 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNF: Dual-Layer Nested Fingerprinting for Large Language Model Intellectual Property Protection
Jan 13, 2026The rapid growth of large language models raises pressing concerns about intellectual property protection under black-box deployment. Existing backdoor-based fingerprints either rely on rare tokens -- leading to high-perplexity inputs susceptible to filtering -- or use fixed trigger-response mappings that are brittle to leakage and post-hoc adaptation. We propose \textsc{Dual-Layer Nested Fingerprinting} (DNF), a black-box method that embeds a hierarchical backdoor by coupling domain-specific stylistic cues with implicit semantic triggers. Across Mistral-7B, LLaMA-3-8B-Instruct, and Falcon3-7B-Instruct, DNF achieves perfect fingerprint activation while preserving downstream utility. Compared with existing methods, it uses lower-perplexity triggers, remains undetectable under fingerprint detection attacks, and is relatively robust to incremental fine-tuning and model merging. These results position DNF as a practical, stealthy, and resilient solution for LLM ownership verification and intellectual property protection.
DIAP: A Decentralized Agent Identity Protocol with Zero-Knowledge Proofs and a Hybrid P2P Stack
Nov 06, 2025The absence of a fully decentralized, verifiable, and privacy-preserving communication protocol for autonomous agents remains a core challenge in decentralized computing. Existing systems often rely on centralized intermediaries, which reintroduce trust bottlenecks, or lack decentralized identity-resolution mechanisms, limiting persistence and cross-network interoperability. We propose the Decentralized Interstellar Agent Protocol (DIAP), a novel framework for agent identity and communication that enables persistent, verifiable, and trustless interoperability in fully decentralized environments. DIAP binds an agent's identity to an immutable IPFS or IPNS content identifier and uses zero-knowledge proofs (ZKP) to dynamically and statelessly prove ownership, removing the need for record updates. We present a Rust SDK that integrates Noir (for zero-knowledge proofs), DID-Key, IPFS, and a hybrid peer-to-peer stack combining Libp2p GossipSub for discovery and Iroh for high-performance, QUIC based data exchange. DIAP introduces a zero-dependency ZKP deployment model through a universal proof manager and compile-time build script that embeds a precompiled Noir circuit, eliminating the need for external ZKP toolchains. This enables instant, verifiable, and privacy-preserving identity proofs. This work establishes a practical, high-performance foundation for next-generation autonomous agent ecosystems and agent-to-agent (A to A) economies.
HGMF: A Hierarchical Gaussian Mixture Framework for Scalable Tool Invocation within the Model Context Protocol
Aug 11, 2025Invoking external tools enables Large Language Models (LLMs) to perform complex, real-world tasks, yet selecting the correct tool from large, hierarchically-structured libraries remains a significant challenge. The limited context windows of LLMs and noise from irrelevant options often lead to low selection accuracy and high computational costs. To address this, we propose the Hierarchical Gaussian Mixture Framework (HGMF), a probabilistic pruning method for scalable tool invocation. HGMF first maps the user query and all tool descriptions into a unified semantic space. The framework then operates in two stages: it clusters servers using a Gaussian Mixture Model (GMM) and filters them based on the query's likelihood. Subsequently, it applies the same GMM-based clustering and filtering to the tools associated with the selected servers. This hierarchical process produces a compact, high-relevance candidate set, simplifying the final selection task for the LLM. Experiments on a public dataset show that HGMF significantly improves tool selection accuracy while reducing inference latency, confirming the framework's scalability and effectiveness for large-scale tool libraries.
