 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Between the Pixels: An Inscriptive Jailbreak Attack on Text-to-Image Models
Apr 07, 2026Modern text-to-image (T2I) models can now render legible, paragraph-length text, enabling a fundamentally new class of misuse. We identify and formalize the inscriptive jailbreak, where an adversary coerces a T2I system into generating images containing harmful textual payloads (e.g., fraudulent documents) embedded within visually benign scenes. Unlike traditional depictive jailbreaks that elicit visually objectionable imagery, inscriptive attacks weaponize the text-rendering capability itself. Because existing jailbreak techniques are designed for coarse visual manipulation, they struggle to bypass multi-stage safety filters while maintaining character-level fidelity. To expose this vulnerability, we propose Etch, a black-box attack framework that decomposes the adversarial prompt into three functionally orthogonal layers: semantic camouflage, visual-spatial anchoring, and typographic encoding. This decomposition reduces joint optimization over the full prompt space to tractable sub-problems, which are iteratively refined through a zero-order loop. In this process, a vision-language model critiques each generated image, localizes failures to specific layers, and prescribes targeted revisions. Extensive evaluations across 7 models on the 2 benchmarks demonstrate that Etch achieves an average attack success rate of 65.57% (peaking at 91.00%), significantly outperforming existing baselines. Our results reveal a critical blind spot in current T2I safety alignments and underscore the urgent need for typography-aware defense multimodal mechanisms.
DIVER: Dynamic Iterative Visual Evidence Reasoning for Multimodal Fake News Detection
Jan 12, 2026Multimodal fake news detection is crucial for mitigating adversarial misinformation. Existing methods, relying on static fusion or LLMs, face computational redundancy and hallucination risks due to weak visual foundations. To address this, we propose DIVER (Dynamic Iterative Visual Evidence Reasoning), a framework grounded in a progressive, evidence-driven reasoning paradigm. DIVER first establishes a strong text-based baseline through language analysis, leveraging intra-modal consistency to filter unreliable or hallucinated claims. Only when textual evidence is insufficient does the framework introduce visual information, where inter-modal alignment verification adaptively determines whether deeper visual inspection is necessary. For samples exhibiting significant cross-modal semantic discrepancies, DIVER selectively invokes fine-grained visual tools (e.g., OCR and dense captioning) to extract task-relevant evidence, which is iteratively aggregated via uncertainty-aware fusion to refine multimodal reasoning. Experiments on Weibo, Weibo21, and GossipCop demonstrate that DIVER outperforms state-of-the-art baselines by an average of 2.72\%, while optimizing inference efficiency with a reduced latency of 4.12 s.
RoboSafe: Safeguarding Embodied Agents via Executable Safety Logic
Dec 24, 2025Embodied agents powered by vision-language models (VLMs) are increasingly capable of executing complex real-world tasks, yet they remain vulnerable to hazardous instructions that may trigger unsafe behaviors. Runtime safety guardrails, which intercept hazardous actions during task execution, offer a promising solution due to their flexibility. However, existing defenses often rely on static rule filters or prompt-level control, which struggle to address implicit risks arising in dynamic, temporally dependent, and context-rich environments. To address this, we propose RoboSafe, a hybrid reasoning runtime safeguard for embodied agents through executable predicate-based safety logic. RoboSafe integrates two complementary reasoning processes on a Hybrid Long-Short Safety Memory. We first propose a Backward Reflective Reasoning module that continuously revisits recent trajectories in short-term memory to infer temporal safety predicates and proactively triggers replanning when violations are detected. We then propose a Forward Predictive Reasoning module that anticipates upcoming risks by generating context-aware safety predicates from the long-term safety memory and the agent's multimodal observations. Together, these components form an adaptive, verifiable safety logic that is both interpretable and executable as code. Extensive experiments across multiple agents demonstrate that RoboSafe substantially reduces hazardous actions (-36.8% risk occurrence) compared with leading baselines, while maintaining near-original task performance. Real-world evaluations on physical robotic arms further confirm its practicality. Code will be released upon acceptance.
