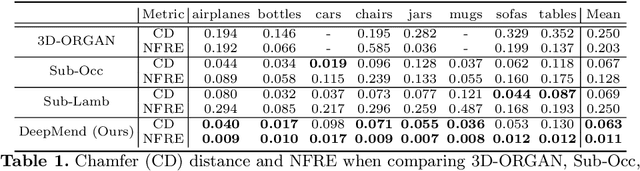
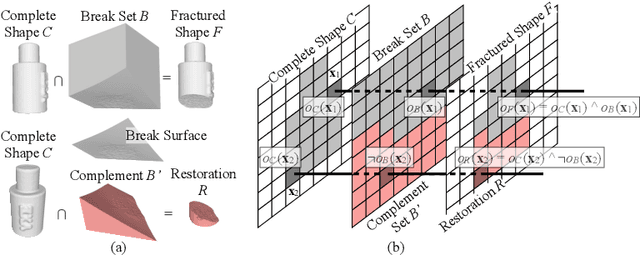
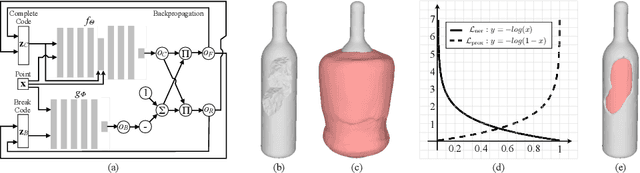
We present DeepMend, a novel approach to reconstruct restorations to fractured shapes using learned occupancy functions. Existing shape repair approaches predict low-resolution voxelized restorations, or require symmetries or access to a pre-existing complete oracle. We represent the occupancy of a fractured shape as the conjunction of the occupancy of an underlying complete shape and the fracture surface, which we model as functions of latent codes using neural networks. Given occupancy samples from an input fractured shape, we estimate latent codes using an inference loss augmented with novel penalty terms that avoid empty or voluminous restorations. We use inferred codes to reconstruct the restoration shape. We show results with simulated fractures on synthetic and real-world scanned objects, and with scanned real fractured mugs. Compared to the existing voxel approach and two baseline methods, our work shows state-of-the-art results in accuracy and avoiding restoration artifacts over non-fracture regions of the fractured shape.