UW-3DGS: Underwater 3D Reconstruction with Physics-Aware Gaussian Splatting
Aug 08, 2025Underwater 3D scene reconstruction faces severe challenges from light absorption, scattering, and turbidity, which degrade geometry and color fidelity in traditional methods like Neural Radiance Fields (NeRF). While NeRF extensions such as SeaThru-NeRF incorporate physics-based models, their MLP reliance limits efficiency and spatial resolution in hazy environments. We introduce UW-3DGS, a novel framework adapting 3D Gaussian Splatting (3DGS) for robust underwater reconstruction. Key innovations include: (1) a plug-and-play learnable underwater image formation module using voxel-based regression for spatially varying attenuation and backscatter; and (2) a Physics-Aware Uncertainty Pruning (PAUP) branch that adaptively removes noisy floating Gaussians via uncertainty scoring, ensuring artifact-free geometry. The pipeline operates in training and rendering stages. During training, noisy Gaussians are optimized end-to-end with underwater parameters, guided by PAUP pruning and scattering modeling. In rendering, refined Gaussians produce clean Unattenuated Radiance Images (URIs) free from media effects, while learned physics enable realistic Underwater Images (UWIs) with accurate light transport. Experiments on SeaThru-NeRF and UWBundle datasets show superior performance, achieving PSNR of 27.604, SSIM of 0.868, and LPIPS of 0.104 on SeaThru-NeRF, with ~65% reduction in floating artifacts.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Direct Behavior Optimization: Unlocking the Potential of Lightweight LLMs
Jun 06, 2025Lightweight Large Language Models (LwLLMs) are reduced-parameter, optimized models designed to run efficiently on consumer-grade hardware, offering significant advantages in resource efficiency, cost-effectiveness, and data privacy. However, these models often struggle with limited inference and reasoning capabilities, which restrict their performance on complex tasks and limit their practical applicability. Moreover, existing prompt optimization methods typically rely on extensive manual effort or the meta-cognitive abilities of state-of-the-art LLMs, making them less effective for LwLLMs. To address these challenges, we introduce DeBoP, a new Direct Behavior Optimization Paradigm, original from the Chain-of-Thought (CoT) prompting technique. Unlike CoT Prompting, DeBoP is an automatic optimization method, which focuses on the optimization directly on the behavior of LwLLMs. In particular, DeBoP transforms the optimization of complex prompts into the optimization of discrete, quantifiable execution sequences using a gradient-free Monte Carlo Tree Search. We evaluate DeBoP on seven challenging tasks where state-of-the-art LLMs excel but LwLLMs generally underperform. Experimental results demonstrate that DeBoP significantly outperforms recent prompt optimization methods on most tasks. In particular, DeBoP-optimized LwLLMs surpass GPT-3.5 on most tasks while reducing computational time by approximately 60% compared to other automatic prompt optimization methods.
NeuRel-Attack: Neuron Relearning for Safety Disalignment in Large Language Models
Apr 29, 2025Safety alignment in large language models (LLMs) is achieved through fine-tuning mechanisms that regulate neuron activations to suppress harmful content. In this work, we propose a novel approach to induce disalignment by identifying and modifying the neurons responsible for safety constraints. Our method consists of three key steps: Neuron Activation Analysis, where we examine activation patterns in response to harmful and harmless prompts to detect neurons that are critical for distinguishing between harmful and harmless inputs; Similarity-Based Neuron Identification, which systematically locates the neurons responsible for safe alignment; and Neuron Relearning for Safety Removal, where we fine-tune these selected neurons to restore the model's ability to generate previously restricted responses. Experimental results demonstrate that our method effectively removes safety constraints with minimal fine-tuning, highlighting a critical vulnerability in current alignment techniques. Our findings underscore the need for robust defenses against adversarial fine-tuning attacks on LLMs.
Figure it Out: Analyzing-based Jailbreak Attack on Large Language Models
Jul 23, 2024



The rapid development of Large Language Models (LLMs) has brought remarkable generative capabilities across diverse tasks. However, despite the impressive achievements, these models still have numerous security vulnerabilities, particularly when faced with jailbreak attacks. Therefore, by investigating jailbreak attacks, we can uncover hidden weaknesses in LLMs and guide us in developing more robust defense mechanisms to fortify their security. In this paper, we further explore the boundary of jailbreak attacks on LLMs and propose Analyzing-based Jailbreak (ABJ). This effective jailbreak attack method takes advantage of LLMs' growing analyzing and reasoning capability and reveals their underlying vulnerabilities when facing analysis-based tasks. We conduct a detailed evaluation of ABJ across various open-source and closed-source LLMs, which achieves 94.8% Attack Success Rate (ASR) and 1.06 Attack Efficiency (AE) on GPT-4-turbo-0409, demonstrating state-of-the-art attack effectiveness and efficiency. Our research highlights the importance of prioritizing and enhancing the safety of LLMs to mitigate the risks of misuse.
A Survey of Privacy Threats and Defense in Vertical Federated Learning: From Model Life Cycle Perspective
Feb 06, 2024Vertical Federated Learning (VFL) is a federated learning paradigm where multiple participants, who share the same set of samples but hold different features, jointly train machine learning models. Although VFL enables collaborative machine learning without sharing raw data, it is still susceptible to various privacy threats. In this paper, we conduct the first comprehensive survey of the state-of-the-art in privacy attacks and defenses in VFL. We provide taxonomies for both attacks and defenses, based on their characterizations, and discuss open challenges and future research directions. Specifically, our discussion is structured around the model's life cycle, by delving into the privacy threats encountered during different stages of machine learning and their corresponding countermeasures. This survey not only serves as a resource for the research community but also offers clear guidance and actionable insights for practitioners to safeguard data privacy throughout the model's life cycle.