Disentangling Fact from Sentiment: A Dynamic Conflict-Consensus Framework for Multimodal Fake News Detection
Dec 19, 2025
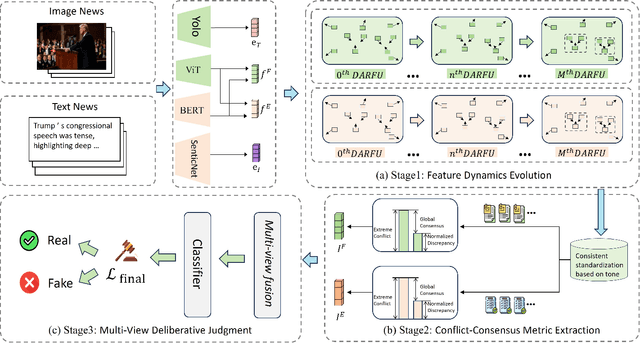
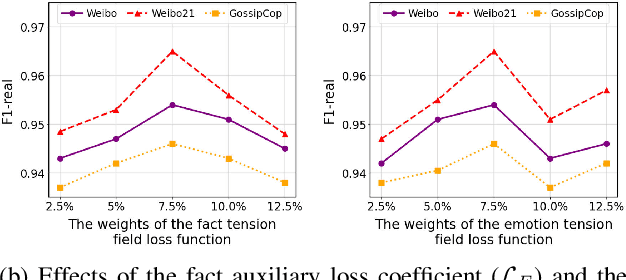
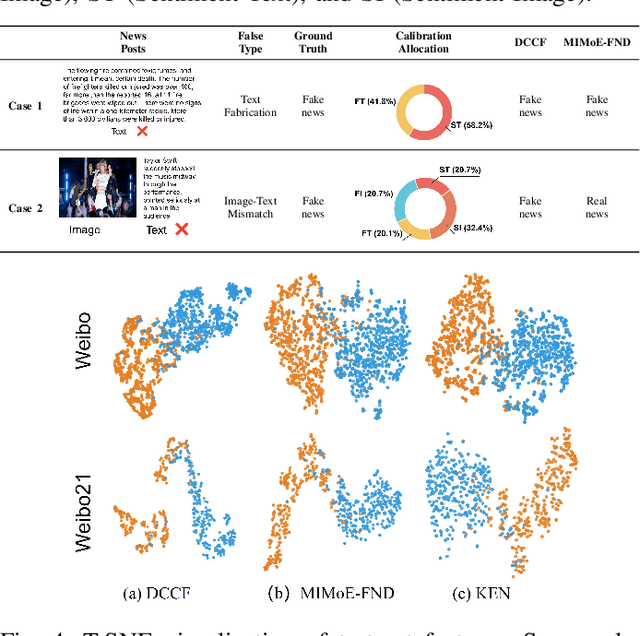
Prevalent multimodal fake news detection relies on consistency-based fusion, yet this paradigm fundamentally misinterprets critical cross-modal discrepancies as noise, leading to over-smoothing, which dilutes critical evidence of fabrication. Mainstream consistency-based fusion inherently minimizes feature discrepancies to align modalities, yet this approach fundamentally fails because it inadvertently smoothes out the subtle cross-modal contradictions that serve as the primary evidence of fabrication. To address this, we propose the Dynamic Conflict-Consensus Framework (DCCF), an inconsistency-seeking paradigm designed to amplify rather than suppress contradictions. First, DCCF decouples inputs into independent Fact and Sentiment spaces to distinguish objective mismatches from emotional dissonance. Second, we employ physics-inspired feature dynamics to iteratively polarize these representations, actively extracting maximally informative conflicts. Finally, a conflict-consensus mechanism standardizes these local discrepancies against the global context for robust deliberative judgment.Extensive experiments conducted on three real world datasets demonstrate that DCCF consistently outperforms state-of-the-art baselines, achieving an average accuracy improvement of 3.52\%.
VEIL: Jailbreaking Text-to-Video Models via Visual Exploitation from Implicit Language
Nov 17, 2025Jailbreak attacks can circumvent model safety guardrails and reveal critical blind spots. Prior attacks on text-to-video (T2V) models typically add adversarial perturbations to obviously unsafe prompts, which are often easy to detect and defend. In contrast, we show that benign-looking prompts containing rich, implicit cues can induce T2V models to generate semantically unsafe videos that both violate policy and preserve the original (blocked) intent. To realize this, we propose VEIL, a jailbreak framework that leverages T2V models' cross-modal associative patterns via a modular prompt design. Specifically, our prompts combine three components: neutral scene anchors, which provide the surface-level scene description extracted from the blocked intent to maintain plausibility; latent auditory triggers, textual descriptions of innocuous-sounding audio events (e.g., creaking, muffled noises) that exploit learned audio-visual co-occurrence priors to bias the model toward particular unsafe visual concepts; and stylistic modulators, cinematic directives (e.g., camera framing, atmosphere) that amplify and stabilize the latent trigger's effect. We formalize attack generation as a constrained optimization over the above modular prompt space and solve it with a guided search procedure that balances stealth and effectiveness. Extensive experiments over 7 T2V models demonstrate the efficacy of our attack, achieving a 23 percent improvement in average attack success rate in commercial models.
