 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Safety Boundaries of DeepSeek Models: Evaluation and Findings
Mar 19, 2025This study presents the first comprehensive safety evaluation of the DeepSeek models, focusing on evaluating the safety risks associated with their generated content. Our evaluation encompasses DeepSeek's latest generation of large language models, multimodal large language models, and text-to-image models, systematically examining their performance regarding unsafe content generation. Notably, we developed a bilingual (Chinese-English) safety evaluation dataset tailored to Chinese sociocultural contexts, enabling a more thorough evaluation of the safety capabilities of Chinese-developed models. Experimental results indicate that despite their strong general capabilities, DeepSeek models exhibit significant safety vulnerabilities across multiple risk dimensions, including algorithmic discrimination and sexual content. These findings provide crucial insights for understanding and improving the safety of large foundation models. Our code is available at https://github.com/NY1024/DeepSeek-Safety-Eval.
NotaGen: Advancing Musicality in Symbolic Music Generation with Large Language Model Training Paradigms
Feb 26, 2025We introduce NotaGen, a symbolic music generation model aiming to explore the potential of producing high-quality classical sheet music. Inspired by the success of Large Language Models (LLMs), NotaGen adopts pre-training, fine-tuning, and reinforcement learning paradigms (henceforth referred to as the LLM training paradigms). It is pre-trained on 1.6M pieces of music, and then fine-tuned on approximately 9K high-quality classical compositions conditioned on "period-composer-instrumentation" prompts. For reinforcement learning, we propose the CLaMP-DPO method, which further enhances generation quality and controllability without requiring human annotations or predefined rewards. Our experiments demonstrate the efficacy of CLaMP-DPO in symbolic music generation models with different architectures and encoding schemes. Furthermore, subjective A/B tests show that NotaGen outperforms baseline models against human compositions, greatly advancing musical aesthetics in symbolic music generation. The project homepage is https://electricalexis.github.io/notagen-demo.
Modular Sentence Encoders: Separating Language Specialization from Cross-Lingual Alignment
Jul 20, 2024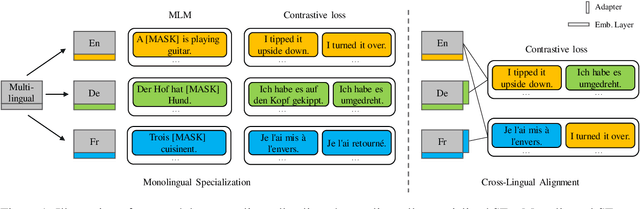
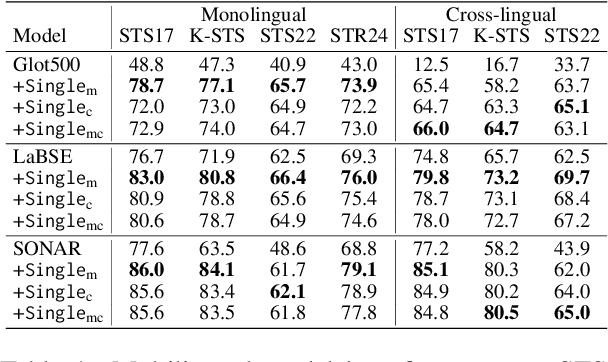

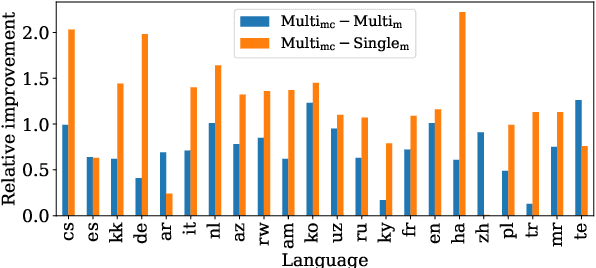
Multilingual sentence encoders are commonly obtained by training multilingual language models to map sentences from different languages into a shared semantic space. As such, they are subject to curse of multilinguality, a loss of monolingual representational accuracy due to parameter sharing. Another limitation of multilingual sentence encoders is the trade-off between monolingual and cross-lingual performance. Training for cross-lingual alignment of sentence embeddings distorts the optimal monolingual structure of semantic spaces of individual languages, harming the utility of sentence embeddings in monolingual tasks. In this work, we address both issues by modular training of sentence encoders, i.e., by separating monolingual specialization from cross-lingual alignment. We first efficiently train language-specific sentence encoders to avoid negative interference between languages (i.e., the curse). We then align all non-English monolingual encoders to the English encoder by training a cross-lingual alignment adapter on top of each, preventing interference with monolingual specialization from the first step. In both steps, we resort to contrastive learning on machine-translated paraphrase data. Monolingual and cross-lingual evaluations on semantic text similarity/relatedness and multiple-choice QA render our modular solution more effective than multilingual sentence encoders, especially benefiting low-resource languages.
AdaSent: Efficient Domain-Adapted Sentence Embeddings for Few-Shot Classification
Nov 01, 2023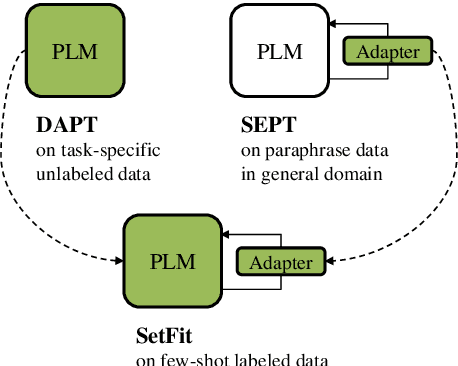

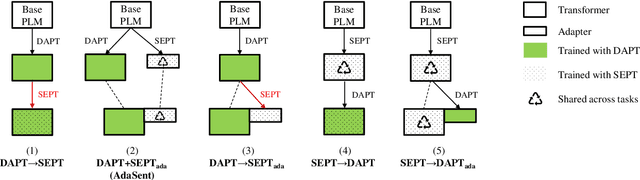
Recent work has found that few-shot sentence classification based on pre-trained Sentence Encoders (SEs) is efficient, robust, and effective. In this work, we investigate strategies for domain-specialization in the context of few-shot sentence classification with SEs. We first establish that unsupervised Domain-Adaptive Pre-Training (DAPT) of a base Pre-trained Language Model (PLM) (i.e., not an SE) substantially improves the accuracy of few-shot sentence classification by up to 8.4 points. However, applying DAPT on SEs, on the one hand, disrupts the effects of their (general-domain) Sentence Embedding Pre-Training (SEPT). On the other hand, applying general-domain SEPT on top of a domain-adapted base PLM (i.e., after DAPT) is effective but inefficient, since the computationally expensive SEPT needs to be executed on top of a DAPT-ed PLM of each domain. As a solution, we propose AdaSent, which decouples SEPT from DAPT by training a SEPT adapter on the base PLM. The adapter can be inserted into DAPT-ed PLMs from any domain. We demonstrate AdaSent's effectiveness in extensive experiments on 17 different few-shot sentence classification datasets. AdaSent matches or surpasses the performance of full SEPT on DAPT-ed PLM, while substantially reducing the training costs. The code for AdaSent is available.