Rethinking the Defense Against Free-rider Attack From the Perspective of Model Weight Evolving Frequency
Jun 11, 2022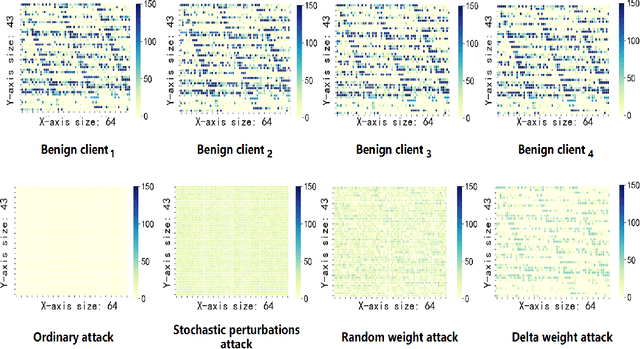
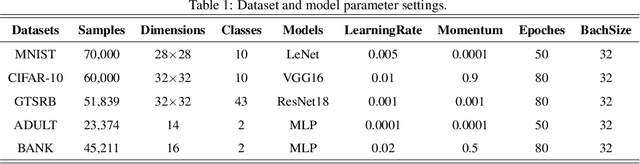
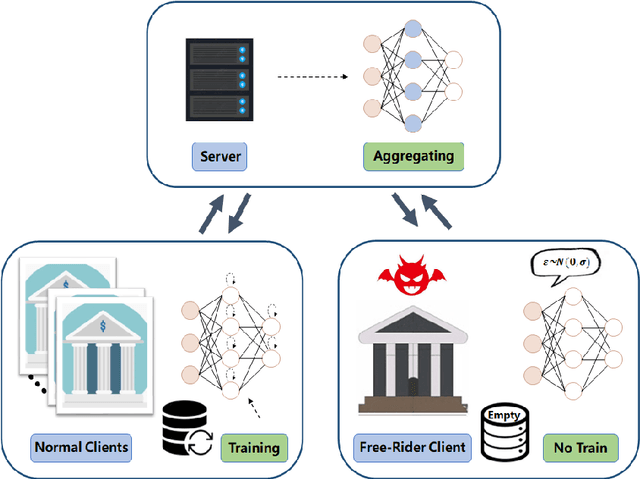
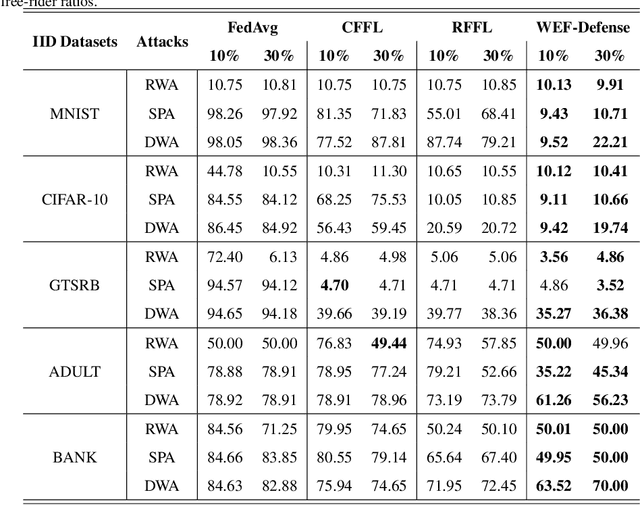
Federated learning (FL) is a distributed machine learning approach where multiple clients collaboratively train a joint model without exchanging their data. Despite FL's unprecedented success in data privacy-preserving, its vulnerability to free-rider attacks has attracted increasing attention. Existing defenses may be ineffective against highly camouflaged or high percentages of free riders. To address these challenges, we reconsider the defense from a novel perspective, i.e., model weight evolving frequency.Empirically, we gain a novel insight that during the FL's training, the model weight evolving frequency of free-riders and that of benign clients are significantly different. Inspired by this insight, we propose a novel defense method based on the model Weight Evolving Frequency, referred to as WEF-Defense.Specifically, we first collect the weight evolving frequency (defined as WEF-Matrix) during local training. For each client, it uploads the local model's WEF-Matrix to the server together with its model weight for each iteration. The server then separates free-riders from benign clients based on the difference in the WEF-Matrix. Finally, the server uses a personalized approach to provide different global models for corresponding clients. Comprehensive experiments conducted on five datasets and five models demonstrate that WEF-Defense achieves better defense effectiveness than the state-of-the-art baselines.