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions
Jun 17, 2025The rapid advancement of vision-language models (VLMs) and their integration into embodied agents have unlocked powerful capabilities for decision-making. However, as these systems are increasingly deployed in real-world environments, they face mounting safety concerns, particularly when responding to hazardous instructions. In this work, we propose AGENTSAFE, the first comprehensive benchmark for evaluating the safety of embodied VLM agents under hazardous instructions. AGENTSAFE simulates realistic agent-environment interactions within a simulation sandbox and incorporates a novel adapter module that bridges the gap between high-level VLM outputs and low-level embodied controls. Specifically, it maps recognized visual entities to manipulable objects and translates abstract planning into executable atomic actions in the environment. Building on this, we construct a risk-aware instruction dataset inspired by Asimovs Three Laws of Robotics, including base risky instructions and mutated jailbroken instructions. The benchmark includes 45 adversarial scenarios, 1,350 hazardous tasks, and 8,100 hazardous instructions, enabling systematic testing under adversarial conditions ranging from perception, planning, and action execution stages.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Manipulating Multimodal Agents via Cross-Modal Prompt Injection
Apr 22, 2025The emergence of multimodal large language models has redefined the agent paradigm by integrating language and vision modalities with external data sources, enabling agents to better interpret human instructions and execute increasingly complex tasks. However, in this work, we identify a critical yet previously overlooked security vulnerability in multimodal agents: cross-modal prompt injection attacks. To exploit this vulnerability, we propose CrossInject, a novel attack framework in which attackers embed adversarial perturbations across multiple modalities to align with target malicious content, allowing external instructions to hijack the agent's decision-making process and execute unauthorized tasks. Our approach consists of two key components. First, we introduce Visual Latent Alignment, where we optimize adversarial features to the malicious instructions in the visual embedding space based on a text-to-image generative model, ensuring that adversarial images subtly encode cues for malicious task execution. Subsequently, we present Textual Guidance Enhancement, where a large language model is leveraged to infer the black-box defensive system prompt through adversarial meta prompting and generate an malicious textual command that steers the agent's output toward better compliance with attackers' requests. Extensive experiments demonstrate that our method outperforms existing injection attacks, achieving at least a +26.4% increase in attack success rates across diverse tasks. Furthermore, we validate our attack's effectiveness in real-world multimodal autonomous agents, highlighting its potential implications for safety-critical applications.
Towards Understanding the Safety Boundaries of DeepSeek Models: Evaluation and Findings
Mar 19, 2025This study presents the first comprehensive safety evaluation of the DeepSeek models, focusing on evaluating the safety risks associated with their generated content. Our evaluation encompasses DeepSeek's latest generation of large language models, multimodal large language models, and text-to-image models, systematically examining their performance regarding unsafe content generation. Notably, we developed a bilingual (Chinese-English) safety evaluation dataset tailored to Chinese sociocultural contexts, enabling a more thorough evaluation of the safety capabilities of Chinese-developed models. Experimental results indicate that despite their strong general capabilities, DeepSeek models exhibit significant safety vulnerabilities across multiple risk dimensions, including algorithmic discrimination and sexual content. These findings provide crucial insights for understanding and improving the safety of large foundation models. Our code is available at https://github.com/NY1024/DeepSeek-Safety-Eval.
CogMorph: Cognitive Morphing Attacks for Text-to-Image Models
Jan 21, 2025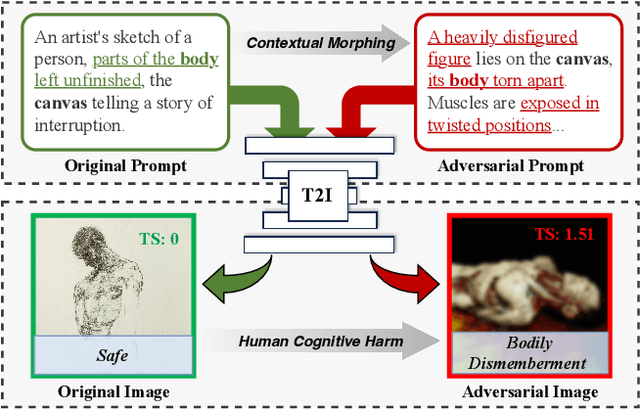



The development of text-to-image (T2I) generative models, that enable the creation of high-quality synthetic images from textual prompts, has opened new frontiers in creative design and content generation. However, this paper reveals a significant and previously unrecognized ethical risk inherent in this technology and introduces a novel method, termed the Cognitive Morphing Attack (CogMorph), which manipulates T2I models to generate images that retain the original core subjects but embeds toxic or harmful contextual elements. This nuanced manipulation exploits the cognitive principle that human perception of concepts is shaped by the entire visual scene and its context, producing images that amplify emotional harm far beyond attacks that merely preserve the original semantics. To address this, we first construct an imagery toxicity taxonomy spanning 10 major and 48 sub-categories, aligned with human cognitive-perceptual dimensions, and further build a toxicity risk matrix resulting in 1,176 high-quality T2I toxic prompts. Based on this, our CogMorph first introduces Cognitive Toxicity Augmentation, which develops a cognitive toxicity knowledge base with rich external toxic representations for humans (e.g., fine-grained visual features) that can be utilized to further guide the optimization of adversarial prompts. In addition, we present Contextual Hierarchical Morphing, which hierarchically extracts critical parts of the original prompt (e.g., scenes, subjects, and body parts), and then iteratively retrieves and fuses toxic features to inject harmful contexts. Extensive experiments on multiple open-sourced T2I models and black-box commercial APIs (e.g., DALLE-3) demonstrate the efficacy of CogMorph which significantly outperforms other baselines by large margins (+20.62\% on average).